RAG (Retrieval-Augmented Generation) is a powerful technique that enhances the capabilities of Large Language Models (LLMs) like GPT-4. While LLMs excel at generating text, they often lack context and struggle to understand the deeper meaning behind user queries. RAG bridges this gap by incorporating information retrieval to provide LLMs with relevant context, leading to improved response quality.
1. How does RAG work?
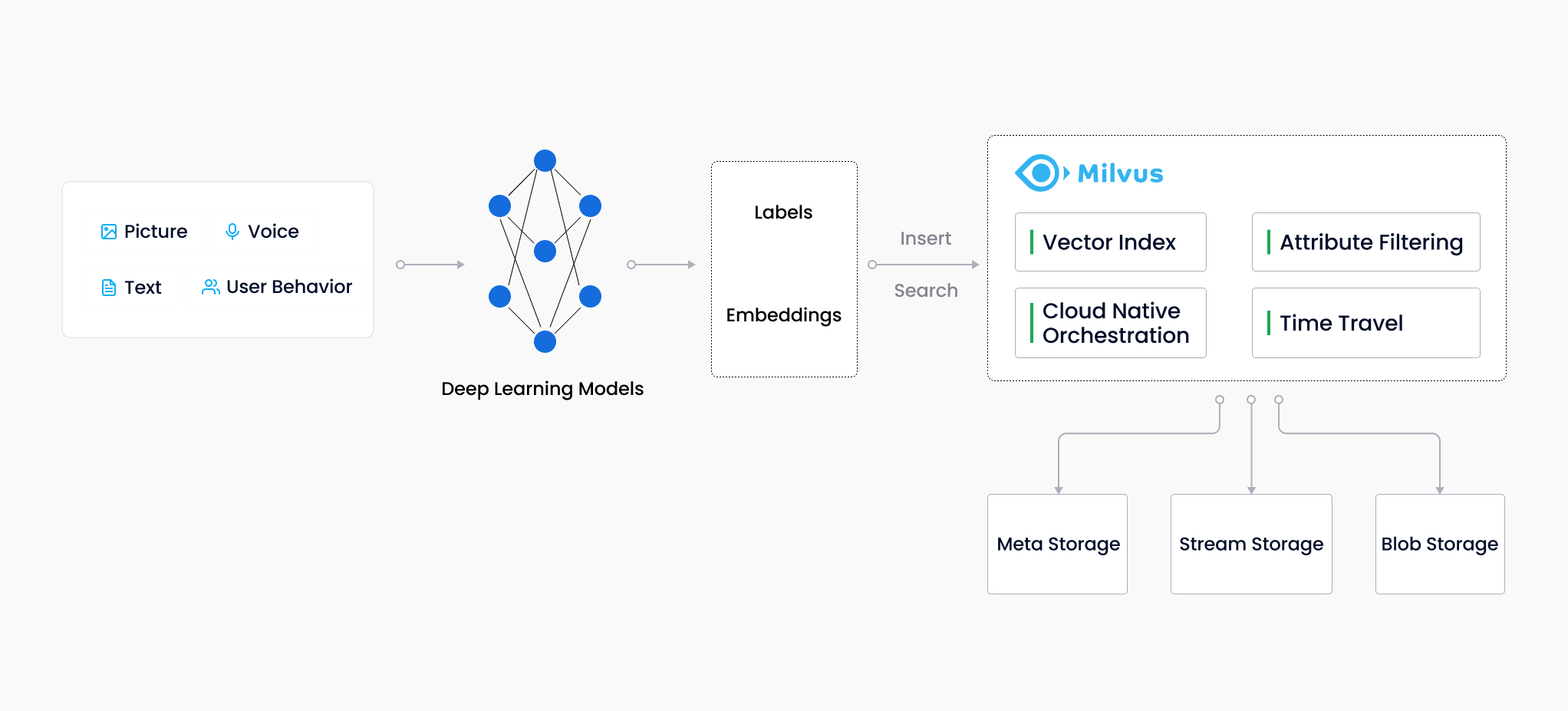
RAG is a pattern which uses your data with an LLM to generate answers specific to your data. When a user asks a question, the data store is searched based on user input. The user question is then combined with the matching results and sent to the LLM using a prompt (explicit instructions to an AI or machine learning model) to generate the desired answer. This can be illustrated as follows. [1]
-
User Input: The user provides a query or prompt.
-
Vector Search: A vector database (like Milvus) efficiently retrieves documents or passages most relevant to the user’s query based on semantic similarity.
-
Context Enrichment: Techniques like summarization, keyphrase extraction, or entity recognition are applied to the retrieved information, providing context for the LLM.
-
Prompt Construction: The user’s original query is combined with the extracted context to form a new, enriched prompt for the LLM.
-
Enhanced Generation: The LLM leverages the enriched prompt to generate a more informative and relevant response that addresses the user’s specific intent and considers the retrieved context.
While Milvus and GPT-like LLMs are key players, consider these additional aspects for a well-rounded RAG system:
-
Machine Learning Fundamentals: Understanding concepts like word embeddings and information retrieval is crucial.
-
Alternative Tools: Explore other vector databases and pre-trained word embedding models.
-
Prompt Construction Techniques: Utilize template-based prompts, conditional logic, or fine-tuning for automatic prompt generation.
-
Evaluation: Continuously monitor performance to identify areas for improvement.
In essence, RAG empowers LLMs to become more contextually aware, leading to a more informative and engaging user experience.
2. Deep Dive into Context Enrichment for RAG Systems
Context enrichment is a crucial step in RAG (Retrieval-Augmented Generation) that bridges the gap between a user’s query and the LLM’s response. It involves processing the information retrieved from the vector database (like Milvus) to provide the LLM with a deeper understanding of the user’s intent and the relevant context.
Here’s a breakdown of some popular libraries and techniques for context enrichment:
-
Text Summarization:
-
Goal: Condense retrieved documents into concise summaries for the LLM to grasp the key points.
-
Libraries:
-
Gensim (Python): Offers various summarization techniques, including extractive (selecting important sentences) and abstractive (generating a new summary).
-
BART (Transformers library): A powerful pre-trained model specifically designed for text summarization.
-
-
-
Keyword Extraction:
-
Goal: Identify the most relevant keywords or keyphrases within retrieved documents to highlight the main themes.
-
Libraries:
-
spaCy (Python): Provides functionalities for part-of-speech tagging, named entity recognition, and keyword extraction.
-
NLTK (Python): A comprehensive toolkit for various NLP tasks, including keyword extraction using techniques like TF-IDF (Term Frequency-Inverse Document Frequency).
-
-
-
Named Entity Recognition (NER):
-
Goal: Recognize and classify named entities (people, locations, organizations) within retrieved text, enriching the context for the LLM.
-
Libraries:
-
spaCy: Offers pre-trained NER models for various languages, allowing the LLM to understand the context of specific entities.
-
Stanford NER: A widely used Java-based library for named entity recognition.
-
-
Choosing the Right Technique:
The best approach for context enrichment depends on your specific needs and the type of data you’re working with. Here’s a quick guide:
-
For factual or informative responses: Text summarization can be highly effective.
-
For understanding the main topics: Keyword extraction is a good choice.
-
For tasks involving specific entities: Named entity recognition becomes crucial.
Advanced Techniques:
-
Combining Techniques: Don’t be limited to a single approach. Combine summarization with keyword extraction or NER to provide richer context to the LLM.
-
Custom Summarization Models: For specialized domains, consider training custom summarization models using domain-specific data.
3. Automatic Prompt Construction
Several approaches can automate prompt construction based on user input and extracted context:
-
Template-Based Prompts: Pre-defined templates can be used to structure the prompt, incorporating user query and extracted elements (e.g., "{user_query}: Based on similar content, here are some key points: {key_phrases}. Can you elaborate?").
-
Conditional Logic: Conditional statements can be used based on the chosen context enrichment technique. For example, if using summaries, the prompt might say "Here’s a summary of relevant information…" while using keyphrases, it might mention "Here are some key points…"
-
Fine-tuning Language Models: Techniques like fine-tuning pre-trained LLMs can be explored to allow them to automatically learn how to integrate user queries and retrieved context into a cohesive prompt. This is an advanced approach requiring expertise in machine learning.
Choosing the Right Tool:
The best tool or approach depends on your specific needs and available resources. Here’s a basic guideline:
-
Simpler Systems: For less complex RAG systems, template-based prompts with basic summarization or keyword extraction tools might suffice.
-
Advanced Systems: For more sophisticated applications, consider exploring conditional logic, fine-tuning LLMs, or combining different context enrichment techniques to create richer prompts.
By combining vector databases with the right context enrichment tools and automatic prompt construction techniques, we can build a robust RAG system that leverages the power of LLMs to generate more informative and relevant responses.
4. Build RAG with Milvus
We will use Phi-3, an open small language model, to provide an OpenAI-compatible API.
|
Prepare the Phi3 LLM with Ollama on Linux
|
4.1. Prepare the data in Milvus
-
Dependencies and Environment
pip install --upgrade 'pymilvus[model]==2.4.4' 'numpy<2' openai requests # pipenv install -v 'pymilvus[model]==2.4.4' 'numpy<2' openai requests -
Prepare the embedding model
from pymilvus.model.dense import SentenceTransformerEmbeddingFunction # Sentence Transformer pre-trained models # If connection to https://huggingface.co/ failed, uncomment the following path # import os # os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' ef = SentenceTransformerEmbeddingFunction( model_name='all-MiniLM-L6-v2', # Specify the model name ) -
Create the collection in Milvus
from pymilvus import MilvusClient, DataType COLLECTION_NAME = "my_rag_collection" SERVER_ADDR = "http://localhost:19530" ACCESS_TOKEN = "root:Milvus" DB_NAME = "default" # 1. Set up a Milvus client client = MilvusClient( uri=SERVER_ADDR, token=ACCESS_TOKEN, db_name=DB_NAME, ) # 2. Check if the collection already exists and drop it if it does. if client.has_collection(COLLECTION_NAME): client.drop_collection(COLLECTION_NAME) # 3. Create a new collection with specified parameters. client.create_collection( collection_name=COLLECTION_NAME, dimension=384, # The vector has 384 dimensions, matching the SBERT embedding function with all-MiniLM-L6-v2 auto_id=True, # default is False # primary_field_name="id", # id_type="int", # vector_field_name="vector", # metric_type="COSINE", # enable_dynamic_field=True, ) # 4. (optional) To load a collection, use the load_collection() method. # client.load_collection( # collection_name=COLLECTION_NAME # ) # # To release a collection, use the release_collection() method. # client.release_collection( # collection_name=COLLECTION_NAME # ) # 5. (optional) The collection created above is loaded automatically. res = client.get_load_state( collection_name=COLLECTION_NAME ) print(res) # 6. (optional) List detailed information about the collection. import json desc = client.describe_collection( collection_name=COLLECTION_NAME, ) print(json.dumps(desc, indent=2)){'state': <LoadState: Loaded>} { "collection_name": "my_rag_collection", "auto_id": true, "num_shards": 1, "description": "", "fields": [ { "field_id": 100, "name": "id", "description": "", "type": 5, "params": {}, "auto_id": true, "is_primary": true }, { "field_id": 101, "name": "vector", "description": "", "type": 101, "params": { "dim": 384 } } ], "aliases": [], "collection_id": 450568843972908135, "consistency_level": 2, "properties": {}, "num_partitions": 1, "enable_dynamic_field": true } -
Use the Milvus development guide to be as the private knowledge in our RAG, which is a good data source for a simple RAG pipeline.
# download and save it as a local text file. import os import urllib.request URL = "https://raw.githubusercontent.com/milvus-io/milvus/master/DEVELOPMENT.md" FILE_PATH = "./Milvus_DEVELOPMENT.md1" if not os.path.exists(FILE_PATH): urllib.request.urlretrieve(URL, FILE_PATH) -
Create embeddings, and then insert the data into Milvus
from pymilvus import MilvusClient, model COLLECTION_NAME = "my_rag_collection" SERVER_ADDR = "http://localhost:19530" ACCESS_TOKEN = "root:Milvus" DB_NAME = "default" client = MilvusClient( uri=SERVER_ADDR, token=ACCESS_TOKEN, db_name=DB_NAME, ) # If connection to https://huggingface.co/ failed, uncomment the following path # import os # os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' ef = model.dense.SentenceTransformerEmbeddingFunction( model_name='all-MiniLM-L6-v2', ) FILE_PATH = "./Milvus_DEVELOPMENT.md" with open(FILE_PATH, "r+t", encoding='utf-8') as fi: text = fi.read() # Use "# " to separate the content in the file, which can roughly separate # the content of each main part of the markdown file. docs = text.split("# ") vectors = ef.encode_documents(docs) data = [{"vector": vectors[i], "text": docs[i]} for i in range(len(vectors))] res = client.insert(collection_name=COLLECTION_NAME, data=data) print(res){'insert_count': 47, 'ids': [450568843971283844, ... , 450568843971283889, 450568843971283890], 'cost': 0}
4.2. Use LLM to get a RAG response
from openai import OpenAI
from pymilvus import MilvusClient, model
COLLECTION_NAME = "my_rag_collection"
SERVER_ADDR = "http://localhost:19530"
ACCESS_TOKEN = "root:Milvus"
DB_NAME = "default"
client = MilvusClient(
uri=SERVER_ADDR,
token=ACCESS_TOKEN,
db_name=DB_NAME,
)
# If connection to https://huggingface.co/ failed, uncomment the following path
# import os
# os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
ef = model.dense.SentenceTransformerEmbeddingFunction(
model_name='all-MiniLM-L6-v2',
)
# Define a query question about the content of the development guide documentation.
question = "what is the hardware requirements specification if I want to build Milvus and run from source code?"
# Search for the question in the collection and retrieve the semantic top-3 matches.
res = client.search(
collection_name=COLLECTION_NAME,
data=ef.encode_queries([question]),
limit=3, # Return top 3 results
output_fields=["text"], # Return the text field
)
retrieved_lines_with_distances = [
(r["entity"]["text"], r["distance"]) for r in res[0]
]
# [
# [
# "Hardware Requirements\n\nThe following specification (either physical or virtual machine resources) is recommended for Milvus to build and run from source code.\n\n```\n- 8GB of RAM\n- 50GB of free disk space\n```\n\n##",
# 0.8904632329940796
# ],
# [
# "Software Requirements\n\nAll Linux distributions are available for Milvus development. However a majority of our contributor worked with Ubuntu or CentOS systems, with a small portion of Mac (both x86_64 and Apple Silicon) contributors. If you would like Milvus to build and run on other distributions, you are more than welcome to file an issue and contribute!\n\nHere's a list of verified OS types where Milvus can successfully build and run:\n\n- Debian/Ubuntu\n- Amazon Linux\n- MacOS (x86_64)\n- MacOS (Apple Silicon)\n\n##",
# 0.7089803814888
# ],
# [
# "Building Milvus on a local OS/shell environment\n\nThe details below outline the hardware and software requirements for building on Linux and MacOS.\n\n##",
# 0.7013456225395203
# ]
# ]
# Convert the retrieved documents into a string format.
context = "\n".join(
[line_with_distance[0]
for line_with_distance in retrieved_lines_with_distances]
)
# Define system and user prompts for the Lanage Model.
SYSTEM_PROMPT = """
Human: You are an AI assistant. You are able to find answers to the questions from the contextual passage snippets provided.
"""
USER_PROMPT = f"""
Use the following pieces of information enclosed in <context> tags to provide an answer to the question enclosed in <question> tags.
<context>
{context}
</context>
<question>
{question}
</question>
"""
# Use OpenAI Chat Completion API to generate a response based on the prompts.
OAI_API_KEY = "EMPTY"
OAI_API_BASE = "http://localhost:11434/v1"
oai_client = OpenAI(
api_key=OAI_API_KEY,
base_url=OAI_API_BASE,
)
response = oai_client.chat.completions.create(
model="phi3:mini",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": USER_PROMPT},
],
)
print(response.choices[0].message.content)The hardware requirements specification for building Milvus and running it from source code includes having at least 8GB of RAM and 50GB of free disk space.