Database index and data structure
Hash table
A hash table (hash map) is a data structure used a hash function to compute an index into an array of buckets or slots.

A small phone book as a hash table
Binary tree
A binary tree is a tree data structure in which each node has at most two children, which are referred to as the left child and the right child.
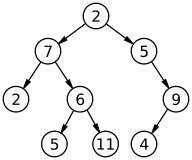
A labeled binary tree of size 9 and height 3, with a root node whose value is 2. The above tree is unbalanced and not sorted.
Binary search tree
The binary search trees (BST), sometimes called ordered or sorted binary trees, are a particular type of binary tree.
Binary search tree keep their keys in sorted order, so that lookup and other operation can use the principle of binary search.
On average, binary search trees with n nodes have O(log n) height. However, in the worst case, binary search trees can have O(n) height, when the unbalanced tree resembles a linked list (degenerate tree).
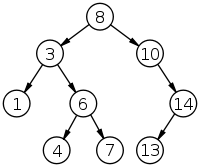
A binary search tree of size 9 and depth 3, with 8 at the root. The leaves are not drawn.
Self-balancing binary search tree
The self-balancing (or height-balanced) binary search tree is any node-based binary search tree that automatically keeps its height (maximal number of levels below the root) small in the face of arbitrary item insertions and deletions.
The red–black tree, which is a type of self-balancing binary search tree, was called symmetric binary B-tree.
![]()
An example of an unbalanced tree; following the path from the root to a node takes an average of 3.27 node accesses
![]()
The same tree after being height-balanced; the average path effort decreased to 3.00 node accesses

Tree rotations are very common internal operations on self-balancing binary trees to keep perfect or near-to-perfect balance.
B-tree
The B-tree is a generalization of a binary search tree in that a node can have more than two children. Unlike self-balancing binary search trees, the B-tree is optimaized for systems that read and write large blocks of data. B-trees are a good example of a data structure for external memory. It is commonly used in databases and filesystems.
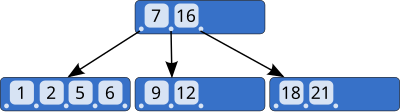
A B-tree (Bayer & McCreight 1972) of order 5 (Knuth 1998).
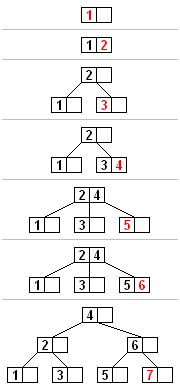
A B Tree insertion example with each iteration. The nodes of this B tree have at most 3 children (Knuth order 3).
B+ tree
A B+ tree can be viewed as a B-tree in which each node contains only keys (not key-values pairs), and to which an additional level is added at the bottom with linked leaves.
The primary value of a B+ tree is in storing data for efficient retrieval in a block-oriented storage context — in particular, filesystems. This is primarily because unlike binary search trees, B+ trees have very high fanout (number of pointers to child nodes in a node, typically on the order of 100 or more), which reduces the number of I/O operations required to find an element in the tree.

A simple B+ tree example linking the keys 1–7 to data values d1-d7. The linked list (red) allows rapid in-order traversal. This particular tree’s branching factor is b=4.
Database index
The best way to improve the performance of SELECT operations is to create indexes on one or more of the columns that are tested in the query.
An index is a copy of select columns of data from a table. Some databases extend the power of indexing by letting developer create indices on fuctions or expressions. For example, an index could be created on upper(last_name), which would only store the upper case versions of the last_name field in the index.
Indexes also add to the cost of inserts, updates, and deletes because each index must be updated.
-
Non-clustered
The data is present in arbitrary order, but the logical ordering is specified by the index. The data row may be spread throughout the table regardless of the value of the indexed column or expression.
In a non-clustered index,
-
The physical order of the rows is not the same as the index order.
-
The indexed columns are typically non-primary key columns used in JOIN, WHERE, and ORDER BY clauses.
There can be more than one non-clustered index on a database table.
-
-
Clustered
Clustering alters the data block into certain distinct order to match the index, resulting in the row data being stored in order.
Clustered indices can greatly increase overall speed of retrieval, but usually only where the data is accessed sequentially in the same or reverse order of the clustered index, or when a range of items is selected.
Only one clustered index can be created on a given database table.
-
Multiple-Column Indexes
The order that the index definition defines the columns in is important.
Databases can use multiple-columns indexes for queries that test all the columns in the index, or queries that test just the first column, the first two columns, the first three columns, and so on.
-
Comparison of B-Tree and Hash Indexes
B-Tree Index
A B-tree index can be used for column comparisons in expressions that use the =,>,>=,<,<=, or BETWEEN operators. The index also can be used for LIKE comparisons if the argument to LIKE is a constant string that does not start with a wildcard character.
The following SELECT statements use indexs:
SELECT * FROM tbl_name WHERE key_col LIKE 'Patrick%';
SELECT * FROM tbl_name WHERE key_col LIKE 'Pat%_ck%';
The following SELECT statements do not use indexes:
SELECT * FROM tbl_name WHERE key_col LIKE '%Patrick%';
SELECT * FROM tbl_name WHERE key_col LIKE other_col;
A search using col_name IS NULL employs indexes if col_name is indexed.
Any index that does not span all AND levels in the WHERE clause is not used to optimize the query. In other words, to be able to use an index, a prefix of the index must be used in every AND group.
The following WHERE clauses use indexes:
... WHERE index_part1=1 AND index_part2=2 AND other_column=3
/* index = 1 OR index = 2 */
... WHERE index=1 OR A=10 AND index=2
/* optimized like "index_part1='hello'" */
... WHERE index_part1='hello' AND index_part3=5
/* Can use index on index1 but not on index2 or index3 */
... WHERE index1=1 AND index2=2 OR index1=3 AND index3=3;
These WHERE clauses do *not* use indexes:
/* index_part1 is not used */
... WHERE index_part2=1 AND index_part3=2
/* Index is not used in both parts of the WHERE clause */
... WHERE index=1 OR A=10
/* No index spans all rows */
... WHERE index_part1=1 OR index_part2=10
Hash Index
-
They are used only for equality comparisons that use the
=or<=>operators (but are very fast). They are not used for comparison operators such as<that find a range of values. Systems that rely on this type of single-value lookup are known as “key-value stores”. -
The optimizer cannot use a hash index to speed up
ORDER BYoperations. (This type of index cannot be used to search for the next entry in order.) -
Only whole keys can be used to search for a row. (With a B-tree index, any leftmost prefix of the key can be used to find rows.)
References
- Database index
- What data structure does mysql use to store data?
- MySQL 5.5 Reference Manual / Optimization / Optimization and Indexes
- Clustered Index Structures
- Hash table
- Wiki: Binary tree
- CMU: Binary Trees
- Binary search tree
- Self-balancing binary search tree
- B-tree
- B+ tree
- Computer Algorithms: Balancing a Binary Search Tree
- Binary search algorithm
- Divide and conquer algorithms