
对于跨多个字节的程序对象,我们必须建立两个规则:这个对象的地址是什么,在存储器中如何排列这些字节。在几乎所有的机器上,多字节对象都被存储为连续的字节序列,对象的地址为所使用字节的最小的地址。例如,假设一个类型为 int 的变量 x 的地址为 0x100,也就是地址表达式 &x 的值为 0x100。那么,x 的 4 字节将被存储在存储器的 0x100、0x101、0x102 和 0x103 位置。
以下是 Jonathan Swift 在 1726 年关于大小端之争历史的描述:
“……我下面要告诉你的是,Lilliput 和 Blefuscu 这两大强国在过去 36 个月里一直在苦战。战争开始是由于以下原因:我们大家认为,吃鸡蛋前,原始的方法是打破鸡蛋较大的一端,可是当今皇帝的祖父小时候吃鸡蛋,一次按古法打鸡蛋时碰巧将一个手指弄破了,因此他的父亲,当时的皇帝,就下了一道敕令,命令全体臣民吃鸡蛋时打破鸡蛋较小的一端,违令着重罚,老百姓们对这项命令极为反感.历史告诉我们,由此曾发生过6此叛乱,其中一个皇帝送了命,另一个丢了王位。这些叛乱大多是由 Blefuscu 的国王大臣们煽动起来的。叛乱平息后,流亡的人总是逃到那个帝国去寻求避难。据估计,先后几次有11 000人情愿受死也不肯去打破鸡蛋较小的一端。关于这一争端,曾出版过几百本大部著作,不过大端派的书一直是受禁的,法律也规定该派的任何人不得做官。”(此段译文摘自网上将剑锋译的《格列佛游记》第一卷第4章。)
在他那个年代,Swift 是在讽刺英国(Lilliput)和法国(Belfuscu)之间持续的冲突。Danny Cohen,一位网络协议的早期开创者,第一次使用这两个术语来指代字节顺序,后来这个术语被广泛接纳了。
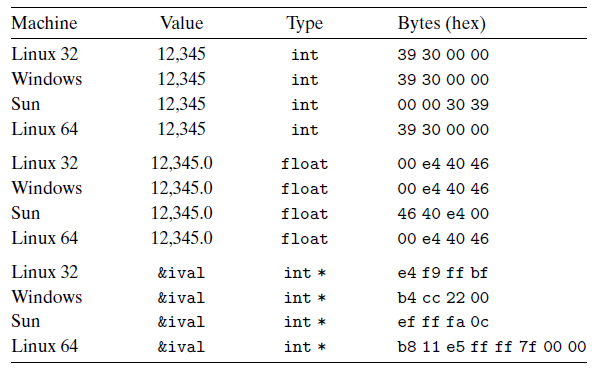
对于大多数应用程序员来说,他们机器所使用的字节顺序是完全不可见的,无论为哪种类型的机器编译的程序都会得到同样的结果。不过有时候,字节顺序会成为问题。首先是在不同类型的机器之间通过网络传送二进制数据时,一个常见的问题是当小端法机器产生的数据被发送到大端法机器或者反方向发送时会发现,接收程序字里的字节成了反序的。为了避免这类问题,网络应用程序的代码编写必须遵守已建立的关于字节顺序的规则,以确保发送机器将它的内部表示转换成网络标准,而接手方机器则将网络标准转换为它的内部表示。
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 1
Core(s) per socket: 1
Socket(s): 4
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 142
Model name: Intel(R) Core(TM) i5-10210U CPU @ 1.60GHz
...|
LSB & MSB
Little-endian (LSB) means we start with the least significant part in the lowest address. Big-endian (MSB) means we start with the most significant part. For example, 16-bit integer 0x1234 would be stored in bytes as 0x12 0x34 (LSB) or 0x34 0x12 (MSB). |