Understanding The Linux Kernel 01
对枯燥的事情有所坚持—耗子
- 1.1 Linux Versus Other Unix-Like Kernels
- 1.2 Hardware Dependency
- 1.3 Linux Versions
- 1.4 Basic Operating System Concepts
- 1.5 An Overview of the Unix Filesystem
- 1.6 An Overview of Unix Kernels
- References
Linux is a member of the large family of Unix-like operating system.
Linux was initially deveoped by Linus Torvalds in 1991 as an operating system for IBM-compatible personal computers based on the Intel 80386 microprocessor.
Technically speaking, Linux is a true Unix kernel, although it is not a full Unix operating system, because it does not include all the applications such as filesystem utilities, windowing systems and graphical desktops, system administrator commands, text editors, compilers, and so on. However, since most of thes programs are freely available under the GNU General Public License, they can be installed into one of the filesytems supported by Linux.
1.1 Linux Versus Other Unix-Like Kernels
The various Unix-like systems on the market, some of which have a long history and may show signs of archaic practices, differ in many important respects. All commercial variants were derived from either SVR4 or 4.4BSD; all of them tend to agree on some common standards like IEEE’s POSIX (Portable Operating Systems based on Unix) and X/Open’s CAE (Common Applications Environment).
- The Linux kernel and most commercial Unix kernels are monolithic. A notable exception is Carnegie-Mellon’s Mach 3.0, which follows a microkernel approach.
- Traditional Unix kernels are compiled and linked statically. Most modern kernels can dynammically load and unload some portions of the kernel code (typically, device derivers), which are usually called modules. Linux’s support for modules is very good, since it able to automatically load and unload modules on demand.
-
Kernel threading.
A kernel thread is an execution context that can be independently scheduled; it may be associated with a user program, or it may run only some kernel functions. Context switches between kernel threads are usually much less expensive than context swithes between ordinary processes, since the former usually operate on a common address space.
Linux uses kernel threads in a very limited way to execute a few kernel functions perodically; since Linux kernel threads cannot execute user programs, they do not represent the basic execution context abstraction.
-
Multithreaded application support.
Most modern operating systems have some kind of support for multithreaded applications, that is, user programs that are well designed in terms of many relatively independent execution flows sharing a large portion of the application data structures.
A multithreaded user application could be composed of many lightweight processes (LWP), or processes that can operate on a common address space, common physical memory pages, common opened files, and so on.
While all the commercial Unix variants of LWP are on kernel threads, Linux regards lightweight processes as the basic execution context and handles them via the nonstandard
clone( )system call. -
Linux is a nonpreemptive kernel.
This means that Linux cannot arbitrarily interleave execution flows while they are in privileged mode.
-
Multiprocessor support.
Linux 2.2 offers an evolving kind of support for symmetric multiprocessing (SMP), which means not only that the system can use multiple processors but also that any processor can handle any task; there is no discrimination among them.
-
Filesystem.
Linux’ standard filesystem lacks some advanced features, such as journaling.
-
STREAMS.
Linux has no analog to the STREAMS I/O subsystem introduced in SVR4, although it is included nowadays in most Unix kernels and it has become the preferred interface for writing device drivers, terminal drivers, and network protocals.
1.2 Hardware Dependency
Linux tries to maintain a neat distinction between hardware-dependent and hardware-independent source code. To that end, both the arch and the include directories include subdirectories correspoding to the hardware platforms supported.
1.3 Linux Versions
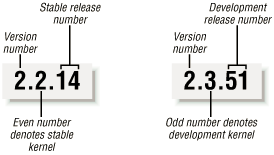
Linux distinguishes stable kernels from development kernels through a simple numbering scheme. Each version is characterized by three numbers, separated by periods. The first two numbers are used to indentify the version; the third number indentifies the release.
If the second number is even, it denotes a stable kernel; otherwise, it denotes a development kernel.
1.4 Basic Operating System Concepts
Any computer system includes a basic set of programs called the operating system.
The most important program in the set is called the kernel.
- It is loaded into RAM when the system boots and contains many critial procedures that are needed for the sytem to operate.
- The other programs are less crucial untilites; they can provide a wide variety of interactive experiences for the user—as well as doing all the jobs the user bought the computer for—but the essential shape and capabilities of the system are determined by the kernel.
The operating system must fulfill two main objectives:
- Interact with the hardware components servicing all low-level programmable elements included in the hardware platform.
- Provide an execution environment to the applications that run on the computer system (the so-called user programs).
Some operating systems allow all user programs to directly play with the hardware component (a typical example is MS-DOS). In contrast, a Unix-like operating system hides all low-level details concerning the physical orgnization of the computer from applications run by the user. When a program wants to make use of a hardware resource, it must issue a request to the operating system. The kernel evaluates the request and, if it chooses to grant the resource, interacts with the relative hardware components on behalf of the user program.
In order to enforce this mechnism, modern operating system rely on the availability of specific hardware features that forbid user programs to directly interact with low-level hardware components or to access arbitrary memory locations. In particular, the hardware introduces at least two different executions modes for the CPU: a nonprivileged mode for user programs and a privileged mode for the kernel. Unix call these User Mode and Kernel Mode, respectively.
1.4.1 Multiuser Systems
A mutliuser system is a computer that is able to concurrently and independently execute several applications belonging to two or more users.
“Concurrently” means that applications can be active at the same time and contend for the various resources such as CPU, memory, hard disks, and so on.
“Independently” means that each application can perform its task with no concern for what the applications of the other users are doing.
Multiuser operating systems must include several features:
- An authentication mechanism for verifying the user identity.
- A protection mechanism against buggy user programs that could block other applications running in the system.
- A protection mechanism against malicious user programs that could interface with, or spy on, the activity of other users.
- An accounting mechanism that limits the ammount of resource units assigned to each user.
1.4.2 Users and Groups
In a multiuser system, each user has a private space on the machine: typically, he owns some quota of the disk space to store files, receives private mail messages, and so on. The operating system must ensure that the private portion of a user space is visiable only its owner. In particular, it must ensure that no user can exploit a system application for the purpose of violating the private space of another user.
All users are identified by a unique number called the User ID, or UID. Usually only a restricted number of persons are allowed to make use of a computer system. When one of these users starts a working session, the operating system asks for a login name and a password. It the user does not input a valid pair, the system denies access. Since the password is assumed to be secret, the user’s privacy is ensured.
In order to selectively share material with other users, each user is a member of one or more groups, which is identified by a unique number called a Group ID, or GID. Each file is also associated with exactly one group. For example, access could be set so that user owning the file has read and write privileges, the group has read-only privilidges, and others on the sytem are denied access to the file.
Any Unix-like operating system has a special user called root, superuser, or supervisor. The system administrator must log in as root in order to handle user accounts, perform maintenances like system backups and program upgrades, and so on.
1.4.3 Processes
All operating systems make use of one fundamental abstraction: the process. A process can be defined either as “an instance of a program in execution,” or as the “execution context” of a running programm. In traditional operating systems, a process executes a signle sequence of instructions in an address space; the address is the set of memory address that the process is allowed to reference. Modern operating systems allow processes with multiple execution flows, that is, multiple sequences of instructions executed in the same address space.
Multiuser systems must enforce an execution environment in which several processes can be active concurrently and contend for system resources, mainly the CPU. Systems that allow concurrent active processes are said to be mutlprogramming or multiprocessing. It is important to distiguish programs from processes: several processes can execute the same program concurrently, while the same process can execute several programs sequentially.
On uniprocessor systems, just one process can hold the CPU, and hence just one execution flow can progress at a time. In general, the number of CPUs is always restricted, and therefore only a few processes can progress at the same time. The choice of the process that can progress is left to an operating system component called the scheduler. Some operating systems allow only nonpreemptive processes, which means the scheduler is invoked only when a process voluntarily relinquishes the CPU. But processes of a multiuser system must be preemptive; the operating system tracks how long each process holds the CPU and periodically activates the scheduler.
Unix is a multiprocessing operating system with preemptive processes. Indeed, the process abstraction is really fundamental in all Unix systems. Even when no user is logged in and no application is running, several system processes monitor the peripheral devices.
In particular, several procesess listen at the system terminals waiting for user logins.
-
When a user inputs a login name, the listening process runs a program that validates the user password. If the user identity is acknowledged, the process creates another process that runs a shell into which commnds are entered.
-
When a graphical display is activated, one process runs the window manager, and each window on the display is usually run by a separate process. When a user creates a graphics shell, one proces runs the graphics windows, and a second process runs the shell into which the user can enter the commands.
-
For each user command, the shell process creates another process that executes the corresponding program.
Unix-like operating system adopt a process/kernel model. Each process has the illusion that it’s the only process on the machine and it has exclusive access to the operating system servies.
- Whenever a process make a system call (i.e., a request to the kernel), the hardware changes the privilidge mode from User Mode to Kernel Mode, the the process starts the execution of a kernel procedure with a strictly limited purpose.
- In this way, the operating system acts within the execution context of the process in order to satisfy its request.
- Whenever the request is fully satisfied, the kernel procedure forces the hardware to return to User Mode and the process continues its execution form the instruction following the system call.
1.4.4 Kernel Architecture
As stated before, most Unix kernels are monolithic: each kernel layer is integrated into the whole kernel program and runs in Kernel Mode on behalf of the current process. In contrast, microkernel operating systems demand a very small set of functions from the kernel, generally including a few synchronization primitives, a simple scheduler, and an interprocess communication mechanism. Several system processes that run on top of the microkernel implement other operting system-layer functions, like memory allocators, device drivers, system call handlers, and so on.
Although academic research on operating systems is oriented toward microkernel, such operating systems are generally slower than monolithic ones, since the explicit message passing between the different layers of the operating system has a cost. However, microkernel operating systems might have some theretical advantages over monolithic ones.
- Microkernels force the system programmers to adopt a modularized approach, since any operating system layer is relatively independent program that must interact with the other layers through well-defined and clean software interfaces.
- Moreover, an existing microkernel operating system can be fairly easily ported to other architectures, since all hardware-dependent components are generally encapsulated in the microkernel code.
- Finally, microkernel operating system tend to make better use of random access memeory (RAM) than monolithic onces, since system processes that aren’t implementing needed functionalities might be swapped out or destroyed.
Modules are a kernel feature that effectively achieves many of the theoretical advantages of microkernels without introducting performance penalties. A module is an object file whose code can be linked to (and unlinked from) the kernel at runtime. The object code usually consists of a set of functions that implements a filesystem, a deveice driver, or other features athe kernel’s upper layer. The module, unlike the external layers of microkernel operating systems, does not run as a specific process. Instead, it is executed in Kernel Mode on behalf othe the current process, like any other statically linked kernel function.
The main advantages of using modules include:
-
Modularized approach
Since any module can be linked and unlinked at runtime, system programmers must introduce well-defined software interfaces to access the data structures handled by modules. This makes it easy to deveop new modules.
-
Platform independence
Even if it may rely on some specific hardware featues, a module doesn’t depend on a fixed hardware platform. For example, a disk driver module that relies on the SCSI standard works as well on an IBM-compatible PC as it does on Compaq’s Alpha.
-
Frugal main memory usage
A module can be linked to the running kernel when its functionality is required and unlinked when it is no longer useful. This mechanism also can be made transparent to the user, since linking and unlinking can be performed automatically by the kernel.
-
No performance penalty
Once linked in, the object code of a modue is equivalent to the object code of the statically linked kernel. Therefore, no explicit message passing is required when the functions of the module are invoked.
1.5 An Overview of the Unix Filesystem
1.5.1 Files
A Unix file is an inforamtion container strutured as a sequence of bytes; the kernel does not intepret the contents of a file.
Many programming libraries implement higher-level abstractions, such as records structured into fields and record addressing based on keys. However, the programs in these libraries must rely on system calls offered by the kernel.
From the user’s point of view, files are organized in a tree-structured name space.
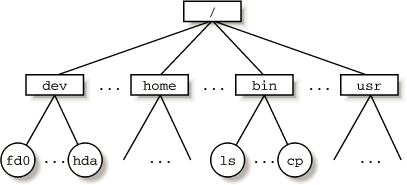
- All the nodes of the tree, except the leaves, donote directory names.
- A directory node contians information about the files and directories just beneath it.
- A file or directory name consists of a sequence of arbitrary ASCII characters, with the exception of
/and of the null character\0. - Most filessytems place a limit on the length of a filename, typically no more than 255 characters.
- The directory corresponding to the root of the tree is called the root directory. By convention, its name is a slash (
/). - Names must be different within the same directory, but the same name may be used in different directories.
Unix associates a current working directory with each process; it belongs to the process execution context, and it identifies the directory currently used by the process.
In order to identify a specific file, the process uses a pathname, which consists of slashes alternating with a sequence of directory names that lead to the file.
- If the first item in the pathname is a slash, the pathname is said to be absolute, since its starting point is the root direcotry.
- Otherwise, if the first item is a directory name or filename, the pathname is said to be relative, since its starting point is the process’s current directory.
While specifying filenames, the notations “.” and “..” are also used. They denote the current working directory and its parent directory, respectively. If the current working directory is the root directory, “.” and “..” coincide.
1.5.2 Hard and Soft Links
A filename included in a directory is called a file hard link, or more simply a link.
The same file may have several links included in the same directory or in different ones, thus several filenames.
The Unix command:
$ ln f1 f2
is used to create a new hard lin that has the pathname f2 for a file identified by the pathname f1.
Hard links have two limitations:
-
Users are not allowed to create hard links for directories. This might transform the directory tree into graph with cycles, thus making it impossible to locate a file according to its name.
-
Links can be created only among files included in the same filesystem. This is a serious limitation since modern Unix systems may include several filesystems located on different disk and/or partions, and users my be unaware of the physical divisions between them.
In order to overcome these limitations, soft links (also called symbolic links) have been introduced. Symbolic links are short files that contains an arbitrary pathname of another file. The pathname may refer to any file located in any filesystem; it may even refer to a nonexistent file.
The Unix command:
$ ln -s f1 f2
create a new soft link with pathname f2 that refers to pathname f1. When this command is executed, the filesystem creates a soft link and writes into it the f1 pathname. It then inserts—in the proper directory—a new entry containing the last name of the f2 pathname. In this way, any reference to f2 can be translated automatically into a reference to f1.
1.5.3 File Types
Unix files may have one of the following types:
-Regular filedDirectorylSymbolic linkbBlock-oriented device filecCharacter-oriented device filepPipe and named pipe (also called FIFO)sSocket
1.5.4 File Descriptor and Inode
Unix makes a clear distinction between a file and a file descriptor. With the exception of device and special files, each file consists of a sequence of characters. The file does not include any control information such as its length, or and End-Of-File (EOF) delimiter.
All information needed by the filesystem to handle a file is included in a data structure called an inode. Each file has its own inode, which the filesystem uses to indentify the file.
While filesystems and the kernel functions handling them can vary widely from on Unix system to antoher, they must always provide at least the following attributes, which are specified in the POSIX standard:
- File type
- Number of hard links associated with the file
- File length in bytes
- Device ID (i.e., an identifier of the device containing the file)
- Inode number that indentifies the file within the filesystem
- User ID of the file owner
- Group ID of the file
- Several timestamps that specify the inode status change time, the last access time, and the last modify time
- Access rights and file mode
1.5.5 Access Rights and File Mode
The potential users of a file fall into three classes:
- The user who is the onwer of the file
- The users who belong to the same group as the file, not including the owner
- All remaining users (others)
There are three types of access rights, Read, Write, and Execute, for each of these three classes. Thus, the set of access rights associated with a file consists of nine different binary flags. Three additional flags, called suid (Set User ID), sgid (Set Group ID), and sticky define the file mode. These flags have the following meaning when applied to executable files:
-
suid
A process executing a file normally keeps the User ID (UID) of the process owner. However, if the executable file has the suid flag set, the process gets the UID of the file owner.
-
sgid
A process executing a file keeps the Group ID (GID) of the proces group. However, if the executable file has the sgid flag set, the process gets the ID of the file group.
-
sticky
An executable file with the sticky flag set corresponds to a request to the kernel to keep the program in memory after its execution terminates.
When a file is created by a process, its owner ID is the UID of the process. Its owner group ID can be either the GID of the creator process or the GID of the parent directory, depending on the value of the sgid flag of the parent directory.
1.5.6 File-Handling System Calls
When a user accesses the contents of either a regular file or a directory, he actually accesses some data stored in a hardware block device. In this sense, a filesystem is a user-level view of the physical organization of a hard disk partition. Since a process in User Mode cannot directly interact with the low-level hardware components, each actual file operation must be performed in Kernel Mode.
Therefore, the Unix operating system defines several system calls related to file handing. Whenever a process wants to perform some operation on a specific file, it uses the proper system call and passes the file pathname as a parameter.
1.5.6.1 Opening a file
Processes can access only “opened” files. In order to open a file, the process invokes the system call:
fd = open(path, flag, mode)
This system call creates an “open file” object and returns an identifier called file descriptor.
An open file object contians:
- Some file-handling data structures, like a pointer to the kernel buffer memory area where file data will be copied; an offset field that denotes the current position in the file from which the next operation will take place (the so-called file pointer); and so on.
- Some pointers to kernel functions that the process is enabled to invoke. The set of permitted functions depends on the value of the flag parameter.
In order to create a new file, the process may also invoke the create( ) system call, which is handled by the kernel excactly like open( ).
1.5.6.2 Accessing an opened file
Regular Unix files can be addressed either sequentially or randomly, while device files and named pipes are usually accessed sequenctially. In both kinds of access, the kernel stores the file pointer in the open file object, that is, the current position at which the next read or write operation will take place.
Sequential access is implicitly assumed: the read( ) and write( ) system calls always refer to the position of the current file pointer. In order to modify the value, a program must explicitly invoke the lseek( ) system call. When a file is opened, the kernel sets the file pointer to the position of the first byte in the file (offset 0).
1.5.6.3 Closing a file
When a process does not need to access the contents of a file anymore, it can invoke the system call:
res = close(fd);
which releases the open file object corresponding to the file descriptor fd. When a process terminates, the kernel closes all its stil opened files.
1.5.6.4 Renaming and deleting a file
In order to rename or delete a file, a process does not need to open it. Indeed, such operations do not act on the contents of the affected file, but rather on the contents of one or more directories. For example, the system call:
res = rename(oldpath, newpath);
changes the name of a file link, while the system call:
res = unlink(pathname);
decrements the file link count and removes the corresponding directory entry. The file deleted only when the link count assumes the value 0.
1.6 An Overview of Unix Kernels
Unix kernels provide an execution environment in which applications may run. Therefore, the kernel must implement a set of services and corresponding interfaces. Applications use those interfaces and do not usually interact directly with hardware resources.
1.6.1 The Process/Kernel Model
As already mentioned, a CPU can run either in User Mode or in Kernel Mode. Actually, some CPUs can have more than two execution states. For instance, the Intel 80x86 microprocessors have four different execution states. But all standard Unix kernels make use of only Kernel Mode and User Mode.
-
When a program is executed in User Mode, it cannot directly access the kernel data structures or the kernel programs.
-
When an application executes in Kernel Mode, however, these restrictions no longer apply.
-
Each CPU model provides special instructions to switch from User Mode to Kernel Mode and vice versa.
-
A program executes most of the time in User Mode and switchs to Kernel Mode only when requesting a service provided by the kernel.
-
When the kernel has satisfied the program’s request, it puts the program back in User Mode.
Processes are dynamic entities that usually have a limited life span within the system. The task of creating, eliminating, and sysnchronizing the existing processes is delegated to a group of rountines in the kernel.
The kernel itself is not a process but a process manager.
-
The process/kernel model assumes that proceese that require a kernel service make use of specific programming constructs called system calls.
-
Each system call sets up the group of parameters that identifies the process request and then executes the hardware-dependent CPU instruction to switch from User Mode to Kernel Mode.
Besides user processes, Unix systems include a few privileged processes called kernel threads with the following characteristics:
- They run in Kernel Mode in the kernel address space.
- They do not interact with users, and thus do not require terminal devices.
- They are usually created during system startup and remain alive unitl the system is shut down.
Notice how the process/kernel model is somewhat orthogonal to the CPU state: on a uniprocessor system, only one process is running at any time and it may run either in User or in Kernel Mode. If it runs in Kernel Mode, the processor is executing some kernel routine.
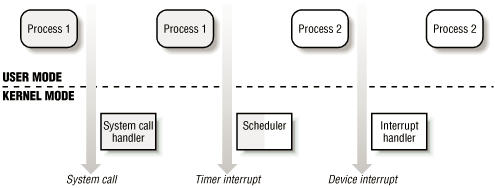
Unix kernels do much more than handle system calls; in fact, kernel routines can be activated in serveral ways:
-
A process invokes a system call.
-
The CPU executing the process signals an exception, which is some unusual condition such as an invalid instruction. The kernel handles the exception on behalf of the process that caused it.
-
A peripheral device issues an interrupt signal to the CPU to notify it of an event such as a request for attention, a status change, or the completion of an I/O operation.
Each interrupt signal is dealt by a kernel program called an interrupt handler. Since peripheral devices operate asynchronously with respect to the CPU, interrupts occur at unpredicatable times.
-
A kernel thread is executed; since it runs in Kernel Mode, the corresponding program must be considered part of the kernel, albeit encapsualted in a process.
1.6.2 Process Implementation
To let the kernel processes, each process is represented by a process descriptor that includes information about the current state of the process.
When the kernel stops the execution of a process, it saves the current contents of several processor registers in the process descriptor. These include:
- The program counter (PC) and stack pointer (SP) registers
- The general-purpose registers
- The floating point registers
- The processor control registers (Process Status Word) containing information about the CPU state.
- The memory management registers used to keep track of the RAM accessed by the process.
When the kernel decides to resume executing a process, it uses the proper process descriptor fields to load the CPU registers. Since the stored value of the program counter points to the instruction following the last instruction executed, the process resumes execution from where it was stopped.
When a process is not executing on the CPU, it is waiting for some event. Unix kernels distinguish many wait sates, which are usually implemented by queues of process descriptors; each (possible empty) queue corresponds to the set of processes waiting for a specific event.
1.6.3 Reentrant Kernels
All Unix kernels are reentrant: this means that several processes may be executing in Kernel Mode at the same time. Of course, on uniprocessor systems only one process can progress, but many of them can be blocked in Kernel Mode waiting for the CPU or the completion of some I/O operation.
For instance, after issuing a read to a disk on behalf of some process, the kernel will let the disk controller handle it and will resume executing other processes. An interrupt notifies the kernel when the device has statified the read, so the former process can resume the execution.
- One way to provide reentrancy is to write functions so that they modify only local variables and do not alter global data structures. Such functions are called reentrant functions.
- But a reentrant kernel is not limited just to such reentrant functions (although that is how some real-time kernels are implemented). Instead, the kernel can include nonreentrant functions and use locking mechanisms to ensure that only one process can execute a nonreentrant function at a time.
- Every process in the Kernel Mode acts on its own set of memory locations and conannot interface with others.
If a hardware interrupt occurs, a reentrant kernel is able to suspend the current running process even if that process is in Kernel Mode. This capability is very important, since it imporves the throughput of the device controllers that issue interrupts. Once a device has issued an interrupt, it waits until the CPU acknowledges it. If the kernel is able to answer quickly, the device controller will be able to perform other tasks while the CPU handles the interrupt.
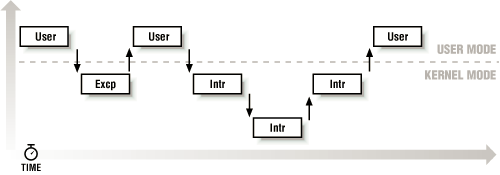
A kernel control path denotes the sequence of instructions executed by the kernel to handle a system call, an exception, or an interrupt.
In the simplest case , the CPU executes a kernel control path from the first instruction to the last. When one of the following events occurs, however, the CPU interleaves the kernel control paths:
-
A process executing in User Mode invokes a system call and the corresponding kernel control path verifies that the request cannot be satisfied immediately; it then invokes the scheduler to select a new process to run. As a result, a process switch occurs. The first kernel control path is left unfinished and the CPU resumes the execution of some other kernel control path. In this case, the two control paths are executed on behalf of two different processes.
-
The CPU detects an exception—for example, an access to a page not present in RAM—while running a kernel control path. The first control path is suspended, and the CPU starts the execution of a suitable procedure. In our example, this type of procedure could allocate a new page for the process and read its contents from disk. When the procedure terminates, the first control path can be resumed. In this case, the two control paths are executed on behalf of the same process.
-
A hardware interrupt occurs while the CPU is running in kernel control path with the interrupts enabled. The first kernel control path is left unfinished and the CPU starts processing another kernel control path to handle the interrupt. The first kernel control path resumes when the interrupt handler terminates. In this case the two kernel control paths run in the execution context of the same process and the total elapsed system time is accounted to it. However, the interrupt handler doesn’t necessarily operate on behalf of the process.
1.6.4 Process Address Space
Each process runs in its private address space. A process running in User Mode refers to private stack, data, and code areas. When running in Kernel Mode, the process addresses the kernel data and code area and makes use of another stack.
Since the kernel is reentrant, several kernel control paths—each related to a different process—may be executed in turn. In this case, each kernel control path refers to its own private kernel stack.
While it appears to each process that it has access to a private address space, there are times when part of the address space is shared among processes. In some case this sharing is explicitly requested by processes; in others it is done automatically by the kernel to reduce memory usage.
Processes can also share parts of their address space as a kind of interprocess communication, using the “shared memory” technique introduced in System V and supported by Linux.
Finally, Linux supports the mmap( ) system call, which allows part of a file or the memory residing on a device to be mapped into part of a process address space. Memory mapping can provide an alternative to normal reads and writes for transferring data. If the same file is shared by several processes, it memory mapping is included in the address space of each of the processes that share it.
1.6.5 Synchronization and Critical Regions
Implementating a reentrant kernel requires the use of synchronization: if a kernel control path is suspended while acting on a kernel data structure, no other kernel control path will be allowed to act on the same data structure unless it has been reset to a consistent state. Otherwise, the interaction of the two control paths could corrupt the stored information.
For example, let’s suppose that a global variable V contains the number of available items of some system resource.
- A first kernel control path A reads the variable and determines that there just on available item.
- At this point, another kernel control path B is actived and reads the same variable, which still contains the value 1.
- Thus, B decrements V and starts using the resource item.
- Then A resumes the execution; because it has already read the value of V, it assumes that it can be decrement V and take the resoure item, which B alread uses.
- As a final result, V contains -1, and two kernel control paths are usings the same resource item with potentially disastrous effects.
When the outcome of some computation depends on how two or more processes are scheduled, the code is incorrect: we say that there is a race condition.
In general, safe access to a global variable is ensured by using atomic operations. In previous example, data corruption would not be possible if the two control paths read and decrement V with a single, noninterruptible operation.
However, kernels contain many data strucutres that cannot be accessed with a signle operation. For example, it usually isn’t possible to remove an element from a linked list with a single operation, because the kernel needs to access at least two pointers at once.
Any section of code that should be finished by each process that begins another process can enter it called a critial region.
These problems occur not only among kernel control paths but also among processes sharing common data.
1.6.5.1 Nonpreemptive kernels
In search of a drastically simple solution to synchronization problems, most traditional Unix kernels are nonpreemptive: when a process executes in Kernel Mode, it cannot be arbitrarily suspended and substitued with another process. Therefore, on a uniprocessor system all kernel data structures that are not updated by interrupts or exception handlers are safe for the kernel access.
Of course, a process in Kernel Mode can voluntarily reliquish the CPU, but this case it must ensure that all data structures are left in a consistent state. Moreover, when it resumes its execution, it must recheck the value of any previously accessed data structures that could be changed.
Nonpreemptability is ineffective in multprocessor, since two kernel control paths running on different CPUs could concurrently access the same data structure.
1.6.5.2 Interrupt disabling
Another syschorization mechanism for uniprocessor systems consists of disabling all hardware interrupts before entering a criptial region and reenabling them right after leaving it. This mechanism, while simple, is far from optimal. If the critical region is large, interrupts can remain disabled for a relatively long time, potentially causing all hardware activities to freeze.
Moreoever, on a multiprocessor system this mechanism doesn’t work at all. There is no way to ensure that no other CPU can access the same data strutures updated in the protected critical region.
1.6.5.3 Semaphores
A widely used mechanism, effective in both uniprocessor and multiprocessor systems, relies on the use of sempaphores. A semaphore is simply a counter associated with a data structure; the semaphore is checked by all kernel threads before they try to access the data structure.
Each semaphore may be viewed as an object composed of:
- An integer varible
- A list of wainting processes
- Two atomic method:
down( )andup( )
The down( ) method decrements the value of the semaphore. If the new value is less than 0, the method adds the running process to the semaphore list and then blocks (i.e., invokes the scheduler). The up( ) method increments the value of the semaphore and, if its new value if greater than or equal to 0, reactivates one or more processes in the semaphore list.
Each data structure to be protected has its own semaphore, which is initialization to 1. When a kernel control path wishes to access the data structure, it executes the down( ) method on the semaphore. If the value of the new semaphore isn’t negative, access to the data structure is granted. Otherwise, the process that is executing kernel control path is added to the semaphore list and blocked. When another process executes the up( ) method on that semaphore, one of the processes in semaphore list is allowed to proceed.
1.6.5.4 Spin locks
In multiprocessor systems, semaphores are not always the best solution to the synchronization problems. Some kernel data structures should be protected from being concurrently accessed by kernel control paths that run on different CPUs. In this case, if the time required to update the data structure is short, a semaphore could be very inefficient. To check a semaphore, the kernel must insert a process in the semaphore list and then suspend it. Since both operations are relatively expensive, in the time it takes to complete them, the other kernel control path could have already released the semaphore.
In these cases, multiprocessor operating systems make use of spin locks. A spin lock is very similar to a semaphore, but it has no proces list: when a process finds the lock closed by another process, it “spin” around repeatly, executing a tight instruction loop until the lock becomes open.
Of course, spin locks are useless in a uniprocessor environment. When a kernel control path tries to access a locked data structure, it starts an endless loop. Therefore, the kernel control path that is updating the protected data structure would not have a chance to continue the execution and release the spin lock. The final result is that the system hangs.
1.6.5.6 Avoiding deadlocks
Processes or kernel control paths that synchronize with other control paths may easily enter in a deadlocked state. The simplest case of deadlock occurs when process p1 gains access to data structure a and process p2 gains access to b, but p1 then waits for b and p2 waits for a. Other more complex cyclic waitings among groups of processes may also occur. Of course, a deadlock condition causes a complete freeze of the affected processes or kernel control paths.
As far as kernel design is concerned, deadlock becomes an issue when the number of kernel semaphore types used is high. In this case, it may be quite difficult to ensure that no deadlock state will ever be reached for all possible ways to interleave kernel paths. Several operating systems, including Linux, avoid this problem by introducting a very limited number of semaphore types and by requesting semaphores in an assending order.
1.6.6 Signals and Interprocess Communication
Unix signals provide a mechanism for notifying processes of system events. Each event has it own signal number, which is usually referred to by a symbolic constant such as SIGTERM.
There are two kinds of system events:
-
Asynchronous notifications
For instance, a user can send the interrupt signal
SIGTERMto a foreground process by pressing the interrupt keycode (usually, CTRL-C) at the terminal. -
Synchronous errors or exceptions
For instance, the kernel sends the signal
SIGSEGVto a process when it accesses a memory location at an illegal address.
The POSIX standard defines about 20 different signals, two of which are user-defined and may be used as a primitive mechanism for commucation and synchronization among process in User Mode. In general, a process may react to a signal reception in two possible ways:
- Ignore the signal
- Asynchronously execute a specified procedure (the signal handler).
If the process does not specify one of these alternatives, the kernel performs a default action that depends on the signal number. The five possible default actions are:
- Terminate the process.
- Write the execution context and the contents of the address space in a file (core dump) and terminate the process.
- Ignore the signal.
- Suspend the process.
- Resume the process’s execution, if it was stopped.
Kernel signal handling is rather elaborate since the POSIX semantics allows processes to temporarily block signals. Moreover, a few signals such as SIGKILL cannot be directly handled by the process and cannot be ignored.
AT&Ts Unix System V introduced other kinds of interprocess communication among processes in User Mode, which have been adopted by many Unix kernels: semaphore, message queues, and shared memory. They are colectively known as System V IPC.
1.6.7 Process Management
Unix makes a neat distinction between the process and the program it is executing. To that end, the fork( ) and exit( ) system calls are used respectively to create a new process and to terminate it, while an exec( )-like system call is invoked to load a new program. After such a system call has been executed, the process resumes execution with a brand new address space containing the loaded program.
The process that invoked a fork( ) is the prarent while the new process is its child. Parents and children can find each other because the data structure describing each process includes a pointer to its immediate parent and pointers to all its children.
A naive implementation of the fork( ) would require both the parent’s data and the parent’s code to be dumplicated and assign the copies to the child. This would be quite time-consuming. Current kernels that can rely on hardware paging units follow the Copy-On-Write approach, which defers page duplication until the last moment (i.e., until the parent or the child is required to write into a page).
The exit( ) system call terminates a process. The kernel handles this system call by releasing the resources owned by the process and sending the parent process a SIGCHLD signal, which is ignored by default.
1.6.7.1 Zombie processes
How can a parent inquire about termination of its children? The wait( ) systemc all allows a process to wait unitl one of its children terminates; it return the process ID (PID) of the terminated child.
When executing this system call, the kernel checks whether a child has alreadly terminated. A special zombie process state is introducred to respesent terminated processes: a process remains in that state until its parent process executes a wait( ) system call on it. The system call handler extracts some data about resource usage has been collected. In no child process has already terminated when the wait( ) system call is executed, the kernel usually puts the process in a wait state until a child terminates.
It’s a good practice for the kernel to keep around informantion on a child process until the parent issues its wait( ) call, but suppose the parent process terminates without issuing that call? The information takes up valuable memory slots that could be used to serve living processes. For example, many shells allow the user to start a command in the background and then log out. The process that is running the command shell terminates, but its children continue their execution.
The solution lies in a special system process called init that is created during system intialization. When a process terminates, the kernel changes the appropriate process descriptor pointers of all the existing children of the terminates process to make them become children of init. This process monitors the execution of all its children and routinely issues wait( ) system calls, whose side effect is to get rid of all zombies.
1.6.7.2 Process groups and login sessions
Modern Unix operating systems introduce the notion of process groups to represent a “job” abstraction. For example, in order to execute the command line:
$ ls | sort | more
a shell that supports process group, such as bash, creates a new group for the three processes corresponding to ls, sort, and more. In this way, the shell acts on the three processes as if they were a signle entity (the job, to be precise). Each process descriptor includes a process group ID field. Each group of processes may have a group leader, which is the process whose PID coincides with the process group ID. A newly created process is initially inserted into the process group of its prarent.
Modern Unix kernels also introduce login sessions. Informally, a login session contains all processes that are descendants of the process that has started a working session on a specific terminal—usually, the first command shell process created for the user. All processes in a process group must be in the same login session. A login session may have several process group active simultaneously; one of these process groups is always in the foreground, which means that it has access to the terminal. The other active process groups are in the backgroud. When a background process tries to access the terminal, it receives a SIGTTIN or SIGTTOUT signal. In many command shells the internal commands bg and fg can be used to put a process group in either the background or the foreground.
1.6.8 Memory Management
Memory management is by far the most complex activity in a Unix kernel.
1.6.8.1 Virtual memory
All recent Unix systems provide a useful abstraction called virtual memory. Virtual memory acts as a logical layer between the application requests and the hardware Memory Management Unit (MMU). Virtual memory has many purposes and advantages:
- Several processes can be executed concurrently.
- It is possible to run applications whose memory needs are larger than the available physical memory.
- Processes can execute a program whose code is only partially loaded in memory.
- Each process is allowed to access a subset of the available physical memory.
- Processes can share a single memory image of a library or program.
- Programs can be relocatable, that is, they can be placed anywhere in physical memory.
- Programmers can write machine-independent code, since they do not need to be concerned about physical memory organization.
The main ingredient of a virtual memory subsystem is the notion of virtual address space.
The set of memory references that a process can use is different from physical memory addresses. When a process uses a virtual address, the kernel and the MMU cooperate to locate the actual physical location of the requested memory item.
Today’s CPUs include hardware circuits that automatically translate the virtual addresses into physical ones.
- To that end, the available RAM is partitioned into page frames 4 or 8 KB in length, and a set of page tables is introduced to specify the correspondence between virtual and physical addresses.
- These circuits make memory allocation simpler, since a request for a block of contiguous virtual addresses can be satisfied by allocating a group of page frames having noncontiguous physical addresses.
1.6.8.2 Random access memory usage
All Unix operating systems clearly distinguish two portions of the random access memory (RAM).
-
A few megabytes are dedicated to storing the kernel image (i.e., the kernel code and the kernel static data structures).
-
The remaining portion of RAM is usually handled by the virtual memory system and is used in three possible ways:
- To satisfy kernel requests for buffers, descriptors, and other dynamic kernel data structures
- To satisfy process requests for generic memory areas and for memory mapping of files
- To get better performance from disks and other buffered devices by means of caches
Each request type is valuable. On the other hand, since the available RAM is limited, some balancing among request types must be done, particually when little available memory is left. Moreover, when some critical threshold of available memory is reached and a page-frame-reclaiming algorithm is invoked to free additional memory.
On major problem that must be solved by the virtual memory system is memory fragmentation. Ideally, a memory request should fail only when the number of free page frames is too small. However, the kernel is often forced to use physically continguous memory areas, hence the memory request could fail even if there is enough available but it is not available as one contiguous chunk.
1.6.8.3 Kernel Memory Allocator
The Kernel Memory Allocator (KMA) is a subsystem that tries to satisfy the requests for memory areas from all parts of the system.
- Some of these requests will come from other kernel subsystems needing memory for kernel use.
- And some requests will come vi system calls from user programs to increase their processes’ address spaces.
A good KMA should have the following features:
- It must be fast. Actually, this is the most crucial atrribute, since it is invoked by all kernel subsystems (including the interrupt handlers).
- It should minimize the amount of wasted memory.
- It should try to reduce the memory fragmentation problem.
- It should be able to cooperate with the other memory management subsystems in order to borrow and release page frames from them.
1.6.8.4 Process virtual address space handling
The address space of a process contains all the virtual memory addresses that the process is allowed to reference.
The kernel usually stores a process virtual address space as a list of memory area descriptors.
For example, when a process starts the execution of some program via an exec( )-like system call, the kernel assigns to the process a virtual address space that comprises memory areas for:
- The executable code of the program
- The initialized data of the program
- The uninitialized data of the program
- The initial program stack (that is, the User Mode stack)
- The executable code and data of needed shared libraries
- The heap (the memory dynamically requested by the program)
All recent Unix operating systems adopt a memory allocation stratery called demand paging.
- With demand paging, a process can start program execution with none of its pages in physical memory.
- As it accesses a nonpresent page, the MMU generates an exception; the exception handler finds the affected memory region, allocates a free page, and initializes it with the appropriate data.
- In a similar fashion, when the process dynamically requires some memory by using
malloc( )or thebrk( )system call (which is invoked internally bymalloc( )), the kernel just updates the size of the heap memory region of the process. A page frame is assigned to the process only when it generates an exception by tring to refer its virtual memory addresses.
Virtual address spaces also allow other efficient stargies, such as the Copy-On-Write strategy.
1.6.8.5 Swapping and caching
In order to extend the size of the virtual address space usable by the processes, the Unix operating system makes use of swap areas on disk. The virtual memory system regards the contents of a page frame as the basic unit for swapping. Whenever some process refers to a swapped-out page, the MMU raise an exception. The exception handler then allocates a new page frame and initializes the page frame with its old contents save on disk.
On the other hand, physical memory is also used as cache for hard disks and other block devices. This is because hard drives are very slow: a disk access requires several milliseconds, which is a very long time compared with the RAM access time. Therefore, disks are often the bottleneck in system performance. As a general rule, one of the policies already implemented in the earliest Unix system is to defer writing to disk as long as possible by loading into RAM a set of disk buffers corresponding to blocks read from disk. The sync( ) system call forces disk synchronization by writting all of the “dirty” buffers (i.e., all the buffers whose contents differ from that of the corresponding disk blocks) into disk. In order to avoid data loss, all operating systems take care to periodically write dirty buffers back to disk.
1.6.9 Device Drivers
The kernel interacts with I/O devices by means of device drivers.
Device drivers are included in the kernel and consist of data structures and functions that control one or more devices, such as a hark disks, keyboards, mouses, monitors, network interfaces, and devices connected to a SCSI bus.
Each driver interacts with the remaing part of the kernel (even with other drivers) through a specific interface.
References
- Daniel P. Bovet、 Marco Cesati (2005-11), “Chapter 1: Understanding the Linux Kernel”
- What’s program counter, http://whatis.techtarget.com/definition/program-counter
- Protection ring, https://en.wikipedia.org/wiki/Protection_ring
- Call stack, https://en.wikipedia.org/wiki/Call_stack#STACK-POINTER
- SCSI, https://en.wikipedia.org/wiki/SCSI