
TCP is a unicast connection-oriented protocol.
-
Before either end can send data to the other, a connection must be established between them.
-
During connection establishment, several options can be exchanged between the two endpoints regarding the parameters of the connection.
-
Some options are allowed to be sent only when the connection is established, and others can be sent later.
-
Because of its management of connection state (information about the connection kept by both endpoints), TCP is a considerably more complicated protocol than UDP.
UDP is a connectionless protocol that involves no connection establishment or termination.
One of the major differences between the two is the amount of detail required to handle the various TCP states properly: when connections are created, terminated normally, and reset without warning.
Recall that TCP’s service model is a byte stream. TCP detects and repairs essentially all the data transfer problems that may be introduced by packet loss, duplication, or errors at the IP layer (or below).
1. TCP Connection Establishment and Termination
A TCP connection is defined to be a 4-tuple consisting of two IP addresses and two port numbers. More precisely, it is a pair of endpoints or sockets where each endpoint is identified by an (IP address, port number) pair.
A connection typically goes through three phases: setup, data transfer (called established), and teardown (closing).
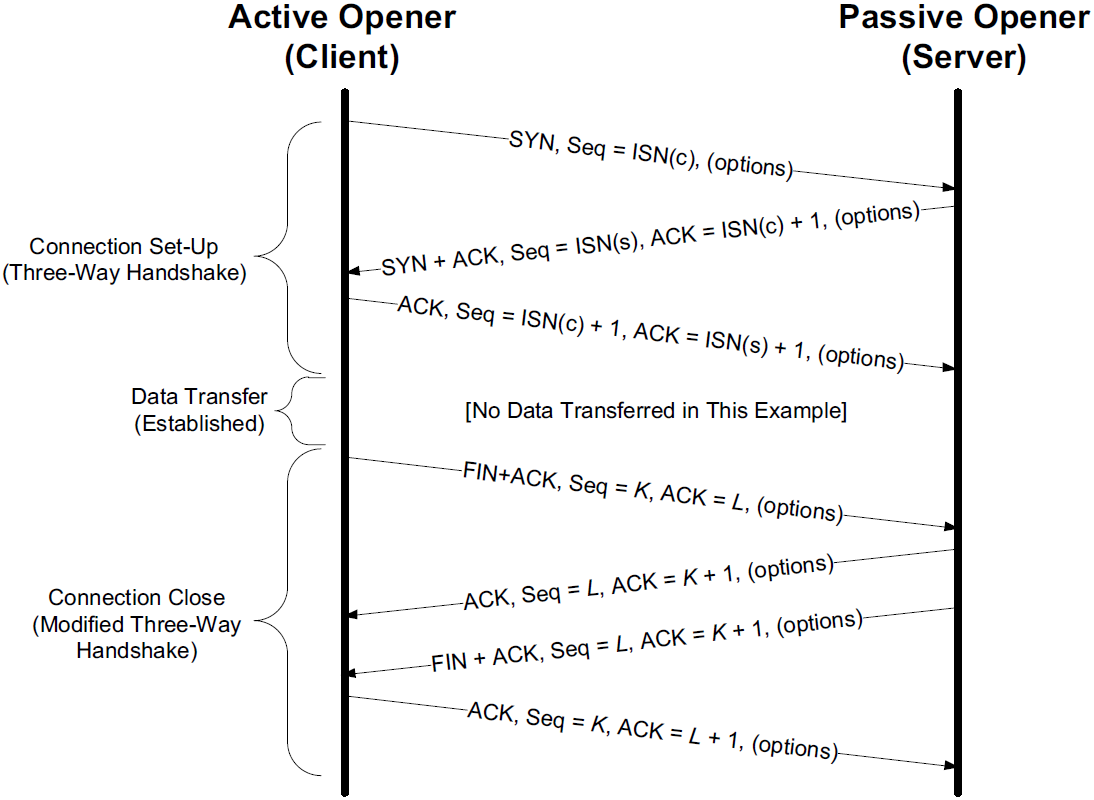
To establish a TCP connection, the following events usually take place:
-
The active opener (normally called the client) sends a SYN segment (i.e., a TCP/IP packet with the SYN bit field turned on in the TCP header) specifying the port number of the peer to which it wants to connect and the client’s initial sequence number or ISN(c).
It typically sends one or more options at this point.
This is segment 1.
-
The server responds with its own SYN segment containing its initial sequence number (ISN(s)).
This is segment 2.
The server also acknowledges the client’s SYN by ACKing ISN(c) plus 1.
A SYN consumes one sequence number and is retransmitted if lost.
-
The client must acknowledge this SYN from the server by ACKing ISN(s) plus 1.
This is segment 3.
These three segments complete the connection establishment. This is often called the three-way handshake.
-
Its main purposes are to let each end of the connection know that a connection is starting and the special details that are carried as options, and to exchange the ISNs.
-
The side that sends the first SYN is said to perform an active open. As mentioned, this is typically a client.
-
The other side, which receives this SYN and sends the next SYN, performs a passive open. It is most commonly called the server.
-
There is a supported but unusual simultaneous open when both sides can do an active open at the same time and become both clients and servers.
Either end can initiate a close operation, and simultaneous closes are also supported but are rare.
-
Traditionally, it was most common for the client to initiate a close.
-
However, other servers (e.g., Web servers) initiate a close after they have completed a request.
-
Usually a close operation starts with an application indicating its desire to terminate its connection (e.g., using the
close()system call). -
The closing TCP initiates the close operation by sending a FIN segment (i.e., a TCP segment with the FIN bit field set).
The complete close operation occurs after both sides have completed the close:
-
The active closer sends a FIN segment specifying the current sequence number the receiver expects to see (K).
The FIN also includes an ACK for the last data sent in the other direction (labeled L).
-
The passive closer responds by ACKing value K + 1 to indicate its successful receipt of the active closer’s FIN.
At this point, the application is notified that the other end of its connection has performed a close.
Typically this results in the application initiating its own close operation.
The passive closer then effectively becomes another active closer and sends its own FIN. The sequence number is equal to L.
-
To complete the close, the final segment contains an ACK for the last FIN.
Note that if a FIN is lost, it is retransmitted until an ACK for it is received.
While it takes three segments to establish a connection, it takes four to terminate one.
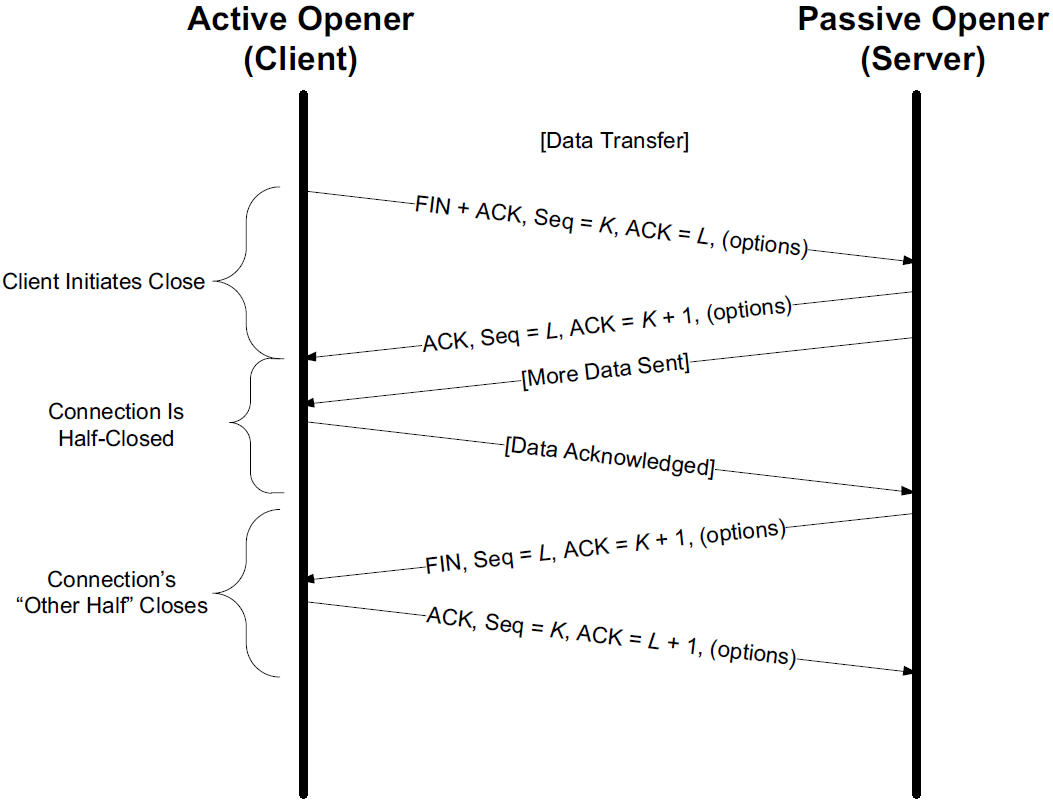
It is also possible for the connection to be in a half-open state, although this is not common. This reason is that TCP’s data communications model is bidirectional, meaning it is possible to have only one of the two directions operating.
The half-close operation in TCP closes only a single direction of the data flow. Two half-close operations together close the entire connection. The rule is that either end can send a FIN when it is done sending data.
When a TCP receives a FIN, it must notify the application that the other end has terminated that direction of data flow. The sending of a FIN is normally the result of the application issuing a close operation, which typically causes both directions to close.
The seven segments we have seen are baseline overheads for any TCP connection that is established and cleared gracefully.
-
When a small amount of data needs to be exchanged, it is now apparent why some applications prefer to use UDP because of its ability to send and receive data without establishing connections.
-
However, such applications are then faced with handling their own error repair features, congestion management, and flow control.
1.1. TCP Half-Close
TCP supports a half-close operation. Few applications require this capability, so it is not common.
To use this feature, the API must provide a way for the application to say, essentially, "I am done sending data, so send a FIN to the other end, but I still want to receive data from the other end, until it sends me a FIN".
The Berkeley sockets API supports half-close, if the application calls the shutdown() function instead of calling the more typical close() function. Most applications, however, terminate both directions of the connection by calling close.
|
Both the However, even though they both end up sending a FIN packet, there’s a difference between the two:
|
1.2. Simultaneous Open and Close
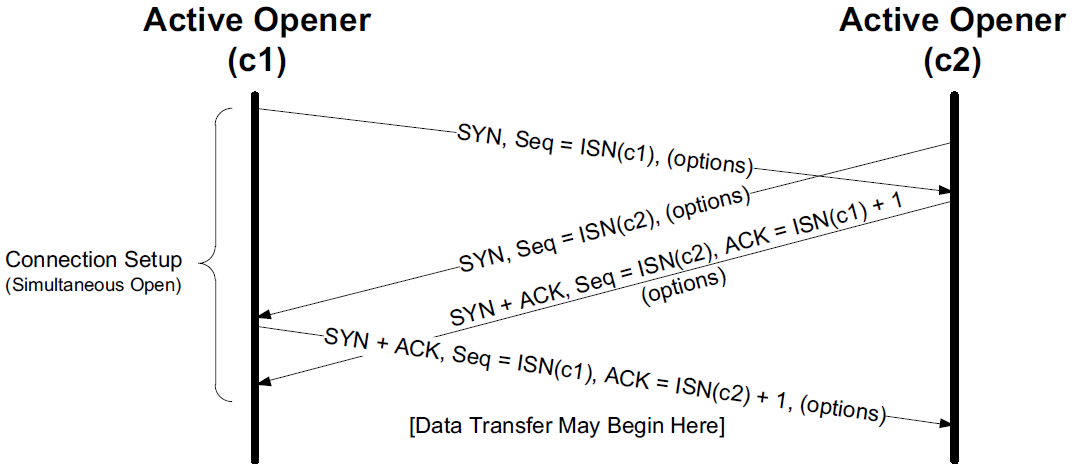
It is possible, although highly improbable unless specifically arranged, for two applications to perform an active open to each other at the same time. If this happens, it is called a simultaneous open.
-
Each end must have transmitted a SYN before receiving a SYN from the other side; the SYNs must pass each other on the network.
-
This scenario also requires each end to have an IP address and port number that are known to the other end, which is rare (except for the firewall hole-punching techniques).
-
A simultaneous open requires the exchange of four segments, one more than the normal three-way handshake.
-
Also note that we do not call either end a client or a server, because both ends act as client and server.
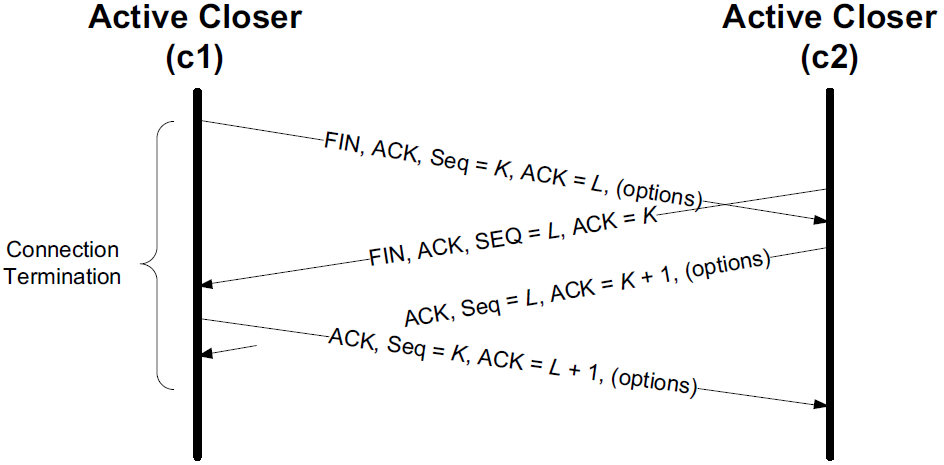
With a simultaneous close the same number of segments are exchanged as in the normal close. The only real difference is that the segment sequence is interleaved instead of sequential.
1.3. Initial Sequence Number (ISN)
When a connection is open, any segment with the appropriate two IP addresses and port numbers is accepted as valid provided the sequence number is valid (i.e., within the window) and the checksum is OK.
Before each end sends its SYN to establish the connection, it chooses an ISN for that connection.
-
The ISN should change over time, so that each connection has a different one.
[RFC0793] specifies that the ISN should be viewed as a 32-bit counter that increments by 1 every 4μs.
-
The purpose of doing this is to arrange for the sequence numbers for segments on one connection to not overlap with sequence numbers on a another (new) identical connection.
-
In particular, new sequence numbers must not be allowed to overlap between different instantiations (or incarnations) of the same connection.
-
In modern systems, the ISN is typically selected in a semirandom way.
If a connection had one of its segments delayed for a long period of time and closed, but then opened again with the same 4-tuple, it is conceivable that the delayed segment could reenter the new connection’s data stream as valid data.
-
By taking steps to avoid overlap in sequence numbers between connection instantiations, we can try to minimize this risk.
-
It does suggest, however, that an application with a very great need for data integrity should employ its own CRCs or checksums at the application layer to ensure that its own data has been transferred without error.
This is generally good practice in any case, and it is commonly done for large files.
The connection 4-tuple as well as the currently active window of sequence numbers is all that is required to form a TCP segment that is considered valid to a communicating TCP endpoint, which represents a form of vulnerability for TCP:
-
anyone can forge a TCP segment and, if the sequence numbers, IP addresses, and port numbers are chosen appropriately, can interrupt a TCP connection [RFC5961].
-
One way of repelling this is to make the initial sequence number (or ephemeral port number [RFC6056]) relatively hard to guess. Another is encryption.
* If a TCP peer receives a malicious overlapping packet, this is typically indicative of a cybersecurity threat such as a TCP sequence prediction attack. In such an attack scenario, an attacker might try to either disrupt the existing connection or inject malicious data into the data stream.
When a TCP peer receives an overlapping packet, it should follow a set of rules specified in the RFC 793 (also called the TCP/IP v4 Specification). According to these rules, when a packet arrives that overlaps with already-received data, the existing data should be replaced only if the incoming data has a greater sequence number.
TCP uses a sliding window for sequence numbers, so if the forged, overlapping packet’s sequence number is outside of the expected window, the packet can be discarded. If the sequence number is within the window but it’s not the next expected sequence, the TCP stack should queue the packet to be processed in order.
TCP’s Range field, along with sequence and acknowledgement numbers, provides some protections against these types of attacks. However, the best protection comes from using encryptions and security measures at higher levels, such as Transport Layer Security (TLS), Secure Sockets Layer (SSL), etc.
Additionally, modern operating systems implement random sequence number generation, reducing the likelihood of successful TCP sequence prediction attacks. These random initial sequence numbers (ISN) are typically well-distributed for each new connection, making it difficult for attackers to predict the correct sequence number.
In any case, unexpected behavior or anomalies in network traffic should be investigated as they can often be indicative of a range of security threats.
* Transport Layer Security (TLS) and its predecessor, Secure Sockets Layer (SSL), are cryptographic protocols designed to provide secure communications over a network. They defend against various forms of cyber attacks, including sequence prediction attacks, in the following ways:
-
Encryption: The most crucial defense is that communication between the client and server is encrypted. Even if an attacker is successful in intercepting the packets, they would not be able to understand the encrypted contents without the proper decryption keys.
-
Authentication: TLS/SSL mandates certificate-based authentication. This means that the entities involved in the communication must present digital certificates to validate their identities. This authentication helps to prevent "man-in-the-middle" attacks (where an attacker intercepts and may alter communication between two parties without their knowledge).
-
Integrity Checks: TLS/SSL protocols include a Message Authentication Code (MAC), which provides a way to check data integrity. Each message packet contains a checksum (MAC), which is calculated using data contained in the packet along with a secret key. The recipient also calculates its own MAC for the packet and verifies it against the one sent with the packet. If the MACs do not match, it means the data was tampered with during transmission, defending against any injection attacks such as forged overlapping packets.
-
Sequence Numbers: TLS/SSL also specifies that every record (data unit) that is transmitted through a TLS/SSL connection includes a sequence number. The receiver verifies this sequence number before accepting the record, which also defends against replay or injection attacks.
-
Key Exchange Mechanisms: Secure key exchange mechanisms, like the Diffie-Hellman algorithm, are used to securely exchange keys, thwarting attempts to predict or brute-force the encryption keys.
By using these various tools and techniques, TLS and SSL can provide a robust defense against various attacks, including the injection of forged overlapping packets.
-
1.4. Example
node-0:~$ telnet github.io 80
Trying 185.199.108.153...
Connected to github.io.
Escape character is '^]'.
^]
telnet> q
Connection closed.node-0:~$ sudo tcpdump -ntSv host github.io
IP (tos 0x10, ttl 64, id 29406, offset 0, flags [DF], proto TCP (6), length 60)
192.168.91.128.51610 > 185.199.108.153.80: Flags [S], cksum 0x42b8 (incorrect -> 0xd5cf), seq 2440985640, win 64240, options [mss 1460,sackOK,TS val 1617951924 ecr 0,nop,wscale 7], length 0
IP (tos 0x0, ttl 128, id 44533, offset 0, flags [none], proto TCP (6), length 44)
185.199.108.153.80 > 192.168.91.128.51610: Flags [S.], cksum 0x11dd (correct), seq 1194142207, ack 2440985641, win 64240, options [mss 1460], length 0
IP (tos 0x10, ttl 64, id 29407, offset 0, flags [DF], proto TCP (6), length 40)
192.168.91.128.51610 > 185.199.108.153.80: Flags [.], cksum 0x42a4 (incorrect -> 0x299a), ack 1194142208, win 64240, length 0
IP (tos 0x10, ttl 64, id 29408, offset 0, flags [DF], proto TCP (6), length 40)
192.168.91.128.51610 > 185.199.108.153.80: Flags [F.], cksum 0x42a4 (incorrect -> 0x2999), seq 2440985641, ack 1194142208, win 64240, length 0
IP (tos 0x0, ttl 128, id 44534, offset 0, flags [none], proto TCP (6), length 40)
185.199.108.153.80 > 192.168.91.128.51610: Flags [.], cksum 0x299a (correct), ack 2440985642, win 64239, length 0
IP (tos 0x0, ttl 128, id 44535, offset 0, flags [none], proto TCP (6), length 40)
185.199.108.153.80 > 192.168.91.128.51610: Flags [FP.], cksum 0x2991 (correct), seq 1194142208, ack 2440985642, win 64239, length 0
IP (tos 0x10, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 40)
192.168.91.128.51610 > 185.199.108.153.80: Flags [.], cksum 0x2998 (correct), ack 1194142209, win 64240, length 01.5. Timeout of Connection Establishment
There are several circumstances in which a connection cannot be established. One obvious case is when the server host is down.
To simulate this scenario, we issue our telnet command to a nonexistent host in the same subnet.
-
If we do this without modifying the ARP table, the client exits with a "No route to host" error message, generated because no ARP reply is ever returned for the ARP request.
-
If, however, we place an ARP entry for a nonexistent host in the ARP table first, the ARP request is not sent, and the system immediately attempts to contact the nonexistent host with TCP/IP. First, the commands:
node-0:~$ sudo ip neigh add 192.168.91.120 lladdr 00:00:1a:1b:1c:1d dev ens32Here the MAC address
00:00:1a:1b:1c:1dwas chosen simply as a MAC address not being used on the LAN; it is of no special consequence. -
The timeout occurs about 2 minutes after the initial command.
node-0:~$ time telnet 192.168.91.120 80 Trying 192.168.91.120... telnet: Unable to connect to remote host: Connection timed out real 2m11.038s user 0m0.002s sys 0m0.001s -
Because there is no host to respond, all of the segments generated are from the client.
node-0:~$ sudo tcpdump -ntttSvv host 192.168.91.120 00:00:00.000000 IP (tos 0x10, ttl 64, id 28344, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.128.47586 > 192.168.91.120.80: Flags [S], cksum 0x3878 (incorrect -> 0xb088), seq 54668487, win 64240, options [mss 1460,sackOK,TS val 1492721928 ecr 0,nop,wscale 7], length 0 00:00:01.018720 IP (tos 0x10, ttl 64, id 28345, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.128.47586 > 192.168.91.120.80: Flags [S], cksum 0x3878 (incorrect -> 0xac8d), seq 54668487, win 64240, options [mss 1460,sackOK,TS val 1492722947 ecr 0,nop,wscale 7], length 0 00:00:02.016512 IP (tos 0x10, ttl 64, id 28346, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.128.47586 > 192.168.91.120.80: Flags [S], cksum 0x3878 (incorrect -> 0xa4ad), seq 54668487, win 64240, options [mss 1460,sackOK,TS val 1492724963 ecr 0,nop,wscale 7], length 0 00:00:04.096269 IP (tos 0x10, ttl 64, id 28347, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.128.47586 > 192.168.91.120.80: Flags [S], cksum 0x3878 (incorrect -> 0x94ad), seq 54668487, win 64240, options [mss 1460,sackOK,TS val 1492729059 ecr 0,nop,wscale 7], length 0 00:00:08.191479 IP (tos 0x10, ttl 64, id 28348, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.128.47586 > 192.168.91.120.80: Flags [S], cksum 0x3878 (incorrect -> 0x74ad), seq 54668487, win 64240, options [mss 1460,sackOK,TS val 1492737251 ecr 0,nop,wscale 7], length 0 00:00:16.128796 IP (tos 0x10, ttl 64, id 28349, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.128.47586 > 192.168.91.120.80: Flags [S], cksum 0x3878 (incorrect -> 0x35ac), seq 54668487, win 64240, options [mss 1460,sackOK,TS val 1492753380 ecr 0,nop,wscale 7], length 0 00:00:34.047254 IP (tos 0x10, ttl 64, id 28350, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.128.47586 > 192.168.91.120.80: Flags [S], cksum 0x3878 (incorrect -> 0xb0ac), seq 54668487, win 64240, options [mss 1460,sackOK,TS val 1492787427 ecr 0,nop,wscale 7], length 0
The number of times to retry an initial SYN can be configured on some systems. In Linux,
-
the system configuration variable
net.ipv4.tcp_syn_retriesgives the maximum number of times to attempt to resend a SYN segment during an active open. -
A corresponding value called
net.ipv4.tcp_synack_retriesgives the maximum number of times to attempt to resend a SYN + ACK segment when responding to a peer’s active open request. -
It can also be used on an individual connection basis by setting the Linux-specific TCP_SYNCNT socket option.
node-0:~$ sudo sysctl net.ipv4.tcp_syn_retries net.ipv4.tcp_synack_retries net.ipv4.tcp_syn_retries = 6 net.ipv4.tcp_synack_retries = 5 node-0:~$ man 7 tcp ... TCP_SYNCNT (since Linux 2.4) Set the number of SYN retransmits that TCP should send before aborting the attempt to connect. It cannot exceed 255. This option should not be used in code intended to be portable.
2. TCP Options
The only options defined in the original TCP specification are the End of Option List (EOL), the No Operation (NOP), and the Maximum Segment Size (MSS) options.
| Kind | Length | Name | Reference | Description and Purpose |
|---|---|---|---|---|
0 |
1 |
EOL |
[RFC0793] |
End of Option List |
1 |
1 |
NOP |
[RFC0793] |
No Operation (used for padding) |
2 |
4 |
MSS |
[RFC0793] |
Maximum Segment Size |
3 |
3 |
WSOPT/WSCALE |
[RFC1323] |
Window Scaling Factor (left-shift amount on window) |
4 |
2 |
SACK-Permitted |
[RFC2018] |
Sender supports SACK options |
5 |
Var. |
SACK |
[RFC2018] |
SACK block (out-of-order data received) |
8 |
10 |
TSOPT |
[RFC1323] |
Timestamps option |
28 |
4 |
UTO |
[RFC5482] |
User Timeout (abort after idle time) |
29 |
Var. |
TCP-AO |
[RFC5925] |
Authentication option (using various algorithms) |
253 |
Var. |
Experimental |
[RFC4727] |
Reserved for experimental use |
254 |
Var. |
Experimental |
[RFC4727] |
Reserved for experimental use |
-
Every option begins with a 1-byte kind that specifies the type of option.
-
Options that are not understood are simply ignored, according to [RFC1122].
-
The options with a kind value of 0 and 1 occupy a single byte.
-
The other options have a len byte that follows the kind byte. The length is the total length, including the kind and len bytes.
-
The reason for the NOP option is to allow the sender to pad fields to a multiple of 4 bytes, if it needs to.
Remember that the TCP header’s length is always required to be a multiple of 32 bits because the TCP Header Length field uses that unit.
-
The EOL option indicates the end of the list and that no further processing of the options list is to be performed.
2.1. Maximum Segment Size (MSS) Option
The maximum segment size (MSS) is the largest segment that a TCP is willing to receive from its peer and, consequently, the largest size its peer should ever use when sending.
-
The MSS value counts only TCP data bytes and does not include the sizes of any associated TCP or IP header [RFC0879].
-
When a connection is established, each end usually announces its MSS in an MSS option carried with its SYN segment.
-
The option allows for 16 bits to be used to specify the MSS value.
-
If no MSS option is provided, a default value of 536 bytes is used.
Recall the rule that requires any host to be capable of processing IPv4 datagrams at least as large as 576.
With minimum-size IPv4 and TCP headers, a TCP using a sending MSS size of 536 bytes produces an IPv4 datagram of size 20 + 20 + 536 = 576 bytes.
-
The MSS value 1460 is typical for IPv4.
The resulting IPv4 datagram is normally 40 bytes larger (1500 bytes total, the typical MTU size for Ethernet and path MTU for the Internet): 20 bytes for the TCP header and 20 bytes for the IPv4 header.
-
When IPv6 is used, the MSS is usually 1440, 20 bytes less because of the larger IPv6 header.
The special MSS value of 65535 can be used with IPv6 jumbograms to indicate an effective MSS of infinity [RFC2675].
In this case the SMSS will be determined as the PMTU minus 60 bytes (40 bytes for the IPv6 header and 20 bytes for the TCP header).
-
Note that the MSS option is not a negotiation between one TCP and its peer; it is a limit.
When one TCP gives its MSS option to the other, it is indicating its unwillingness to accept any segments larger than that size for the duration of the connection.
* The Maximum Segment Size (MSS) is an option in TCP (Transmission Control Protocol) that specifies the largest amount of data, specified in bytes, that a computer or communications device can receive in a single TCP segment. It does not count the TCP header or the IP header (unlike the MTU for IP datagrams).
The MSS can be used to control the maximum amount of data that can be packed into each packet. This limit can help to avoid IP fragmentation, where IP datagrams are divided into smaller packets to fit the maximum transmission unit (MTU) of the network.
The MSS is usually negotiated between the sender and receiver during the TCP three-way handshake process. It’s sent in the form of a TCP option in the initial SYN packet from each host.
The value of MSS is typically determined by the maximum transmission unit (MTU) size of the data link layer of the networks to which the sender and receiver are connected, minus the size of the TCP and IP headers. For Ethernet, which has a default MTU of 1500 bytes, the MSS turns out to be 1460 bytes (1500 bytes - 20 bytes IP header - 20 bytes TCP header).
Please note that different networks may have different MTU values, so MSS can vary accordingly.
2.2. Selective Acknowledgment (SACK) Options
Because it uses cumulative ACKs, TCP with a sliding window is never able to acknowledge data it has received correctly but that is not contiguous, in terms of sequence numbers, with data it has received previously.
-
In such cases, the TCP receiver is said to have holes in its received data queue.
-
A receiving TCP prevents applications from consuming data beyond a hole because of the byte stream abstraction it provides.
If a TCP sender were able to learn of the existence of holes (and out-of-sequence data blocks beyond holes in the sequence space) at the receiver, it could better select which particular TCP segments to retransmit when segments are lost or otherwise missing at the receiver.
-
The TCP selective acknowledgment (SACK) options [RFC2018][RFC2883] provide this capability.
-
The scheme works effectively, however, only if the TCP sender logic is able to make effective use of the SACK information it receives from a SACK-capable receiver.
-
A TCP learns that its peer is capable of advertising SACK information by receiving the SACK-Permitted option in a SYN (or SYN + ACK) segment.
-
Once this has taken place, the TCP receiving out-of-sequence data may provide a SACK option that describes the out-of-sequence data to help its peer perform retransmissions more efficiently.
SACK information contained in a SACK option consists of a range of sequence numbers representing data blocks the receiver has successfully received.
-
Each range is called a SACK block and is represented by a pair of 32-bit sequence numbers.
-
Thus, a SACK option containing n SACK blocks is (8n + 2) bytes long. Two bytes are used to hold the kind and length of the SACK option.
-
Because of the limited amount of space available in the option space of a TCP header, the maximum number of SACK blocks available to be sent in a single segment is three (assuming the Timestamps option is also used, which is typical for modern TCP implementations).
-
Although the SACK-Permitted option is only ever sent in a SYN segment, the SACK blocks themselves may be sent in any segment once the sender has sent the SACK-Permitted option.
-
The operation of SACK is most easily (and importantly) related to the error and congestion control operations of TCP.
2.3. Window Scale (WSCALE or WSOPT) Option
The Window Scale option (denoted WSCALE or WSOPT) [RFC1323] effectively increases the capacity of the TCP Window Advertisement field from 16 to about 30 bits.
TCP Window Scale Option (WSopt):
Kind: 3 Length: 3 bytes
+---------+---------+---------+
| Kind=3 |Length=3 |shift.cnt|
+---------+---------+---------+Instead of changing the field size, however, the header still holds a 16-bit value, and an option is defined that applies a scaling factor to the 16-bit value.
-
This factor effectively left-shifts the window field value by the scale factor (the shift.cnt bits).
This, in effect, multiplies the window value by the value 2s, where s is the scale factor.
-
The 1-byte shift count is between 0 and 14 (inclusive).
-
A shift count of 0 indicates no scaling.
-
The maximum scale value of 14 provides for a maximum window of 1,073,725,440 bytes (65,535 × 214), close to 1,073,741,823 (230 −1), effectively 1GB.
TCP then maintains the real window size internally as a 32-bit value.
-
This option can appear only in a SYN segment, so the scale factor is fixed in each direction when the connection is established.
-
To enable window scaling, both ends must send the option in their SYN segments.
-
The end doing the active open sends the option in its SYN, but the end doing the passive open can send the option only if the received SYN specifies the option.
-
The scale factor can be different in each direction.
If the end doing the active open sends a nonzero scale factor but does not receive a Window Scale option from the other end, it sets its send and receive scale values to 0.
This lets systems that do not understand the option interoperate with systems that do.
Assume we are using the Window Scale option, with a shift count of S for sending and a shift count of R for receiving.
-
Then every 16-bit advertised window that we receive from the other end is left-shifted by R bits to obtain the real advertised window size.
-
Every time we send a window advertisement to the other end, we take our real 32-bit window size and right-shift it S bits, placing the resulting 16-bit value in the TCP header.
The shift count is automatically chosen by TCP, based on the size of the receive buffer. The size of this buffer is set by the system, but the capability is normally provided for the application to change it.
The Window Scale option is most relevant when TCP is used to provide bulk data transfer over networks with large-bandwidth-delay products (i.e., those with a product of round-trip time and bandwidth being relatively large).
IP (tos 0xc0, ttl 200, id 64132, offset 0, flags [DF], proto TCP (6), length 52, bad cksum 0 (->f66f)!)
10.170.109.10.50979 > 175.24.154.66.443: Flags [S], cksum 0xc135 (incorrect -> 0x82a4), seq 3917970949, win 64240, options [mss 1460,nop,wscale 8,nop,nop,sackOK], length 0
IP (tos 0x20, ttl 52, id 0, offset 0, flags [DF], proto TCP (6), length 52)
175.24.154.66.443 > 10.170.109.10.50979: Flags [S.], cksum 0xdacf (correct), seq 2258807318, ack 3917970950, win 29200, options [mss 1440,nop,nop,sackOK,nop,wscale 7], length 0
IP (tos 0xc0, ttl 200, id 64133, offset 0, flags [DF], proto TCP (6), length 40, bad cksum 0 (->f67a)!)
10.170.109.10.50979 > 175.24.154.66.443: Flags [.], cksum 0xc129 (incorrect -> 0x8b99), ack 2258807319, win 517, length 0
The win field in the tcpdump output represents the unscaled advertised window size as it appears in the TCP header, not the actual real window size.
|
2.4. Timestamps Option and Protection against Wrapped Sequence Numbers (PAWS)
The Timestamps option (sometimes called the Timestamp option and written as TSOPT or TSopt) lets the sender place two 4-byte timestamp values in every segment.
The receiver reflects these values in the acknowledgment, allowing the sender to calculate an estimate of the connection’s RTT for each ACK received.
-
We must say "each ACK received" and not "each segment" because TCP often acknowledges multiple segments per ACK.
-
When using the Timestamps option,
-
the sender places a 32-bit value in the Timestamp Value field (called TSV or TSval) in the first part of the TSOPT, and
-
the receiver echoes this back unchanged in the second Timestamp Echo Retry field (called TSER or TSecr).
-
-
TCP headers containing this option increase by 10 bytes (8 bytes for the two timestamp values and 2 to indicate the option value and length).
-
The timestamp is a monotonically increasing value.
-
Because the receiver simply echoes what it receives, it does not care what the timestamp units or values actually are.
-
This option does not require any form of clock synchronization between the two hosts.
-
[RFC1323] recommends that the sender increment the timestamp value by at least 1 every second.
-
The main reason for wishing to calculate a good estimate of the connection’s RTT is to set the retransmission timeout, which tells TCP when it should try resending a segment that is likely lost.
-
With the Timestamps option, we can get relatively fine-grain measurements of the RTT.
-
Prior to the creation of the Timestamps option, most TCPs would perform just one RTT sample per window of data.
-
With the Timestamps option, more samples can be taken, leading to the potential of a better RTT estimate (see [RFC1323] and [RFC6298]).
The Timestamps option allows for more frequent RTT samples, but it also provides a way for the receiver to avoid receiving old segments and considering them as valid, which is called Protection Against Wrapped Sequence Numbers (PAWS), and it is described in [RFC1323] along with the Timestamps option.
2.5. User Timeout (UTO) Option
The User Timeout (UTO) option is a relatively new TCP capability described in [RFC5482]. The UTO value (also called USER_TIMEOUT) specifies the amount of time a TCP sender is willing to wait for an ACK of outstanding data before concluding that the remote end has failed.
USER_TIMEOUT has traditionally been a local configuration parameter for TCP [RFC0793]. The UTO option allows one TCP to signal its USER_TIMEOUT value to its connection peer. This allows the receiving TCP to adjust its behavior (e.g., to tolerate a longer period of disrupted connectivity prior to aborting a connection). NAT devices could also interpret such information to help set their connection activity timers.
UTO option values are advisory; just because one end of a connection might wish to use a large or small UTO value does not mean that the other end needs to comply.
UTO options are included on SYN segments when a connection is established, on the first non-SYN segments, and whenever the USER_TIMEOUT value is changed. The option value is expressed as a 15-bit value in units of seconds or minutes following a bit field (granularity) that indicates that the value is in minutes (1) or seconds (0). As a relatively new option, it is not yet widely deployed.
2.6. Authentication Option (TCP-AO)
There is an option used to enhance the security of TCP connections. It is designed to enhance and replace an earlier mechanism called TCP-MD5 [RFC2385]. Called the TCP Authentication Option (TCP-AO) [RFC5925], it uses a cryptographic hash algorithm, in combination with a secret value known to each end of a TCP connection, to authenticate each segment.
TCP-AO improves upon TCP-MD5 by supporting a variety of cryptographic algorithms and identifying changing of keys using in-band signaling. It does not provide a comprehensive key management solution, however. That is, each end still has to have a way to establish a shared set of keys prior to operation.
However, because it requires creation and distribution of a shared key (and is a relatively new option), it is not yet widely deployed.
3. Path MTU Discovery with TCP
The path MTU is the minimum MTU on any network segment that is currently in the path between two hosts.
-
Knowing the path MTU can help protocols such as TCP avoid fragmentation.
-
The discovering of the path MTU (PMTUD) is accomplished based on ICMP messages.
We shall use the ICMPv6 Packet Too Big (PTB) terminology to refer to either ICMPv4 Destination Unreachable (Fragmentation Required) or ICMPv6 Packet Too Big messages.
A method that avoids the use of ICMP, called Packetization Layer Path MTU Discovery (PLPMTUD), can also be used by TCP [RFC4821] or by other transport protocols.
-
UDP is not usually able to adapt its datagram size because the application specifies the size (i.e., not the transport protocol).
TCP, in providing the byte stream abstraction it implements, determines what segment size to use and as a result has a much greater degree of control over the size of IP datagrams that are ultimately generated.
TCP’s regular PMTUD process operates as follows:
-
When a connection is established, TCP uses the minimum of the MTU of the outgoing interface, or the MSS announced by the other end, as the basis for selecting its send maximum segment size (SMSS).
-
PMTUD does not allow TCP to exceed the MSS announced by the other end.
-
If the other end does not specify an MSS, the sender assumes a default of 536 bytes, but this situation is now rare.
-
It is also possible for an implementation to save path MTU information on a per-destination basis to help in selecting its segment size.
-
Note that the path MTU in each direction of a connection could be different.
-
Once the initial SMSS is chosen, all IPv4 datagrams sent by TCP on that connection have the IPv4 DF bit field set.
For TCP/IPv6, this is not necessary because there is no DF bit field; all datagrams are assumed to have it set implicitly.
-
If a PTB is received, TCP decreases the segment size and retransmits using a different segment size.
If the PTB contains the suggested next-hop MTU, the segment size can be set to the next-hop MTU minus the sizes of the IPv4 (or IPv6) and TCP headers.
If the next-hop MTU value is not present (e.g., an older ICMP error was returned that lacks this information), the sender may try a variety of values (e.g., binary-search for a usable value).
This also affects TCP’s congestion control management.
-
For PLPMTUD the situation is similar, except PTB messages are not used.
Instead, the protocol performing PMTUD must be able to detect message discards quickly and perform its own datagram size adjustments.
-
Because routes can change dynamically, when some time has passed since the last decrease of the segment size, a larger value (up to the initial SMSS) can be tried.
Guidance in [RFC1191] and [RFC1981] recommends that this time interval be about 10 minutes.
There are a number of problems with PMTUD when it operates in an Internet environment with firewalls that block PTB messages [RFC2923].
Of the various operational problems with PMTUD, black holes have been the most problematic, although the situation is improving (in [LS10], 80% of systems studied were able to properly process PTB messages).
PMTUD black holes arise when a TCP implementation that depends on the delivery of ICMP messages to adjust its segment size never receives them.
-
This could be for several reasons, including a firewall or NAT configuration that prohibits such ICMP messages from being forwarded.
-
The consequence is a TCP connection that cannot proceed once it starts to use larger packets.
-
It can be difficult to diagnose because only large packets cannot be forwarded.
The smaller ones (such as SYN and SYN + ACK packets used to establish the connection) generally succeed.
Some TCP implementations have black hole detection, which amounts to trying a smaller segment size when a segment is retransmitted several times.
We can see the correct behavior of PMTUD when an intermediate router has an MTU less than either of the endpoints’ MSS.
-
Use
node-1(a Linux host with local address192.168.91.137) as a router, disable the router send_redirects, and reduce the MTU from 1500 to 512 bytes.node-1:~$ sudo sysctl net.ipv4.ip_forward=1 net.ipv4.ip_forward = 1 node-1:~$ sudo sysctl net.ipv4.conf.all.send_redirects=0 net.ipv4.conf.all.send_redirects = 0 node-1:~$ sudo sysctl net.ipv4.conf.ens32.send_redirects=0 net.ipv4.conf.ens32.send_redirects = 0 node-1:~$ sudo ip link set ens32 mtu 512 node-1:~$ ip link show ens32 2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 512 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 00:0c:29:85:26:07 brd ff:ff:ff:ff:ff:ff -
Set the default gateway of host
node-0to the intermediate routernode-1.In addition, we need to tell the client host (
node-0) that small segments are allowed:node-0:~$ sudo sysctl net.ipv4.route.min_pmtu=68If we did not perform the operation, Linux would clamp its minimum path MTU at the default value of 552 bytes, which helps avoid certain small MTU attacks .
The consequence of doing so in our example here is that any packets larger than 512 bytes would be fragmented.
Most modern operating systems support some form of network offloading, where some network processing happens on the NIC instead of the CPU. [OFFLOADING][SOWE][LAB15]
Normally this is a great thing. It can free up resources on the rest of the system and let it handle more connections.
If you’re trying to capture traffic it can result in false errors and strange or even missing traffic.
Some cards can reassemble traffic. This will manifest itself in Tcpdump/Wireshark as packets that are larger than expected, such as a 2900-byte packet on a network with a 1500-byte MTU.
To disable TCP Segmentation Offload (TSO) for a network device
ens32issue:node-0:~$ sudo ethtool -K ens32 tso offnode-0:~$ ip r default via 192.168.91.2 dev ens32 192.168.91.0/24 dev ens32 proto kernel scope link src 192.168.91.128 node-0:~$ sudo ip r del default node-0:~$ sudo ip r add default via 192.168.91.137 dev ens32 node-0:~$ ip r default via 192.168.91.137 dev ens32 192.168.91.0/24 dev ens32 proto kernel scope link src 192.168.91.128 node-0:~$ sudo sysctl net.ipv4.route.min_pmtu net.ipv4.route.min_pmtu = 552 node-0:~$ sudo sysctl net.ipv4.route.min_pmtu=68 net.ipv4.route.min_pmtu = 68 node-0:~$ sudo ethtool -k ens32 Features for ens32: rx-checksumming: off tx-checksumming: on tx-checksum-ipv4: off [fixed] tx-checksum-ip-generic: on tx-checksum-ipv6: off [fixed] tx-checksum-fcoe-crc: off [fixed] tx-checksum-sctp: off [fixed] scatter-gather: on tx-scatter-gather: on tx-scatter-gather-fraglist: off [fixed] tcp-segmentation-offload: on tx-tcp-segmentation: on tx-tcp-ecn-segmentation: off [fixed] tx-tcp-mangleid-segmentation: off tx-tcp6-segmentation: off [fixed] ... node-0:~$ sudo ethtool -K ens32 tso off -
Send a larger packet of with data size 500 bytes
The max tcp segment size will be 512 - 20 (IP header) - 20 (TCP header) = 472, that is the 500 bytes will be fragmented to two segments. node-0:~$ head -c 500 /dev/random | nc -v windows.home 6666 Ncat: Version 7.80 ( https://nmap.org/ncat ) Ncat: Connected to 10.170.109.10:6666. Ncat: 500 bytes sent, 0 bytes received in 0.01 seconds. node-0:~$ ip r get 10.170.109.10 10.170.109.10 via 192.168.91.137 dev ens32 src 192.168.91.128 uid 1000 cache expires 502sec mtu 512 -
The path MTU discovery mechanism finds an appropriate segment size to use when transiting the network where the middle link has a smaller MTU than the endpoints.
node-0:~$ sudo tcpdump -tnv port 6666 or icmp -i ens32 tcpdump: listening on ens32, link-type EN10MB (Ethernet), snapshot length 262144 bytes IP (tos 0x0, ttl 64, id 34352, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.128.34196 > 10.170.109.10.6666: Flags [S], cksum 0x940b (incorrect -> 0x590e), seq 3025740589, win 64240, options [mss 1460,sackOK,TS val 2055433851 ecr 0,nop,wscale 7], length 0 IP (tos 0x0, ttl 63, id 34352, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.128.34196 > 10.170.109.10.6666: Flags [S], cksum 0x590e (correct), seq 3025740589, win 64240, options [mss 1460,sackOK,TS val 2055433851 ecr 0,nop,wscale 7], length 0 IP (tos 0x0, ttl 128, id 65296, offset 0, flags [none], proto TCP (6), length 44) 10.170.109.10.6666 > 192.168.91.128.34196: Flags [S.], cksum 0xfe8e (correct), seq 1730751594, ack 3025740590, win 64240, options [mss 1460], length 0 IP (tos 0x0, ttl 64, id 34353, offset 0, flags [DF], proto TCP (6), length 40) 192.168.91.128.34196 > 10.170.109.10.6666: Flags [.], cksum 0x93f7 (incorrect -> 0x164c), ack 1, win 64240, length 0 IP (tos 0x0, ttl 64, id 34354, offset 0, flags [DF], proto TCP (6), length 540) 192.168.91.128.34196 > 10.170.109.10.6666: Flags [P.], cksum 0x95eb (incorrect -> 0xe838), seq 1:501, ack 1, win 64240, length 500 IP (tos 0x0, ttl 64, id 34355, offset 0, flags [DF], proto TCP (6), length 40) 192.168.91.128.34196 > 10.170.109.10.6666: Flags [F.], cksum 0x93f7 (incorrect -> 0x1457), seq 501, ack 1, win 64240, length 0 IP (tos 0x0, ttl 63, id 34353, offset 0, flags [DF], proto TCP (6), length 40) 192.168.91.128.34196 > 10.170.109.10.6666: Flags [.], cksum 0x164c (correct), ack 1, win 64240, length 0 IP (tos 0xc0, ttl 64, id 9583, offset 0, flags [none], proto ICMP (1), length 512) 192.168.91.137 > 192.168.91.128: ICMP 10.170.109.10 unreachable - need to frag (mtu 512), length 492 IP (tos 0x0, ttl 64, id 34354, offset 0, flags [DF], proto TCP (6), length 540) 192.168.91.128.34196 > 10.170.109.10.6666: Flags [P.], seq 1:501, ack 1, win 64240, length 500 IP (tos 0x0, ttl 63, id 34355, offset 0, flags [DF], proto TCP (6), length 40) 192.168.91.128.34196 > 10.170.109.10.6666: Flags [F.], cksum 0x1457 (correct), seq 501, ack 1, win 64240, length 0 IP (tos 0x0, ttl 128, id 65297, offset 0, flags [none], proto TCP (6), length 40) 10.170.109.10.6666 > 192.168.91.128.34196: Flags [.], cksum 0x164c (correct), ack 1, win 64240, length 0 IP (tos 0x0, ttl 64, id 34356, offset 0, flags [DF], proto TCP (6), length 512) 192.168.91.128.34196 > 10.170.109.10.6666: Flags [.], cksum 0x95cf (incorrect -> 0x1464), seq 1:473, ack 1, win 64240, length 472 IP (tos 0x0, ttl 64, id 34357, offset 0, flags [DF], proto TCP (6), length 68) 192.168.91.128.34196 > 10.170.109.10.6666: Flags [P.], cksum 0x9413 (incorrect -> 0xe848), seq 473:501, ack 1, win 64240, length 28 IP (tos 0x0, ttl 63, id 34356, offset 0, flags [DF], proto TCP (6), length 540) 192.168.91.128.34196 > 10.170.109.10.6666: Flags [P.], cksum 0x95eb (incorrect -> 0xe838), seq 1:501, ack 1, win 64240, length 500 IP (tos 0x0, ttl 128, id 65298, offset 0, flags [none], proto TCP (6), length 40) 10.170.109.10.6666 > 192.168.91.128.34196: Flags [.], cksum 0x1474 (correct), ack 473, win 64240, length 0 IP (tos 0x0, ttl 128, id 65299, offset 0, flags [none], proto TCP (6), length 40) 10.170.109.10.6666 > 192.168.91.128.34196: Flags [.], cksum 0x1458 (correct), ack 502, win 64239, length 0 IP (tos 0x0, ttl 128, id 65300, offset 0, flags [none], proto TCP (6), length 40) 10.170.109.10.6666 > 192.168.91.128.34196: Flags [FP.], cksum 0x144f (correct), seq 1, ack 502, win 64239, length 0 IP (tos 0x0, ttl 64, id 34358, offset 0, flags [DF], proto TCP (6), length 40) 192.168.91.128.34196 > 10.170.109.10.6666: Flags [.], cksum 0x93f7 (incorrect -> 0x1457), ack 2, win 64239, length 0 IP (tos 0x0, ttl 63, id 34358, offset 0, flags [DF], proto TCP (6), length 40) 192.168.91.128.34196 > 10.170.109.10.6666: Flags [.], cksum 0x1457 (correct), ack 2, win 64239, length 0
4. TCP State Transitions
The rules which types of segments are sent during different phases of a TCP connection that determine what TCP does are determined by what state TCP is in.
The current state is changed based on various stimuli, such as segments that are transmitted or received, timers that expire, application reads or writes, or information from other layers.
These rules can be summarized in TCP’s state transition diagram.
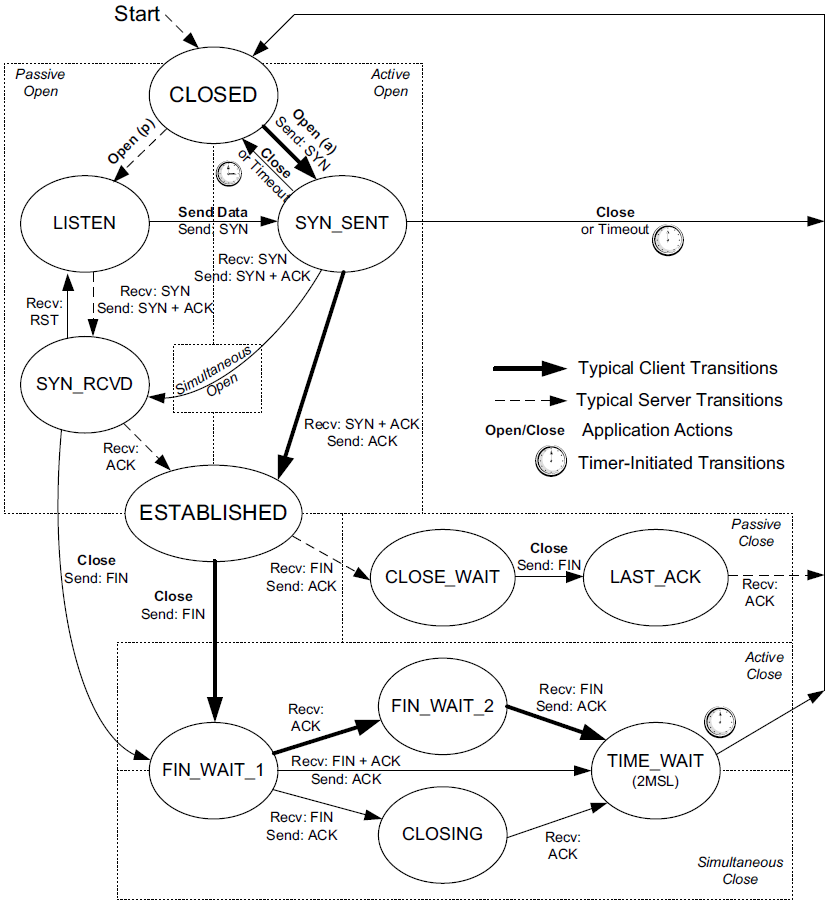
-
States are indicated by ovals and transitions between states by arrows. Each endpoint of a connection transitions through the states.
-
The state CLOSED is not really an official state but has been added as a useful starting point and ending point for the diagram.
-
The names of the 11 states (CLOSED, LISTEN, SYN_SENT, etc.) are based on the names output by the
netstatcommand in UNIX, Linux, and Windows, which are themselves based on the names originally used in [RFC0793].node-0:~$ netstat -nat4 Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 127.0.0.1:6015 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:6020 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:6019 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:6018 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:54043 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:4000 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:44363 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:35729 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:54043 127.0.0.1:42982 TIME_WAIT tcp 0 0 192.168.91.128:35729 192.168.91.1:58032 ESTABLISHED tcp 0 172 192.168.91.128:22 192.168.91.1:62703 ESTABLISHED tcp 0 0 192.168.91.128:35729 192.168.91.1:58042 ESTABLISHED tcp 0 0 192.168.91.128:35729 192.168.91.1:58034 ESTABLISHED tcp 0 0 192.168.91.128:35729 192.168.91.1:58036 ESTABLISHED tcp 0 0 127.0.0.1:54043 127.0.0.1:43022 FIN_WAIT2 tcp 0 0 192.168.91.128:35729 192.168.91.1:58043 ESTABLISHED tcp 0 0 127.0.0.1:54043 127.0.0.1:43038 TIME_WAIT tcp 0 0 192.168.91.128:22 192.168.91.1:62518 ESTABLISHED tcp 0 0 127.0.0.1:54043 127.0.0.1:43026 TIME_WAIT tcp 0 0 127.0.0.1:54043 127.0.0.1:43006 FIN_WAIT2 tcp 1 0 127.0.0.1:43022 127.0.0.1:54043 CLOSE_WAIT tcp 0 0 127.0.0.1:54043 127.0.0.1:42998 FIN_WAIT2 tcp 0 0 192.168.91.128:35729 192.168.91.1:58044 ESTABLISHED tcp 0 0 192.168.91.128:22 192.168.91.1:62227 ESTABLISHED tcp 0 0 192.168.91.128:35729 192.168.91.1:58041 ESTABLISHED tcp 1 0 127.0.0.1:42998 127.0.0.1:54043 CLOSE_WAIT tcp 0 0 192.168.91.128:22 192.168.91.1:62684 ESTABLISHED tcp 3 0 127.0.0.1:43006 127.0.0.1:54043 CLOSE_WAIT node-0:~$ ss -nat4 State Recv-Q Send-Q Local Address:Port Peer Address:Port Process LISTEN 0 128 127.0.0.1:6015 0.0.0.0:* LISTEN 0 128 127.0.0.1:6020 0.0.0.0:* LISTEN 0 128 127.0.0.1:6019 0.0.0.0:* LISTEN 0 128 127.0.0.1:6018 0.0.0.0:* LISTEN 0 5 127.0.0.1:54043 0.0.0.0:* LISTEN 0 128 0.0.0.0:22 0.0.0.0:* LISTEN 0 4096 0.0.0.0:4000 0.0.0.0:* LISTEN 0 4096 127.0.0.1:44363 0.0.0.0:* LISTEN 0 100 0.0.0.0:35729 0.0.0.0:* TIME-WAIT 0 0 127.0.0.1:54043 127.0.0.1:42982 ESTAB 0 0 192.168.91.128:35729 192.168.91.1:58032 ESTAB 0 0 192.168.91.128:22 192.168.91.1:62703 ESTAB 0 0 192.168.91.128:35729 192.168.91.1:58042 ESTAB 0 0 192.168.91.128:35729 192.168.91.1:58034 ESTAB 0 0 192.168.91.128:35729 192.168.91.1:58036 FIN-WAIT-2 0 0 127.0.0.1:54043 127.0.0.1:43022 ESTAB 0 0 192.168.91.128:35729 192.168.91.1:58043 TIME-WAIT 0 0 127.0.0.1:54043 127.0.0.1:43038 ESTAB 0 0 192.168.91.128:22 192.168.91.1:62518 TIME-WAIT 0 0 127.0.0.1:54043 127.0.0.1:43026 FIN-WAIT-2 0 0 127.0.0.1:54043 127.0.0.1:43006 CLOSE-WAIT 1 0 127.0.0.1:43022 127.0.0.1:54043 FIN-WAIT-2 0 0 127.0.0.1:54043 127.0.0.1:42998 ESTAB 0 0 192.168.91.128:35729 192.168.91.1:58044 ESTAB 0 0 192.168.91.128:22 192.168.91.1:62227 ESTAB 0 0 192.168.91.128:35729 192.168.91.1:58041 CLOSE-WAIT 1 0 127.0.0.1:42998 127.0.0.1:54043 ESTAB 0 0 192.168.91.128:22 192.168.91.1:62684 CLOSE-WAIT 3 0 127.0.0.1:43006 127.0.0.1:54043PS C:\> netstat -na -p tcp Active Connections Proto Local Address Foreign Address State TCP 0.0.0.0:912 0.0.0.0:0 LISTENING TCP 0.0.0.0:5040 0.0.0.0:0 LISTENING TCP 10.170.109.10:60502 10.171.95.148:7680 SYN_SENT TCP 127.0.0.1:49805 0.0.0.0:0 LISTENING TCP 127.0.0.1:58165 127.0.0.1:60480 TIME_WAIT TCP 127.0.0.1:58165 127.0.0.1:60481 TIME_WAIT TCP 127.0.0.1:60461 127.0.0.1:58165 TIME_WAIT TCP 127.0.0.1:65123 0.0.0.0:0 LISTENING TCP 169.254.24.54:139 0.0.0.0:0 LISTENING
4.1. TIME_WAIT (2MSL Wait) State
The TIME_WAIT state is also called the 2MSL wait state, which is a state in which TCP waits for a time equal to twice the Maximum Segment Lifetime (MSL), sometimes called timed wait. It is the maximum amount of time any segment can exist in the network before being discarded.
[RFC0793] specifies the MSL as 2 minutes. Common implementation values, however, are 30s, 1 minute, or 2 minutes.
-
On Linux, the value
net.ipv4.tcp_fin_timeoutholds the 2MSL wait timeout value (in seconds). -
On Windows, the following registry key:
HKLM\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\TcpTimedWaitDelayholds the timeout. It is permitted to be in the range of 30 to 300s. For IPv6, replace the term Tcpip with Tcpip6.
Given the MSL value for an implementation, the rule is: When TCP performs an active close and sends the final ACK, that connection must stay in the TIME_WAIT state for twice the MSL. This lets TCP resend the final ACK in case it is lost.
-
The final ACK is resent not because the TCP retransmits ACKs (they do not consume sequence numbers and are not retransmitted by TCP), but because the other side will retransmit its FIN (which does consume a sequence number).
-
Indeed, TCP will always retransmit FINs until it receives a final ACK.
Another effect of this 2MSL wait state is that while the TCP implementation waits, the endpoints defining that connection cannot be reused. That connection defined by the address/port 4-tuple can be reused
-
only when the 2MSL wait is over, or
-
when a new connection uses an ISN that exceeds the highest sequence number used on the previous instantiation of the connection [RFC1122], or
-
if the use of the Timestamps option allows the disambiguation of segments from a previous connection instantiation to not otherwise be confused [RFC6191].
Unfortunately, some implementations impose a more stringent constraint. In these systems, a local port number cannot be reused while that port number is the local port number of any endpoint that is in the 2MSL wait state on the system.
Most implementations and APIs provide a way to bypass this restriction.
With the Berkeley sockets API, the SO_REUSEADDR socket option enables the bypass operation.
-
It lets the caller assign itself a local port number even if that port number is part of some connection in the 2MSL wait state.
-
We will see, however, that even with this bypass mechanism for one socket (address, port number pair), the rules of TCP still (should) prevent this port number from being reused by another instantiation of the same connection that is in the 2MSL wait state.
-
Any delayed segments that arrive for a connection while it is in the 2MSL wait state are discarded.
Because the connection defined by the address/port 4-tuple in the 2MSL wait state cannot be reused during this time period, when a valid connection is finally established, we know that delayed segments from an earlier instantiation of this connection cannot be misinterpreted as being part of the new connection.
For interactive applications, it is normally the client that does the active close and enters the TIME_WAIT state. The server usually does the passive close and does not go through the TIME_WAIT state.
-
The implication is that if we terminate a client, and restart the same client immediately, that new client cannot reuse the same local port number.
This is not ordinarily a problem, because clients normally use ephemeral ports assigned by the operating system and do not care what the assigned port number is.
Recall, it is actually a recommended practice for them to be randomized for security reasons [RFC6056].
This is important to know because a client that makes a large number of connections quickly (especially to the same server) could conceivably have to delay while other connections terminate if ephemeral ports are in short supply.
-
If we terminate a server process that has a connection established and immediately try to restart it, the server cannot assign its well-knonw assigned port number to its endpoint (it gets an Address already in use binding error), because that port number is part of a connection that is in a 2MSL wait state.
It may take from 1 to 4 minutes for the server to be able to restart, depending on the local system’s value for the MSL.
|
The TCP TIME_WAIT state has a couple of major purposes:
So while TIME_WAIT does eventually help release the port, its primary roles are to guarantee a reliable connection shutdown and to prevent confusion between old and new connections. |
Both |
|
2MSL (Maximum Segment Lifetime)
Represents the estimated maximum time a segment can exist in the network.
|
4.2. Quiet Time Concept
The 2MSL wait provides protection against delayed segments from an earlier instantiation of a connection being interpreted as part of a new connection that uses the same local and foreign IP addresses and port numbers. But this works only if a host with connections in the 2MSL wait does not crash.
What if a host with connections in the TIME_WAIT state crashes, reboots within the MSL, and immediately establishes new connections using the same local and foreign IP addresses and port numbers corresponding to the local connections that were in the TIME_WAIT state before the crash? In this scenario, delayed segments from the connections that existed before the crash can be misinterpreted as belonging to the new connections created after the reboot. This can happen regardless of how the initial sequence number is chosen after the reboot.
To protect against this scenario, [RFC0793] states that TCP should wait an amount of time equal to the MSL before creating any new connections after a reboot or crash. This is called the quiet time. Few implementations abide by this because most hosts take longer than the MSL to reboot after a crash. Also, if applications use their own checksums or encryption, errors such as these are easily detected.
4.3. FIN_WAIT_2 State
In the FIN_WAIT_2 state, TCP has sent a FIN and the other end has acknowledged it.
-
Unless a half-close is being performed, the TCP must wait for the application on the other end to recognize that it has received an end-of-file notification and close its end of the connection, which causes a FIN to be sent.
-
Only when the application performs this close (and its FIN is received) does the active closing TCP move from the FIN_WAIT_2 to the TIME_WAIT state.
-
This means that one end of the connection can remain in this state forever.
-
The other end is still in the CLOSE_WAIT state and can remain there forever, until the application decides to issue its close.
Many implementations prevent this infinite wait in the FIN_WAIT_2 state as follows:
-
If the application that does the active close does a complete close, not a half-close indicating that it expects to receive data, a timer is set.
-
If the connection is idle when the timer expires, TCP moves the connection into the CLOSED state.
In Linux, the variable net.ipv4.tcp_fin_timeout can be adjusted to control the number of seconds to which the timer is set. Its default value is 60s.
4.4. Simultaneous Open and Close Transitions
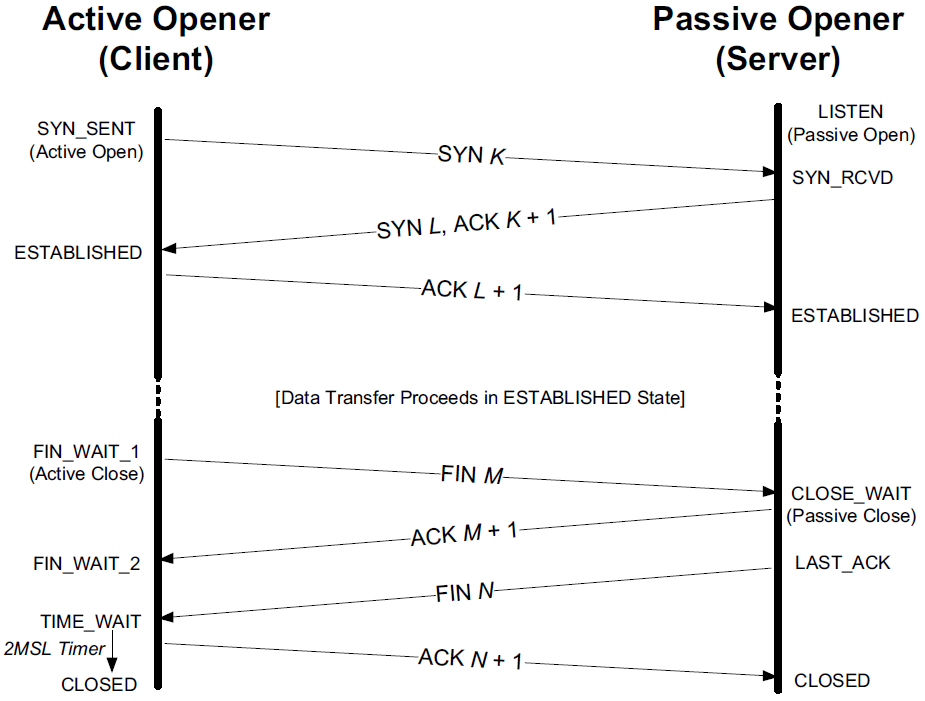
We have seen the normal uses for the SYN_SENT and SYN_RCVD states that correspond to sending and receiving SYN segments, respectively. As illustrated in Figure 13-3, TCP was purposely designed to handle simultaneous opens that result in a single connection.
When a simultaneous open occurs, both ends send a SYN at about the same time, entering the SYN_SENT state.
-
When each end receives its peer’s SYN segments, the state changes to SYN_RCVD, and each end resends a SYN and acknowledges the received SYN.
-
When each end receives the SYN plus the ACK, the state changes to ESTABLISHED.
For a simultaneous close, both ends go from ESTABLISHED to FIN_WAIT_1 when the application issues the close. This causes both FINs to be sent, and they probably pass each other somewhere in the network.
-
When its peer’s FIN arrives, each end transitions from FIN_WAIT_1 to the CLOSING state, and each endpoint sends its final ACK.
-
Upon receiving a final ACK, each endpoint’s state changes to TIME_WAIT, and the 2MSL wait is initiated.
5. Reset Segments
A segment having RST bit set to on is called a reset segment or simply a reset. In general, a reset is sent by TCP whenever a segment arrives that does not appear to be correct for the referenced connection specified by the 4-tuple of the reset.
Resets ordinarily result in a fast teardown of a TCP connection.
5.1. Connection Request to Nonexistent Port
A common case for generating a reset segment is when a connection request arrives and no process is listening on the destination port.
node-0:~$ telnet localhost 9999
Trying ::1...
Trying 127.0.0.1...
telnet: Unable to connect to remote host: Connection refusednode-0:~$ sudo tcpdump -i lo -ntSv
IP6 (flowlabel 0x3ea4c, hlim 64, next-header TCP (6) payload length: 40) ::1.46796 > ::1.9999: Flags [S], cksum 0x0030 (incorrect -> 0x8263), seq 1025049371, win 65476, options [mss 65476,sackOK,TS val 999584289 ecr 0,nop,wscale 7], length 0
IP6 (flowlabel 0x84cda, hlim 64, next-header TCP (6) payload length: 20) ::1.9999 > ::1.46796: Flags [R.], cksum 0x001c (incorrect -> 0x91be), seq 0, ack 1025049372, win 0, length 0
IP (tos 0x10, ttl 64, id 58734, offset 0, flags [DF], proto TCP (6), length 60)
127.0.0.1.52076 > 127.0.0.1.9999: Flags [S], cksum 0xfe30 (incorrect -> 0x0b51), seq 499568435, win 65495, options [mss 65495,sackOK,TS val 2552810770 ecr 0,nop,wscale 7], length 0
IP (tos 0x10, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 40)
127.0.0.1.9999 > 127.0.0.1.52076: Flags [R.], cksum 0xd257 (correct), seq 0, ack 499568436, win 0, length 0Because the ACK bit field was not on in the arriving SYN segment, the sequence number of the reset is set to 0 and the ACK number is set to the incoming ISN plus the number of data bytes in the segment.
5.2. Aborting a Connection
The normal way to terminate a connection is for one side to send a FIN, which is sometimes called an orderly release because the FIN is sent after all previously queued data has been sent, and there is normally no loss of data. But it is also possible to abort a connection by sending a reset instead of a FIN at any time which is sometimes called an abortive release.
Aborting a connection provides two features to the application:
-
(1) any queued data is thrown away and a reset segment is sent immediately, and
-
(2) the receiver of the reset can tell that the other end did an abort instead of a normal close.
The API being used by the application must provide a way to generate the abort instead of a normal close.
The sockets API provides this capability by using the linger on close socket option (SO_LINGER) with a 0 linger value, which essentially this means Linger for no time in making sure data gets to the other side, then abort.
In the following example, we show what happens when a remote command that generates a large amount of output is canceled by the user:
node-0:~$ ssh -4 -i .ssh/id_rsa.localhost localhost cat /usr/share/dict/words
...
Austerlitz's
Austin
Austi^Cnode-0:~$ sudo tcpdump -i lo -ntSv
IP (tos 0x0, ttl 64, id 25152, offset 0, flags [DF], proto TCP (6), length 60)
127.0.0.1.56842 > 127.0.0.1.22: Flags [S], cksum 0xfe30 (incorrect -> 0x0ce7), seq 3840402379, win 65495, options [mss 65495,sackOK,TS val 2560361386 ecr 0,nop,wscale 7], length 0
IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 60)
127.0.0.1.22 > 127.0.0.1.56842: Flags [S.], cksum 0xfe30 (incorrect -> 0xde8a), seq 4193097762, ack 3840402380, win 65483, options [mss 65495,sackOK,TS val 2560361386 ecr 2560361386,nop,wscale 7], length 0
IP (tos 0x0, ttl 64, id 25153, offset 0, flags [DF], proto TCP (6), length 52)
127.0.0.1.56842 > 127.0.0.1.22: Flags [.], cksum 0xfe28 (incorrect -> 0x0547), ack 4193097763, win 512, options [nop,nop,TS val 2560361386 ecr 2560361386], length 0
...
IP (tos 0x8, ttl 64, id 25186, offset 0, flags [DF], proto TCP (6), length 112)
127.0.0.1.56842 > 127.0.0.1.22: Flags [P.], cksum 0xfe64 (incorrect -> 0x1b78), seq 3840405884:3840405944, ack 4193659175, win 19379, options [nop,nop,TS val 2560361552 ecr 2560361552], length 60
IP (tos 0x8, ttl 64, id 15367, offset 0, flags [DF], proto TCP (6), length 16472)
127.0.0.1.22 > 127.0.0.1.56842: Flags [P.], cksum 0x3e4d (incorrect -> 0x04b1), seq 4193659175:4193675595, ack 3840405944, win 512, options [nop,nop,TS val 2560361554 ecr 2560361552], length 16420
IP (tos 0x8, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 40)
127.0.0.1.56842 > 127.0.0.1.22: Flags [R], cksum 0xfd1c (correct), seq 3840405944, win 0, length 0
IP (tos 0x8, ttl 64, id 25187, offset 0, flags [DF], proto TCP (6), length 52)
127.0.0.1.56842 > 127.0.0.1.22: Flags [R.], cksum 0xfe28 (incorrect -> 0x1b48), seq 3840405944, ack 4193659175, win 19379, options [nop,nop,TS val 2560361555 ecr 2560361552], length 05.3. TCP reset attack
TCP reset attack, also known as a "forged TCP reset" or "spoofed TCP reset", is a way to terminate a TCP connection by sending a forged TCP reset packet. This tampering technique can be used by a firewall or abused by a malicious attacker to interrupt Internet connections. [RSTATTACK]
The Great Firewall of China, and Iranian Internet censors are known to use TCP reset attacks to interfere with and block connections, as a major method to carry out Internet censorship.
node-0:~$ sudo sysctl net.ipv4.tcp_syn_retries=12
net.ipv4.tcp_syn_retries = 12node-0:~$ curl https://www.google.com
curl: (7) Failed to connect to www.google.com port 443: Connection refusednode-0:~$ sudo tcpdump -ntSv host www.google.com
tcpdump: listening on ens32, link-type EN10MB (Ethernet), snapshot length 262144 bytes
IP (tos 0x0, ttl 64, id 47240, offset 0, flags [DF], proto TCP (6), length 60)
192.168.91.128.60460 > 104.244.43.228.443: Flags [S], cksum 0xb12f (incorrect -> 0x3f20), seq 510666909, win 64240, options [mss 1460,sackOK,TS val 4143788283 ecr 0,nop,wscale 7], length 0
IP (tos 0x0, ttl 64, id 47241, offset 0, flags [DF], proto TCP (6), length 60)
192.168.91.128.60460 > 104.244.43.228.443: Flags [S], cksum 0xb12f (incorrect -> 0x3b2e), seq 510666909, win 64240, options [mss 1460,sackOK,TS val 4143789293 ecr 0,nop,wscale 7], length 0
IP (tos 0x0, ttl 64, id 47242, offset 0, flags [DF], proto TCP (6), length 60)
192.168.91.128.60460 > 104.244.43.228.443: Flags [S], cksum 0xb12f (incorrect -> 0x334d), seq 510666909, win 64240, options [mss 1460,sackOK,TS val 4143791310 ecr 0,nop,wscale 7], length 0
IP (tos 0x0, ttl 64, id 47243, offset 0, flags [DF], proto TCP (6), length 60)
192.168.91.128.60460 > 104.244.43.228.443: Flags [S], cksum 0xb12f (incorrect -> 0x22ee), seq 510666909, win 64240, options [mss 1460,sackOK,TS val 4143795501 ecr 0,nop,wscale 7], length 0
IP (tos 0x0, ttl 64, id 47244, offset 0, flags [DF], proto TCP (6), length 60)
192.168.91.128.60460 > 104.244.43.228.443: Flags [S], cksum 0xb12f (incorrect -> 0x02ee), seq 510666909, win 64240, options [mss 1460,sackOK,TS val 4143803693 ecr 0,nop,wscale 7], length 0
IP (tos 0x0, ttl 128, id 65378, offset 0, flags [none], proto TCP (6), length 40)
104.244.43.228.443 > 192.168.91.128.60460: Flags [R.], cksum 0x3aca (correct), seq 1523136853, ack 510666910, win 64240, length 0By encrypting connections using a VPN, the attacker has to do a TCP reset attack on all encrypted connections, causing collateral damage.
node-0:~$ curl -iI -x http://windows.home:7890 https://www.google.com
HTTP/1.1 200 Connection established
HTTP/2 200
content-type: text/html; charset=ISO-8859-1
...node-0:~$ sudo tcpdump -ntSv host windows.home
IP (tos 0x0, ttl 64, id 11633, offset 0, flags [DF], proto TCP (6), length 60)
192.168.91.128.51404 > 10.170.109.10.7890: Flags [S], cksum 0x940b (incorrect -> 0x37da), seq 1111884013, win 64240, options [mss 1460,sackOK,TS val 93212920 ecr 0,nop,wscale 7], length 0
IP (tos 0x0, ttl 128, id 65434, offset 0, flags [none], proto TCP (6), length 44)
10.170.109.10.7890 > 192.168.91.128.51404: Flags [S.], cksum 0x4445 (correct), seq 1282231747, ack 1111884014, win 64240, options [mss 1460], length 0
IP (tos 0x0, ttl 64, id 11634, offset 0, flags [DF], proto TCP (6), length 40)
192.168.91.128.51404 > 10.170.109.10.7890: Flags [.], cksum 0x93f7 (incorrect -> 0x5c02), ack 1282231748, win 64240, length 0
...
192.168.91.128.51404 > 10.170.109.10.7890: Flags [F.], cksum 0x93f7 (incorrect -> 0x4687), seq 1111885022, ack 1282237698, win 62780, length 0
IP (tos 0x0, ttl 128, id 65452, offset 0, flags [none], proto TCP (6), length 40)
10.170.109.10.7890 > 192.168.91.128.51404: Flags [.], cksum 0x40d4 (correct), ack 1111885023, win 64239, length 0
IP (tos 0x0, ttl 128, id 65453, offset 0, flags [none], proto TCP (6), length 40)
10.170.109.10.7890 > 192.168.91.128.51404: Flags [FP.], cksum 0x40cb (correct), seq 1282237698, ack 1111885023, win 64239, length 0
IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 40)
192.168.91.128.51404 > 10.170.109.10.7890: Flags [.], cksum 0x4686 (correct), ack 1282237699, win 62780, length 05.4. Half-Open Connections
A TCP connection is said to be half-open if one end has closed or aborted the connection without the knowledge of the other end.
-
This can happen anytime one of the peers crashes.
-
As long as there is no attempt to transfer data across a half-open connection, the end that is still up does not detect that the other end has crashed.
Another common cause of a half-open connection is when one host is powered off instead of shut down properly. This happens, for example,
-
when PCs are being used to run remote login clients and are switched off at the end of the day.
-
If there was no data transfer going on when the power was cut, the server will never know that the client disappeared (it would still think the connection is in the ESTABLISHED state).
-
When the user comes in the next morning, powers on the PC, and starts a new session, a new occurrence of the server is started on the server host.
-
This can lead to many half-open TCP connections on the server host.
We can easily create a half-open connection. In this case, we do so on the client rather than the server.
-
We will execute the Telnet client on
node-0, connecting to the SSH Service server atnode-1. -
We type one line of input and watch it go across with
tcpdump, and then we disconnect the Ethernet cable on the server’s host and reboot the server host. This simulates the server host crashing.We disconnect the Ethernet cable before rebooting the server to prevent it from sending a FIN out of the open connections, which some TCPs do when they are shut down.
-
After the server has rebooted, we reconnect the cable and try to send another line from the client to the server.
-
After rebooting, the server’s TCP has lost all memory of the connections that existed before, so it knows nothing about the connection that the data segment references. The rule of TCP is that the receiver responds with a reset.
node-0:~$ telnet node-1 22 Trying 192.168.91.137... Connected to node-1.localdomain. Escape character is '^]'. SSH-2.0-OpenSSH_7.9p1 Debian-10+deb10u2 heloo Connection closed by foreign host.# Disconnect the Ethernet cable on the server’s host and reboot the server host. node-1:~$ sudo ip link set ens32 down && sudo rebootnode-0:~$ sudo tcpdump -tSnv host node-1 and tcp IP (tos 0x10, ttl 64, id 39857, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.128.34128 > 192.168.91.137.22: Flags [S], cksum 0x3889 (incorrect -> 0xa161), seq 3124448828, win 64240, options [mss 1460,sackOK,TS val 2395494060 ecr 0,nop,wscale 7], length 0 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.137.22 > 192.168.91.128.34128: Flags [S.], cksum 0xab81 (correct), seq 2701748454, ack 3124448829, win 65160, options [mss 1460,sackOK,TS val 177003962 ecr 2395494060,nop,wscale 7], length 0 IP (tos 0x10, ttl 64, id 39858, offset 0, flags [DF], proto TCP (6), length 52) 192.168.91.128.34128 > 192.168.91.137.22: Flags [.], cksum 0x3881 (incorrect -> 0xd6df), ack 2701748455, win 502, options [nop,nop,TS val 2395494061 ecr 177003962], length 0 IP (tos 0x0, ttl 64, id 39639, offset 0, flags [DF], proto TCP (6), length 93) 192.168.91.137.22 > 192.168.91.128.34128: Flags [P.], cksum 0x4dc3 (correct), seq 2701748455:2701748496, ack 3124448829, win 510, options [nop,nop,TS val 177003967 ecr 2395494061], length 41: SSH: SSH-2.0-OpenSSH_7.9p1 Debian-10+deb10u2 IP (tos 0x10, ttl 64, id 39859, offset 0, flags [DF], proto TCP (6), length 52) 192.168.91.128.34128 > 192.168.91.137.22: Flags [.], cksum 0x3881 (incorrect -> 0xd6ac), ack 2701748496, win 502, options [nop,nop,TS val 2395494066 ecr 177003967], length 0 ... heloo ... IP (tos 0x10, ttl 64, id 39860, offset 0, flags [DF], proto TCP (6), length 59) 192.168.91.128.34128 > 192.168.91.137.22: Flags [P.], cksum 0x3888 (incorrect -> 0x58ae), seq 3124448829:3124448836, ack 2701748496, win 502, options [nop,nop,TS val 2395571902 ecr 177003967], length 7 IP (tos 0x10, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 40) 192.168.91.137.22 > 192.168.91.128.34128: Flags [R], cksum 0xe805 (correct), seq 2701748496, win 0, length 0
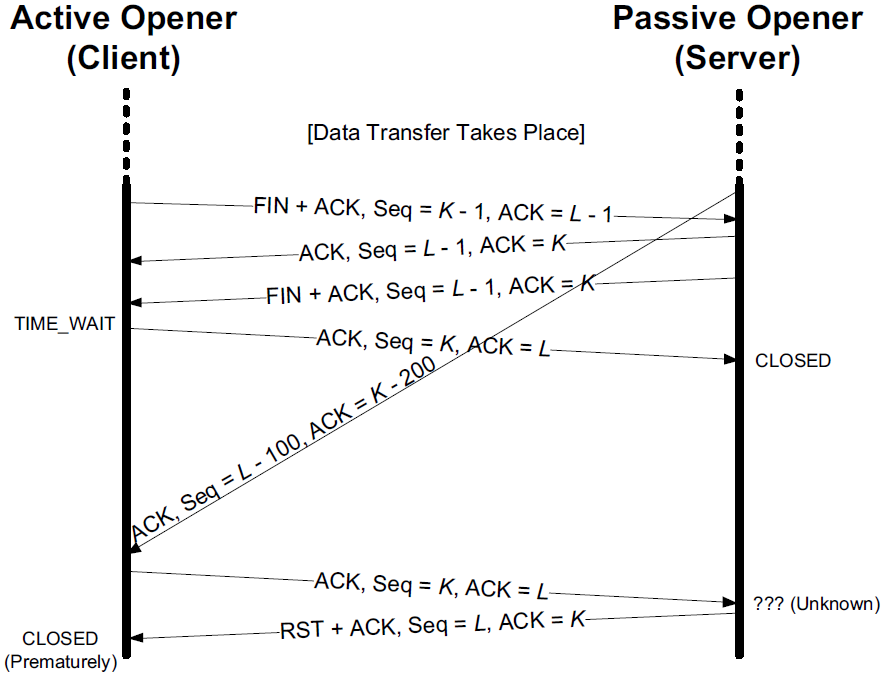
5.5. TIME-WAIT Assassination (TWA)
During TIME-WAIT state period, the waiting TCP usually has little to do; it merely holds the state until the 2MSL timer expires.
If, however, it receives certain segments from the connection during this period, or more specifically an RST segment, it can become desynchronized. This is called TIME-WAIT Assassination (TWA) [RFC1337].
6. TCP Server Operation
When a new connection request arrives at a server, the server accepts the connection and invokes a new process or thread to handle the new client concurrently.
6.1. TCP Port Numbers
We shall watch the secure shell server (called sshd) using the netstat command on a dual-stack IPv4/IPv6-capable host. The following output is on a system with no active secure shell connections.
node-0:~$ netstat -nat
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp6 0 0 :::22 :::* LISTEN-
The local address (which really means local endpoint) is output as
0.0.0.0:22and:::22, which are the IPv4/IPv6-oriented ways of referring to the all-zeros address, also called the wildcard address, along with port number 22. This means that an incoming connection request (i.e., a SYN) to port 22 will be accepted on any local interface.If the host were multihomed (this one is), we could specify a single IP address for the local IP address (one of the host’s IP addresses), and only connections received on that interface would be accepted.
Port 22 is the well-known port number reserved for the Secure Shell Protocol.
-
The foreign address is output as
0.0.0.0:*and:::*, which mean both a wildcard address and port number (i.e., it represents a wildcard endpoint).Here, the foreign IP address and foreign port number are not known yet, because the local endpoint is in the LISTEN state, waiting for a connection to arrive.
We now start a secure shell client on the host through a NAT 192.168.91.1 that connects to this server.
node-0:~$ netstat -n -t -a
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 172 192.168.91.128:22 192.168.91.1:52094 ESTABLISHED
tcp6 0 0 :::22 :::* LISTEN-
The second line for port 22 is the ESTABLISHED connection.
All four elements of the local and foreign endpoints are filled in for this connection: the local IP address and port number, and the foreign IP address and port number.
The local IP address corresponds to the interface on which the connection request arrived (the Ethernet interface, identified by address,
192.168.91.128). -
The local endpoint in the LISTEN state is left alone.
This is the endpoint that the concurrent server uses to accept future connection requests. It is the TCP module in the operating system that creates the new endpoint in the ESTABLISHED state, when the incoming connection request arrives and is accepted.
-
Also notice that the port number for the ESTABLISHED connection does not change: it is 22, the same as the LISTEN endpoint.
We now initiate another client request from the same system (192.168.91.1) to this server. Here is the relevant netstat output:
node-0:~$ netstat -nta
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 0 192.168.91.128:22 192.168.91.1:52408 ESTABLISHED
tcp 0 0 192.168.91.128:22 192.168.91.1:52094 ESTABLISHED
tcp6 0 0 :::22 :::* LISTEN6.2. Restricting Local IP Addresses
We can see what happens when the server does not wildcard the local IP address but instead sets it to one particular local address. If we run our nc program as a server and provide it with a particuclar IP address, that address becomes the local address of the listening endpoint. For example:
node-0:~$ ip a s ens32
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:8c:df:3f brd ff:ff:ff:ff:ff:ff
altname enp2s0
inet 192.168.91.128/24 brd 192.168.91.255 scope global ens32
valid_lft forever preferred_lft forever
inet 192.168.91.129/24 brd 192.168.91.255 scope global secondary ens32
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe8c:df3f/64 scope link
valid_lft forever preferred_lft forever
node-0:~$ nc -kvl 192.168.91.128 8888
Ncat: Version 7.80 ( https://nmap.org/ncat )
Ncat: Listening on 192.168.91.128:8888
Ncat: Connection from 192.168.91.137.
Ncat: Connection from 192.168.91.137:56918.If we instead try to connect to this server from a host using a destination address other than 192.168.91.128 (even including the local address 127.0.0.1), the connection request is not accepted by the TCP module, meanwhile the server application never sees the connection request.
node-1:~$ nc 192.168.91.128 8888
^C
node-1:~$ nc 192.168.91.129 8888
Ncat: Connection refused.node-0:~$ nc 127.0.0.1 8888
Ncat: Connection refused.If we watch with tcpdump, the SYN elicits an RST segment.
node-0:~$ sudo tcpdump -ntSv -i any port 8888 and tcp
ens32 In IP (tos 0x0, ttl 64, id 42898, offset 0, flags [DF], proto TCP (6), length 60)
192.168.91.137.38142 > 192.168.91.128.8888: Flags [S], cksum 0x12bf (correct), seq 244930047, win 64240, options [mss 1460,sackOK,TS val 1592493755 ecr 0,nop,wscale 7], length 0
ens32 Out IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 60)
192.168.91.128.8888 > 192.168.91.137.38142: Flags [S.], cksum 0x3889 (incorrect -> 0x21bc), seq 2513818259, ack 244930048, win 65160, options [mss 1460,sackOK,TS val 3269837322 ecr 1592493755,nop,wscale 7], length 0
ens32 In IP (tos 0x0, ttl 64, id 42899, offset 0, flags [DF], proto TCP (6), length 52)
192.168.91.137.38142 > 192.168.91.128.8888: Flags [.], cksum 0x4d1b (correct), ack 2513818260, win 502, options [nop,nop,TS val 1592493755 ecr 3269837322], length 0
ens32 In IP (tos 0x0, ttl 64, id 42900, offset 0, flags [DF], proto TCP (6), length 52)
192.168.91.137.38142 > 192.168.91.128.8888: Flags [F.], cksum 0x47b3 (correct), seq 244930048, ack 2513818260, win 502, options [nop,nop,TS val 1592495138 ecr 3269837322], length 0
ens32 Out IP (tos 0x0, ttl 64, id 22157, offset 0, flags [DF], proto TCP (6), length 52)
192.168.91.128.8888 > 192.168.91.137.38142: Flags [F.], cksum 0x3881 (incorrect -> 0x4242), seq 2513818260, ack 244930049, win 510, options [nop,nop,TS val 3269838706 ecr 1592495138], length 0
ens32 In IP (tos 0x0, ttl 64, id 42901, offset 0, flags [DF], proto TCP (6), length 52)
192.168.91.137.38142 > 192.168.91.128.8888: Flags [.], cksum 0x4249 (correct), ack 2513818261, win 502, options [nop,nop,TS val 1592495139 ecr 3269838706], length 0
ens32 In IP (tos 0x0, ttl 64, id 49077, offset 0, flags [DF], proto TCP (6), length 60)
192.168.91.137.52334 > 192.168.91.129.8888: Flags [S], cksum 0x9ff0 (correct), seq 268676780, win 64240, options [mss 1460,sackOK,TS val 1836145019 ecr 0,nop,wscale 7], length 0
ens32 Out IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 40)
192.168.91.129.8888 > 192.168.91.137.52334: Flags [R.], cksum 0xc99d (correct), seq 0, ack 268676781, win 0, length 0
lo In IP (tos 0x0, ttl 64, id 27559, offset 0, flags [DF], proto TCP (6), length 60)
127.0.0.1.39402 > 127.0.0.1.8888: Flags [S], cksum 0xfe30 (incorrect -> 0x7bca), seq 1179089949, win 65495, options [mss 65495,sackOK,TS val 2152518883 ecr 0,nop,wscale 7], length 0
lo In IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 40)
127.0.0.1.8888 > 127.0.0.1.39402: Flags [R.], cksum 0x32c6 (correct), seq 0, ack 1179089950, win 0, length 06.3. Restricting Foreign Endpoints
The abstract interface functions for TCP given in [RFC0793] allow a server doing a passive open to have either a fully specified foreign endpoint (to wait for a particular client to issue an active open) or an unspecified foreign endpoint (to wait for any client).
Unfortunately, the ordinary Berkeley sockets API does not provide a way to do this. The server must leave the client’s endpoint unspecified, wait for the connection to arrive, and then examine the IP address and port number of the client.
| Local Address | Foreign Address | Restricted to | Comment |
|---|---|---|---|
|
|
One client |
Not usually supported |
|
|
One local endpoint |
Unusual (used by DNS servers) |
|
|
One local port |
Most common; multiple address families (IPv4/IPv6) may be supported |
6.4. Incoming Connection Queue
A concurrent server invokes a new process or thread to handle each client, so the listening server should always be ready to handle the next incoming connection request. That is the underlying reason for using concurrent servers.
But there is still a chance that multiple connection requests will arrive
-
while the listening server is creating a new process, or
-
while the operating system is busy running other higher-priority processes, or worse yet, that
-
the server is being attacked with bogus connection requests that are never allowed to be established.
How does TCP handle these scenarios?
To fully explore this question, we must first understand that new connections may be in one of two distinct states before they are made available to an application.
-
The first case is connections that have not yet completed but for which a SYN has been received (these are in the SYN_RCVD state).
-
The second case is connections that have already completed the three-way handshake and are in the ESTABLISHED state but have not yet been accepted by the application.
An application has limited control over the sizing of these queues.
-
Traditionally, using the Berkeley sockets API, an application had only indirect control of the sum of the sizes of these two queues.
-
In modern Linux kernels this behavior has been changed to be the number of connections in the second case (ESTABLISHED connections).
The application can therefore limit the number of fully formed connections waiting for it to handle.
In Linux, then, the following rules apply:
-
When a connection request arrives (i.e., the SYN segment), the system-wide parameter
net.ipv4.tcp_max_syn_backlogis checked (default 1000).While
net.ipv4.tcp_max_syn_backloghas a default value (often 1000), its effective limit is heavily influenced by the available system memory.node-0:~$ sudo sysctl net.ipv4.tcp_max_syn_backlog net.ipv4.tcp_max_syn_backlog = 256If the number of connections in the SYN_RCVD state would exceed this threshold, the incoming connection is rejected.
-
Each listening endpoint has a fixed-length queue of connections that have been completely accepted by TCP (i.e., the three-way handshake is complete) but not yet accepted by the application.
-
The application specifies a limit to this queue, commonly called the backlog.
-
This backlog must be between
0and a system-specific maximum callednet.core.somaxconn, inclusive (default 128).While
net.core.somaxconnhas a default value (often 128), its effective limit is heavily influenced by the available system memory.node-0:~$ sudo sysctl net.core.somaxconn net.core.somaxconn = 4096 -
Keep in mind that this backlog value specifies only the maximum number of queued connections for one listening endpoint, all of which have already been accepted by TCP and are waiting to be accepted by the application.
-
This backlog has no effect whatsoever on the maximum number of established connections allowed by the system, or on the number of clients that a concurrent server can handle concurrently.
-
-
If there is room on this listening endpoint’s queue for this new connection, the TCP module ACKs the SYN and completes the connection.
-
The server application with the listening endpoint does not see this new connection until the third segment of the three-way handshake is received.
-
Also, the client may think the server is ready to receive data when the client’s active open completes successfully, before the server application has been notified of the new connection. If this happens, the server’s TCP just queues the incoming data.
-
-
If there is not enough room on the queue for the new connection, the TCP delays responding to the SYN, to give the application a chance to catch up.
Linux is somewhat unique in this behavior—it persists in not ignoring incoming connections if it possibly can.
If the
net.ipv4.tcp_abort_on_overflowsystem control variable is set, new incoming connections are reset with a reset segment.Sending reset segments on overflow is not generally advisable and is not turned on by default.
-
The client has attempted to contact the server, and if it receives a reset during the SYN exchange, it may falsely conclude that no server is present (instead of concluding that there is a server present but it is busy). Being too busy is really a form of "soft" or temporary error rather than a hard error.
-
Normally, when the queue is full, the application or the operating system is busy, preventing the application from servicing incoming connections. This condition could change in a short while.
-
But if the server’s TCP responded with a reset, the client’s active open would abort (which is what we saw happen if the server was not started).
-
Without the reset, if the listening server does not get around to accepting some of the already-accepted connections that have filled its queue to the limit, the client’s active open eventually times out, according to normal TCP mechanisms. In the case of Linux, the connecting clients are just slowed for a significant period of time—they will neither time out nor be reset.
Show backlog.c
// backlog.c #include <arpa/inet.h> #include <stdbool.h> #include <stdio.h> #include <sys/socket.h> #include <unistd.h> #define MAXPENDING 1 // backlog #define SERV_PORT 6666 int main(void) { int serv_sock = -1; struct sockaddr_in serv_addr; serv_addr.sin_family = AF_INET; /* Internet address family */ serv_addr.sin_addr.s_addr = htonl(INADDR_ANY); /* Any incoming interface */ serv_addr.sin_port = htons(SERV_PORT); /* Local port */ do { /* Create a TCP socket */ /* Create socket for incoming connections */ if ((serv_sock = socket(PF_INET, SOCK_STREAM, IPPROTO_TCP)) < 0) { perror("socket() failed"); break; } /* Assign a port to socket */ if (bind(serv_sock, (struct sockaddr *) &serv_addr, sizeof(serv_addr)) < 0) { perror("bind() failed"); break; } /* Set socket to listen */ /* Mark the socket so it will listen for incoming connections */ if (listen(serv_sock, MAXPENDING) < 0) { perror("listen() failed"); break; } char *addrp; if (inet_ntop(AF_INET, &(serv_addr.sin_addr), addrp, sizeof(serv_addr)) == NULL) { perror("inet_ntop() failed"); break; } printf("listening: %s:%d.\n", addrp, SERV_PORT); sleep(60*60*25); // sleep 1 day without any accepting } while (false); if (serv_sock != -1) { close(serv_sock); } }node-0:~$ gcc backlog.c node-0:~$ ./a.out listening: 0.0.0.0:6666.node-0:~$ netstat -nt4l Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:6666 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTENnode-1:~$ telnet 192.168.91.128 6666 Trying 192.168.91.128... Connected to 192.168.91.128. Escape character is '^]'.node-1:~$ telnet 192.168.91.128 6666 Trying 192.168.91.128... Connected to 192.168.91.128. Escape character is '^]'.We try to start a third whose SYN appears as segment 7 (port 49598), but the server-side TCP ignores the SYNs because the queue for this listening endpoint is full. The client retransmits its SYN in segments 8–13 using binary exponential backoff.
node-1:~$ telnet 192.168.91.128 6666 Trying 192.168.91.128... telnet: Unable to connect to remote host: Connection timed outnode-0:~$ ss -ntl4 State Recv-Q Send-Q Local Address:Port Peer Address:Port Process LISTEN 2 1 0.0.0.0:6666 0.0.0.0:* LISTEN 0 128 0.0.0.0:22 0.0.0.0:* node-0:~$ netstat -nta4 Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 2 0 0.0.0.0:6666 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN tcp 0 0 192.168.91.128:6666 192.168.91.137:47352 ESTABLISHED tcp 0 0 192.168.91.128:6666 192.168.91.137:54366 ESTABLISHED* Both
ssandnetstatare Linux utilities used to investigate sockets and provide information about network connections.The Recv-Q and Send-Q columns in the
ssornetstatoutput have specific meanings:-
Recv-Q: Represents the count of bytes not copied by the user program connected to this socket. In other words, these are the bytes that have been received from the network, acknowledged, but not yet read by the application. If this field is continuously growing, it could indicate that the application is not keeping up with the data coming in.
-
Send-Q: Represents the count of bytes not acknowledged by the remote host. These bytes are the ones sent by the application but not yet acknowledged by the other end of the connection or not yet sent out on the network because of congestion control mechanisms. If this field is growing, it can indicate network problems or a slow receiver.
You can use these fields to help diagnose network or application performance issues. If either queue is consistently growing, this could indicate a bottleneck or issue with your network or application performance.
The Linux server accepts two connections immediately. Subsequent connections receive no response and eventually time out at the client.
Show tcpdump trace
node-0:~$ sudo tcpdump -tttSnvv port 6666 -i ens32 00:00:00.000000 IP (tos 0x10, ttl 64, id 27519, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.137.55964 > 192.168.91.128.6666: Flags [S], cksum 0x9b9c (correct), seq 2152111340, win 64240, options [mss 1460,sackOK,TS val 1666647015 ecr 0,nop,wscale 7], length 0 00:00:00.000036 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.128.6666 > 192.168.91.137.55964: Flags [S.], cksum 0x3889 (incorrect -> 0x8908), seq 1765187368, ack 2152111341, win 65160, options [mss 1460,sackOK,TS val 3343990586 ecr 1666647015,nop,wscale 7], length 0 00:00:00.000163 IP (tos 0x10, ttl 64, id 27520, offset 0, flags [DF], proto TCP (6), length 52) 192.168.91.137.55964 > 192.168.91.128.6666: Flags [.], cksum 0xb467 (correct), seq 2152111341, ack 1765187369, win 502, options [nop,nop,TS val 1666647015 ecr 3343990586], length 0 00:00:03.103909 IP (tos 0x10, ttl 64, id 36918, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.137.55980 > 192.168.91.128.6666: Flags [S], cksum 0xfdfd (correct), seq 1592217530, win 64240, options [mss 1460,sackOK,TS val 1666650119 ecr 0,nop,wscale 7], length 0 00:00:00.000023 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.128.6666 > 192.168.91.137.55980: Flags [S.], cksum 0x3889 (incorrect -> 0xb79d), seq 1742325809, ack 1592217531, win 65160, options [mss 1460,sackOK,TS val 3343993690 ecr 1666650119,nop,wscale 7], length 0 00:00:00.000091 IP (tos 0x10, ttl 64, id 36919, offset 0, flags [DF], proto TCP (6), length 52) 192.168.91.137.55980 > 192.168.91.128.6666: Flags [.], cksum 0xe2fc (correct), seq 1592217531, ack 1742325810, win 502, options [nop,nop,TS val 1666650119 ecr 3343993690], length 0 00:00:06.974278 IP (tos 0x10, ttl 64, id 7754, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.137.49598 > 192.168.91.128.6666: Flags [S], cksum 0xbfe9 (correct), seq 2744338131, win 64240, options [mss 1460,sackOK,TS val 1666657092 ecr 0,nop,wscale 7], length 0 00:00:01.010323 IP (tos 0x10, ttl 64, id 7755, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.137.49598 > 192.168.91.128.6666: Flags [S], cksum 0xbbf6 (correct), seq 2744338131, win 64240, options [mss 1460,sackOK,TS val 1666658103 ecr 0,nop,wscale 7], length 0 00:00:02.016133 IP (tos 0x10, ttl 64, id 7756, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.137.49598 > 192.168.91.128.6666: Flags [S], cksum 0xb416 (correct), seq 2744338131, win 64240, options [mss 1460,sackOK,TS val 1666660119 ecr 0,nop,wscale 7], length 0 00:00:04.191522 IP (tos 0x10, ttl 64, id 7757, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.137.49598 > 192.168.91.128.6666: Flags [S], cksum 0xa3b6 (correct), seq 2744338131, win 64240, options [mss 1460,sackOK,TS val 1666664311 ecr 0,nop,wscale 7], length 0 00:00:08.191700 IP (tos 0x10, ttl 64, id 7758, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.137.49598 > 192.168.91.128.6666: Flags [S], cksum 0x83b6 (correct), seq 2744338131, win 64240, options [mss 1460,sackOK,TS val 1666672503 ecr 0,nop,wscale 7], length 0 00:00:16.128449 IP (tos 0x10, ttl 64, id 7759, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.137.49598 > 192.168.91.128.6666: Flags [S], cksum 0x44b6 (correct), seq 2744338131, win 64240, options [mss 1460,sackOK,TS val 1666688631 ecr 0,nop,wscale 7], length 0 00:00:33.792360 IP (tos 0x10, ttl 64, id 7760, offset 0, flags [DF], proto TCP (6), length 60) 192.168.91.137.49598 > 192.168.91.128.6666: Flags [S], cksum 0xc0b5 (correct), seq 2744338131, win 64240, options [mss 1460,sackOK,TS val 1666722423 ecr 0,nop,wscale 7], length 0 -
7. TCP SYN flood DoS attack
A SYN flood is a TCP DoS attack whereby one or more malicious clients generate a series of TCP connection attempts (SYN segments) and send them at a server, often with a spoofed (e.g., random) source IP address.
-
The server allocates some amount of connection resources to each partial connection.
-
Because the connections are never established, the server may start to deny service to future legitimate requests because its memory is exhausted holding state for many half-open connections.
One mechanism invented to deal with the SYN flood issue is called SYN cookies [RFC4987].
-
The main insight with SYN cookies is that most of the information that would be stored for a connection when a SYN arrives could be encoded inside the Sequence Number field supplied with the SYN + ACK.
-
The target machine using SYN cookies need not allocate any storage for the incoming connection request—it allocates real memory only once the SYN + ACK segment has itself been acknowledged (and the initial sequence number is returned).
-
In that case, all the vital connection parameters can be recovered and the connection can be placed in the ESTABLISHED state.
-
Producing SYN cookies involves a careful selection process of the TCP ISN at servers.
Essentially, the server must encode any essential state in the Sequence Number field in its SYN + ACK that is returned in the ACK Number field from a legitimate client.
node-0:~$ socat TCP-LISTEN:6666,fork,reuseaddr,backlog=16 -node-1:~$ sudo hping3 -c 15000 -d 120 -S -w 64 -p 6666 --flood --rand-source 192.168.91.128
HPING 192.168.91.128 (ens32 192.168.91.128): S set, 40 headers + 120 data bytes
hping in flood mode, no replies will be shownEvery 2.0s: ss -ntlao src *:6666 node-0: Tue Jan 17 14:18:42 2023
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 16 0.0.0.0:6666 0.0.0.0:*
SYN-RECV 0 0 192.168.91.128:6666 253.207.178.242:1263 timer:(on,7.796ms,4)
SYN-RECV 0 0 192.168.91.128:6666 242.132.73.92:28552 timer:(on,964ms,1)
SYN-RECV 0 0 192.168.91.128:6666 242.40.25.25:28464 timer:(on,964ms,1)
SYN-RECV 0 0 192.168.91.128:6666 253.106.78.160:28362 timer:(on,964ms,1)
SYN-RECV 0 0 192.168.91.128:6666 242.51.222.66:1282 timer:(on,7.796ms,4)
SYN-RECV 0 0 192.168.91.128:6666 241.54.238.19:1223 timer:(on,7.796ms,4)
SYN-RECV 0 0 192.168.91.128:6666 0.208.65.129:1372 timer:(on,7.796ms,4)
SYN-RECV 0 0 192.168.91.128:6666 241.21.223.166:1369 timer:(on,7.796ms,4)
SYN-RECV 0 0 192.168.91.128:6666 248.70.213.239:28376 timer:(on,964ms,1)
SYN-RECV 0 0 192.168.91.128:6666 246.188.115.108:1231 timer:(on,7.796ms,4)
SYN-RECV 0 0 192.168.91.128:6666 246.200.132.48:1203 timer:(on,7.796ms,4)
SYN-RECV 0 0 192.168.91.128:6666 242.200.4.84:28562 timer:(on,964ms,1)
SYN-RECV 0 0 192.168.91.128:6666 0.132.205.12:1237 timer:(on,7.796ms,4)
SYN-RECV 0 0 192.168.91.128:6666 241.78.102.97:28296 timer:(on,964ms,1)
SYN-RECV 0 0 192.168.91.128:6666 241.224.178.160:28432 timer:(on,964ms,1)
SYN-RECV 0 0 192.168.91.128:6666 242.241.15.118:28422 timer:(on,964ms,1)Show tcpdump trace
node-0:~$ sudo tcpdump -ntv -i ens32 port 6666 and tcp
IP (tos 0x0, ttl 64, id 63705, offset 0, flags [none], proto TCP (6), length 160)
0.196.178.163.2330 > 192.168.91.128.6666: Flags [S], cksum 0x213b (correct), seq 724690304:724690424, win 64, length 120
IP (tos 0x0, ttl 64, id 31179, offset 0, flags [none], proto TCP (6), length 160)
52.38.211.34.2331 > 192.168.91.128.6666: Flags [S], cksum 0xe51b (correct), seq 1259551603:1259551723, win 64, length 120
IP (tos 0x0, ttl 64, id 1348, offset 0, flags [none], proto TCP (6), length 160)
163.253.38.99.2332 > 192.168.91.128.6666: Flags [S], cksum 0x8b80 (correct), seq 1145231226:1145231346, win 64, length 120
IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 44)
192.168.91.128.6666 > 0.196.178.163.2330: Flags [S.], cksum 0xcfae (incorrect -> 0x5bce), seq 2338239121, ack 724690305, win 64240, options [mss 1460], length 0
IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 44)
192.168.91.128.6666 > 52.38.211.34.2331: Flags [S.], cksum 0x2390 (incorrect -> 0xa7f0), seq 1462620393, ack 1259551604, win 64240, options [mss 1460], length 0
IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 44)
192.168.91.128.6666 > 163.253.38.99.2332: Flags [S.], cksum 0xe6a7 (incorrect -> 0x44c3), seq 4096016080, ack 1145231227, win 64240, options [mss 1460], length 0
IP (tos 0x0, ttl 64, id 12576, offset 0, flags [none], proto TCP (6), length 160)
33.27.153.163.2333 > 192.168.91.128.6666: Flags [S], cksum 0xa99c (correct), seq 547114778:547114898, win 64, length 120
IP (tos 0x0, ttl 64, id 54784, offset 0, flags [none], proto TCP (6), length 160)
113.116.167.181.2334 > 192.168.91.128.6666: Flags [S], cksum 0x7af2 (correct), seq 1087648591:1087648711, win 64, length 120
IP (tos 0x0, ttl 64, id 56408, offset 0, flags [none], proto TCP (6), length 160)
244.134.115.210.2335 > 192.168.91.128.6666: Flags [S], cksum 0xa0e4 (correct), seq 2011424089:2011424209, win 64, length 120
IP (tos 0x0, ttl 64, id 11115, offset 0, flags [none], proto TCP (6), length 160)
79.107.129.40.2336 > 192.168.91.128.6666: Flags [S], cksum 0x3d4b (correct), seq 234582353:234582473, win 64, length 120
IP (tos 0x0, ttl 64, id 35935, offset 0, flags [none], proto TCP (6), length 160)
164.52.15.173.2337 > 192.168.91.128.6666: Flags [S], cksum 0x7000 (correct), seq 1320724685:1320724805, win 64, length 120
IP (tos 0x0, ttl 128, id 45741, offset 0, flags [none], proto TCP (6), length 40)
52.38.211.34.2331 > 192.168.91.128.6666: Flags [R], cksum 0x62c3 (correct), seq 1259551604, win 32767, length 0
IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 44)
192.168.91.128.6666 > 33.27.153.163.2333: Flags [S.], cksum 0xd705 (incorrect -> 0x10d7), seq 1459145616, ack 547114779, win 64240, options [mss 1460], length 0Appendix A: Segmentation Offloading
Unfortunately sometimes what we see in Wireshark is not what we expect. One case in which this occurs is when TCP/IP operations are offloaded by the operating system to the Network Interface Card (NIC). Common operations for offloading are segmentation and checksum calculations. That is, instead of the OS using the CPU to segment TCP packets, it allows the NIC to use its own processor to perform the segmentation. This saves on the CPU and importantly cuts down on the bus communications to/from the NIC. However offloading doesn’t change what is sent over the network. In other words, offloading to the NIC can produce performance gains inside your computer, but not across the network. [SOWE]
How does this affect what Wireshark captures? Consider the figure below illustrating the normal flow of data through a TCP/IP stack without offloading. Lets assume the application data is 7,300 Bytes. TCP breaks this into five segments. Why five? The Maximum Transmission Unit (MTU) of Ethernet is 1500 Bytes. If we subtract the 20 Byte IP header and 20 Byte TCP header there is 1460 Bytes remaining for data in a TCP segment (this is the TCP Maximum Segment Size (MSS)). 7,300 Bytes can be conveniently segmented into five maximum sized TCP segments.
After IP adds a header to the TCP segments the resulting IP datagrams are sent one-by-one to the "Ethernet layer". Note that TCP/IP are part of operating system, while most functionality of Ethernet is implemented on the NIC. However network drivers (lets consider them part of the OS) also perform some of the Ethernet functionality. The network driver creates/receives Ethernet frames. So in the above example, assuming segmentation offloading is not used, the 7,300 Bytes of application data is segmented into 5 TCP/IP packets containing 1460 Bytes of data each. The network driver encapsulates each IP datagram in an Ethernet frame and sends the frames to the NIC. It is these Ethernet frames that Wireshark (and other packet capture software, like tcpdump) captures. The NIC then sends the frames, one-by-one, over the network.
Now consider when segmentation offloading is used (as in the figure below). The OS does not segment the application data, but instead creates one large TCP/IP packet and sends that to the driver. The TCP and IP headers are in fact template headers. The driver creates a single Ethernet frame (which is captured by Wireshark) and sends it to the NIC. Now the NIC performs the segmentation. It uses the template headers to create 5 Ethernet frames with real TCP/IP/Ethernet headers. The 5 frames are then sent over the network.
The result: although the same 5 Ethernet frames are sent over the network, Wireshark captures different data depending on the use of segmentation offloading. When not used, the 5 Ethernet frames are captured. When offloading is used, Wireshark only captures the single, large frame (containing 7,300 bytes of data).
Queries the specified network device for the state of protocol offload and other features.
$ sudo ethtool -k ens32
Features for ens32:
rx-checksumming: off
tx-checksumming: on
tx-checksum-ipv4: off [fixed]
tx-checksum-ip-generic: on
tx-checksum-ipv6: off [fixed]
tx-checksum-fcoe-crc: off [fixed]
tx-checksum-sctp: off [fixed]
scatter-gather: on
tx-scatter-gather: on
tx-scatter-gather-fraglist: off [fixed]
tcp-segmentation-offload: on
tx-tcp-segmentation: on
tx-tcp-ecn-segmentation: off [fixed]
tx-tcp-mangleid-segmentation: off
tx-tcp6-segmentation: off [fixed]
udp-fragmentation-offload: off
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]
.....# tso on|off
# Specifies whether TCP segmentation offload should be enabled.
#
# gro on|off
# Specifies whether generic receive offload should be enabled
sudo ethtool -K ens32 tso off gro offReferences
-
[TCPIPV1] Kevin Fall, W. Stevens TCP/IP Illustrated: The Protocols, Volume 1. 2nd edition, Addison-Wesley Professional, 2011
-
[RFC1323] V. Jacobson, R. Braden, and D. Borman, TCP Extensions for High Performance, Internet RFC 1323, May 1992.
-
[RSTATTACK] https://en.wikipedia.org/wiki/TCP_reset_attack
-
[OFFLOADING] https://wiki.wireshark.org/CaptureSetup/Offloading
-
[SOWE] https://sandilands.info/sgordon/segmentation-offloading-with-wireshark-and-ethtool
-
[LAB15] http://ce.sc.edu/cyberinfra/workshops/Material/NTP/Lab%2015.pdf
-
[GSOLIB] https://doc.dpdk.org/guides/prog_guide/generic_segmentation_offload_lib.html
-
[NSO] https://docs.kernel.org/networking/segmentation-offloads.html