TCP/IP: TCP Timeout and Retransmission
To decide what data it needs to resend, TCP depends on a continuous flow of acknowledgments from receiver to sender.
When data segments or acknowledgments are lost, TCP initiates a retransmission of the data that has not been acknowledged.
TCP has two separate mechanisms for accomplishing retransmission, one based on time and one based on the structure of the acknowledgments.
-
TCP sets a timer when it sends data, and if the data is not acknowledged when the timer expires, a timeout or timer-based retransmission of data occurs.
The timeout occurs after an interval called the retransmission timeout (RTO).
-
It has another way of initiating a retransmission called fast retransmission or fast retransmit, which usually happens without any delay.
Fast retransmit is based on inferring losses by noticing
-
when TCP’s cumulative acknowledgment fails to advance in the (duplicate) ACKs received over time, or
-
when ACKs carrying selective acknowledgment information (SACKs) indicate that out-of-order segments are present at the receiver.
-
- 1. Simple Timeout and Retransmission (Time-based) Example
- 2. Setting the Retransmission Timeout (RTO)
- 3. Timer-Based Retransmission
- 4. Fast Retransmit
- 5. Retransmission with Selective Acknowledgments
- 6. Spurious Timeouts and Retransmissions
- 7. Packet Reordering and Duplication
- 8. Destination Metrics
- 9. Repacketization
- Appendix A: Dropping Packets in Linux using tc and iptables
- References
1. Simple Timeout and Retransmission (Time-based) Example
We will establish a connection, send some data to verify that everything is OK, isolate one end of the connection, send some more data, and watch what TCP does.
x@node-1:~$ nc -kl 6666x@node-0:~$ telnet node-1 6666
Trying 192.168.91.135...
Connected to node-1.localdomain.
Escape character is '^]'.
hello
Connection closed by foreign host.x@node-1:~$ sudo ip link set ens32 downx@node-0:~$ ss -nta dst *:6666
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
ESTAB 0 7 192.168.91.128:36824 192.168.91.137:6666
x@node-0:~$ netstat -nta4
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 7 192.168.91.128:36824 192.168.91.137:6666 ESTABLISHEDx@node-0:~$ sudo tcpdump -tttttSnv -i any icmp or port 6666
00:00:00.000000 ens32 Out IP (tos 0x10, ttl 64, id 26731, offset 0, flags [DF], proto TCP (6), length 60)
192.168.91.128.50688 > 192.168.91.137.6666: Flags [S], cksum 0x3889 (incorrect -> 0xc8d2), seq 1476981540, win 64240, options [mss 1460,sackOK,TS val 3360184417 ecr 0,nop,wscale 7], length 0
00:00:00.000396 ens32 In IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 60)
192.168.91.137.6666 > 192.168.91.128.50688: Flags [S.], cksum 0x34e8 (correct), seq 2021627494, ack 1476981541, win 65160, options [mss 1460,sackOK,TS val 1682840845 ecr 3360184417,nop,wscale 7], length 0
00:00:00.000462 ens32 Out IP (tos 0x10, ttl 64, id 26732, offset 0, flags [DF], proto TCP (6), length 52)
192.168.91.128.50688 > 192.168.91.137.6666: Flags [.], cksum 0x3881 (incorrect -> 0x6046), ack 2021627495, win 502, options [nop,nop,TS val 3360184418 ecr 1682840845], length 0
00:00:33.520679 ens32 Out IP (tos 0x10, ttl 64, id 26733, offset 0, flags [DF], proto TCP (6), length 59)
192.168.91.128.50688 > 192.168.91.137.6666: Flags [P.], cksum 0x3888 (incorrect -> 0x8f67), seq 1476981541:1476981548, ack 2021627495, win 502, options [nop,nop,TS val 3360217938 ecr 1682840845], length 7
...
00:00:40.385007 ens32 Out IP (tos 0x10, ttl 64, id 26739, offset 0, flags [DF], proto TCP (6), length 59)
192.168.91.128.50688 > 192.168.91.137.6666: Flags [P.], cksum 0x3888 (incorrect -> 0x7497), seq 1476981541:1476981548, ack 2021627495, win 502, options [nop,nop,TS val 3360224802 ecr 1682840845], length 7
00:00:50.113908 lo In IP (tos 0xd0, ttl 64, id 25299, offset 0, flags [none], proto ICMP (1), length 87)
192.168.91.128 > 192.168.91.128: ICMP host 192.168.91.137 unreachable, length 67
IP (tos 0x10, ttl 64, id 26740, offset 0, flags [DF], proto TCP (6), length 59)
192.168.91.128.50688 > 192.168.91.137.6666: Flags [P.], cksum 0x3888 (incorrect -> 0x5a96), seq 1476981541:1476981548, ack 2021627495, win 502, options [nop,nop,TS val 3360231459 ecr 1682840845], length 7
...
00:15:55.330154 lo In IP (tos 0xd0, ttl 64, id 7913, offset 0, flags [none], proto ICMP (1), length 87)
192.168.91.128 > 192.168.91.128: ICMP host 192.168.91.137 unreachable, length 67
IP (tos 0x10, ttl 64, id 26876, offset 0, flags [DF], proto TCP (6), length 59)
192.168.91.128.50688 > 192.168.91.137.6666: Flags [P.], cksum 0x3888 (incorrect -> 0x8a89), seq 1476981541:1476981548, ack 2021627495, win 502, options [nop,nop,TS val 3361136674 ecr 1682840845], length 7Logically, TCP has two thresholds R1 and R2 to determine how persistently it will attempt to resend the same segment [RFC1122].
-
Threshold
R1indicates the number of tries TCP will make (or the amount of time it will wait) to resend a segment before passing negative advice to the IP layer (e.g., causing it to reevaluate the IP route it is using). -
Threshold
R2(larger thanR1) dictates the point at which TCP should abandon the connection. -
R1andR2might be measured in time units or as a count of retransmissions.The value of
R1SHOULD correspond to at least 3 retransmissions, at the current RTO.The value of
R2SHOULD correspond to at least 100 seconds. -
However, the values of
R1andR2may be different for SYN and data segments.In particular,
R2for a SYN segment MUST be set large enough to provide retransmission of the segment for at least 3 minutes.
In Linux, the R1 and R2 values for regular data segments are available to be changed by applications or can be changed using the system-wide configuration variables net.ipv4.tcp_retries1 and net.ipv4.tcp_retries2, respectively.
-
These are measured in the number of retransmissions, and not in units of time.
-
The default value for
net.ipv4.tcp_retries2is 15, which corresponds roughly to 13–30 minutes, depending on the connection’s RTO. -
The default value for
net.ipv4.tcp_retries1is 3. -
For SYN segments,
net.ipv4.tcp_syn_retriesandnet.ipv4.tcp_synack_retriesbounds the number of retransmissions of SYN segments; their default value is 5 (roughly 180s).x@node-1:~$ sudo iptables -A INPUT -p tcp -s 192.168.91.128/32 --dport 6666 --syn -j DROPx@node-0:~$ sudo sysctl net.ipv4.tcp_syn_retries net.ipv4.tcp_syn_retries = 6 x@node-0:~$ time telnet 192.168.91.137 6666 Trying 192.168.91.137... telnet: Unable to connect to remote host: Connection timed out real 2m9.448s user 0m0.003s sys 0m0.001s00:00:00.000000 IP 192.168.91.128.42966 > 192.168.91.137.6666: Flags [S], seq 2460858944, win 1460, options [mss 1460,sackOK,TS val 991112255 ecr 0,nop,wscale 7], length 0 00:00:01.030071 IP 192.168.91.128.42966 > 192.168.91.137.6666: Flags [S], seq 2460858944, win 1460, options [mss 1460,sackOK,TS val 991113285 ecr 0,nop,wscale 7], length 0 00:00:03.045544 IP 192.168.91.128.42966 > 192.168.91.137.6666: Flags [S], seq 2460858944, win 1460, options [mss 1460,sackOK,TS val 991115301 ecr 0,nop,wscale 7], length 0 00:00:07.077396 IP 192.168.91.128.42966 > 192.168.91.137.6666: Flags [S], seq 2460858944, win 1460, options [mss 1460,sackOK,TS val 991119332 ecr 0,nop,wscale 7], length 0 00:00:15.269455 IP 192.168.91.128.42966 > 192.168.91.137.6666: Flags [S], seq 2460858944, win 1460, options [mss 1460,sackOK,TS val 991127524 ecr 0,nop,wscale 7], length 0 00:00:31.397938 IP 192.168.91.128.42966 > 192.168.91.137.6666: Flags [S], seq 2460858944, win 1460, options [mss 1460,sackOK,TS val 991143653 ecr 0,nop,wscale 7], length 0 00:01:03.909769 IP 192.168.91.128.42966 > 192.168.91.137.6666: Flags [S], seq 2460858944, win 1460, options [mss 1460,sackOK,TS val 991176165 ecr 0,nop,wscale 7], length 0
2. Setting the Retransmission Timeout (RTO)
Fundamental to TCP’s timeout and retransmission procedures is how to set the RTO based upon measurement of the RTT experienced on a given connection.
-
If TCP retransmits a segment earlier than the RTT, it may be injecting duplicate traffic into the network unnecessarily.
-
Conversely, if it delays sending until much longer than one RTT, the overall network utilization (and single-connection throughput) drops when traffic is lost.
Knowing the RTT is made more complicated because it can change over time, as routes and network usage vary.
Because TCP sends acknowledgments when it receives data, it is possible to send a byte with a particular sequence number and measure the time (called an RTT sample) required to receive an acknowledgment that covers that sequence number.
-
The challenge for TCP is to establish a good estimate for the range of RTT values given a set of samples that vary over time and set the RTO based on these values.
-
The RTT is estimated for each TCP connection separately, and one retransmission timer is pending whenever any data is in flight that consumes a sequence number (including SYN and FIN segments).
2.1. The Classic Method
The original TCP specification [RFC0793] had TCP update a smoothed RTT estimator (called SRTT) using the following formula:
SRTT ← α(SRTT) + (1 − α) RTTs
-
Here, SRTT is updated based on both its existing value and a new sample, RTTs.
-
The constant α is a smoothing or scale factor with a recommended value between 0.8 and 0.9.
-
SRTT is updated every time a new measurement is made.
-
With the original recommended value for α, it is clear that 80% to 90% of each new estimate is from the previous estimate and 10% to 20% is from the new measurement.
-
This type of average is also known as an exponentially weighted moving average (EWMA) or low-pass filter.
-
It is convenient for implementation reasons because it requires only one previous value of SRTT to be stored in order to keep the running estimate.
Given the estimator SRTT, which changes as the RTT changes, [RFC0793] recommended that the RTO be set to the following:
RTO = min(ubound, max(lbound,(SRTT)β))
-
where β is a delay variance factor with a recommended value of 1.3 to 2.0,
-
ubound is an upper bound (suggested to be, e.g., 1 minute),
-
and lbound is a lower bound (suggested to be, e.g., 1s) on the RTO.
We shall call this assignment procedure the classic method. It generally results in the RTO being set either to 1s, or to about twice SRTT.
For relatively stable distributions of the RTT, this was adequate. However, when TCP was run over networks with highly variable RTTs (e.g., early packet radio networks in this case), it did not perform so well.
2.2. The Standard Method
In [J88], Jacobson detailed problems with the classic method further—basically, that the timer specified by [RFC0793] cannot keep up with wide fluctuations in the RTT (and in particular, it causes unnecessary retransmissions when the real RTT is much larger than expected).
To address this problem, the method used to assign the RTO was enhanced to accommodate a larger variability in the RTT.
-
This is accomplished by keeping track of an estimate of the variability in the RTT measurements in addition to the estimate of its average.
-
Setting the RTO based on both a mean and a variability estimator provides a better timeout response to wide fluctuations in the roundtrip times than just calculating the RTO as a constant multiple of the mean.
-
If we think of the RTT measurements made by TCP as samples of a statistical process, estimating both the mean and variance (or standard deviation) helps to make better predictions about the possible future values the process may take on.
-
A good prediction for the range of possible values for the RTT helps TCP determine an RTO that is neither too large nor too small in most cases.
The following equations that are applied to each RTT measurement M (called RTTs earlier):
srtt ← (1 - g)(srtt) + (g)M
rttvar ← (1 - h)(rttvar) + (h)(|M - srtt|)
RTO = srtt + 4(rttvar)
Here, the value srtt effectively replaces the earlier value of SRTT, and the value rttvar, which becomes an EWMA of the mean deviation, is used instead of β to help determine the RTO.
3. Timer-Based Retransmission
Once a sending TCP has established its RTO based upon measurements of the time-varying values of effective RTT, whenever it sends a segment it ensures that a retransmission timer is set appropriately.
-
When setting a retransmission timer, the sequence number of the so-called timed segment is recorded, and if an ACK is received in time, the retransmission timer is canceled.
-
The next time the sender emits a packet with data in it, a new retransmission timer is set, the old one is canceled, and the new sequence number is recorded.
-
The sending TCP therefore continuously sets and cancels one retransmission timer per connection; if no data is ever lost, no retransmission timer ever expires.
When TCP fails to receive an ACK for a segment it has timed on a connection within the RTO, it performs a timer-based retransmission.
TCP considers a timer-based retransmission as a fairly major event; it reacts very cautiously when it happens by quickly reducing the rate at which it sends data into the network. It does this in two ways.
-
The first way is to reduce its sending window size based on congestion control procedures.
-
The other way is to keep increasing a multiplicative backoff factor applied to the RTO each time a retransmitted segment is again retransmitted.
In particular, the RTO value is (temporarily) multiplied by the value
γto form the backed-off timeout when multiple retransmissions of the same segment occur:RTO = γRTO-
In ordinary circumstances,
γhas the value 1. -
On subsequent retransmissions,
γis doubled: 2, 4, 8, and so forth.There is typically a maximum backoff factor that
γis not allowed to exceed (Linux ensures that the used RTO never exceeds the valueTCP_RTO_MAX, which defaults to 120s).x@node-0:~$ uname -a; uname -r Linux node-0 5.10.0-19-amd64 #1 SMP Debian 5.10.149-2 (2022-10-21) x86_64 GNU/Linux 5.10.0-19-amd64 x@node-0:~$ grep "#define HZ" /usr/include/asm-generic/param.h #define HZ 100 x@node-0:~$ grep "#define TCP_RTO_" /usr/src/linux-headers-5.10.0-19-common/include/net/tcp.h #define TCP_RTO_MAX ((unsigned)(120*HZ)) #define TCP_RTO_MIN ((unsigned)(HZ/5)) -
Once an acceptable ACK is received,
γis reset to 1.
x@node-0:~$ while ss -itn dst *:6666; do sleep 1; done State Recv-Q Send-Q Local Address:Port Peer Address:Port ESTAB 0 0 192.168.91.128:33176 192.168.91.135:6666 cubic wscale:7,7 rto:204 rtt:1.86/0.93 cwnd:10 State Recv-Q Send-Q Local Address:Port Peer Address:Port ESTAB 0 7 192.168.91.128:33176 192.168.91.135:6666 cubic wscale:7,7 rto:204 rtt:1.86/0.93 cwnd:10 State Recv-Q Send-Q Local Address:Port Peer Address:Port ESTAB 0 7 192.168.91.128:33176 192.168.91.135:6666 cubic wscale:7,7 rto:816 backoff:2 rtt:1.86/0.93 cwnd:1 State Recv-Q Send-Q Local Address:Port Peer Address:Port ESTAB 0 7 192.168.91.128:33176 192.168.91.135:6666 cubic wscale:7,7 rto:1632 backoff:3 rtt:1.86/0.93 cwnd:1 ... State Recv-Q Send-Q Local Address:Port Peer Address:Port ESTAB 0 7 192.168.91.128:33176 192.168.91.135:6666 cubic wscale:7,7 rto:6528 backoff:5 rtt:1.86/0.93 cwnd:1 State Recv-Q Send-Q Local Address:Port Peer Address:Port ESTAB 0 0 192.168.91.128:33176 192.168.91.135:6666 cubic wscale:7,7 rto:204 rtt:1.752/0.912 cwnd:2 -
4. Fast Retransmit
Fast retransmit [RFC5681] is a TCP procedure that can induce a packet retransmission based on feedback from the receiver instead of requiring a retransmission timer to expire.
TCP generates an immediate acknowledgment (a duplicate ACK) when an out-of-order segment is received, and that the loss of a segment implies out-of-order arrivals at the receiver when subsequent data arrives.
-
When this happens, a hole is created at the receiver.
-
The sender’s job then becomes filling the receiver’s holes as quickly and efficiently as possible.
-
The duplicate ACKs sent immediately when out-of-order data arrives are not delayed.
The reason is to let the sender know that a segment was received out of order, and to indicate what sequence number is expected (i.e., where the hole is).
-
When SACK is used, these duplicate ACKs typically contain SACK blocks as well, which can provide information about more than one hole.
A duplicate ACK (with or without SACK blocks) arriving at a sender is a potential indicator that a packet sent earlier has been lost.
-
It can also appear when there is packet reordering in the network—if a receiver receives a packet for a sequence number beyond the one it is expecting next, the expected packet could be either missing or merely delayed.
-
TCP waits for a small number of duplicate ACKs (called the duplicate ACK threshold or dupthresh) to be received before concluding that a packet has been lost and initiating a fast retransmit.
-
Traditionally, dupthresh has been a constant (with value 3 [RFC5681]), but some nonstandard implementations (including Linux) alter this value based on the current measured level of reordering.
-
A TCP sender observing at least dupthresh duplicate ACKs retransmits one or more packets that appear to be missing without waiting for a retransmission timer to expire. It may also send additional data that has not yet been sent.
-
Packet loss inferred by the presence of duplicate ACKs is assumed to be related to network congestion, and congestion control procedures are invoked along with fast retransmit.
-
Without SACK, no more than one segment is typically retransmitted until an acceptable ACK is received.
-
With SACK, ACKs contain additional information allowing the sender to fill more than one hole in the receiver per RTT.
x@node-1:~$ sudo sysctl net.ipv4.tcp_sack=0 # Disable select acknowledgments (SACKS).
net.ipv4.tcp_sack = 0
x@node-1:~$ sudo iptables -A INPUT -p tcp --dport 6666 -m statistic --mode nth --every 2 --packet 0 -j DROP
x@node-1:~$ sudo iptables -L INPUT
Chain INPUT (policy ACCEPT)
target prot opt source destination
DROP tcp -- anywhere anywhere tcp dpt:6666 statistic mode nth every 2x@node-0:~$ sudo ethtool -K ens32 tso off
x@node-0:~$ sudo sysctl net.ipv4.tcp_sack=0
net.ipv4.tcp_sack = 0
x@node-0:~$ head -c 10000 /dev/random | nc -v node-1 6666
Ncat: Version 7.80 ( https://nmap.org/ncat )
Ncat: Connected to 192.168.91.137:6666.
Ncat: 10000 bytes sent, 0 bytes received in 2.50 seconds.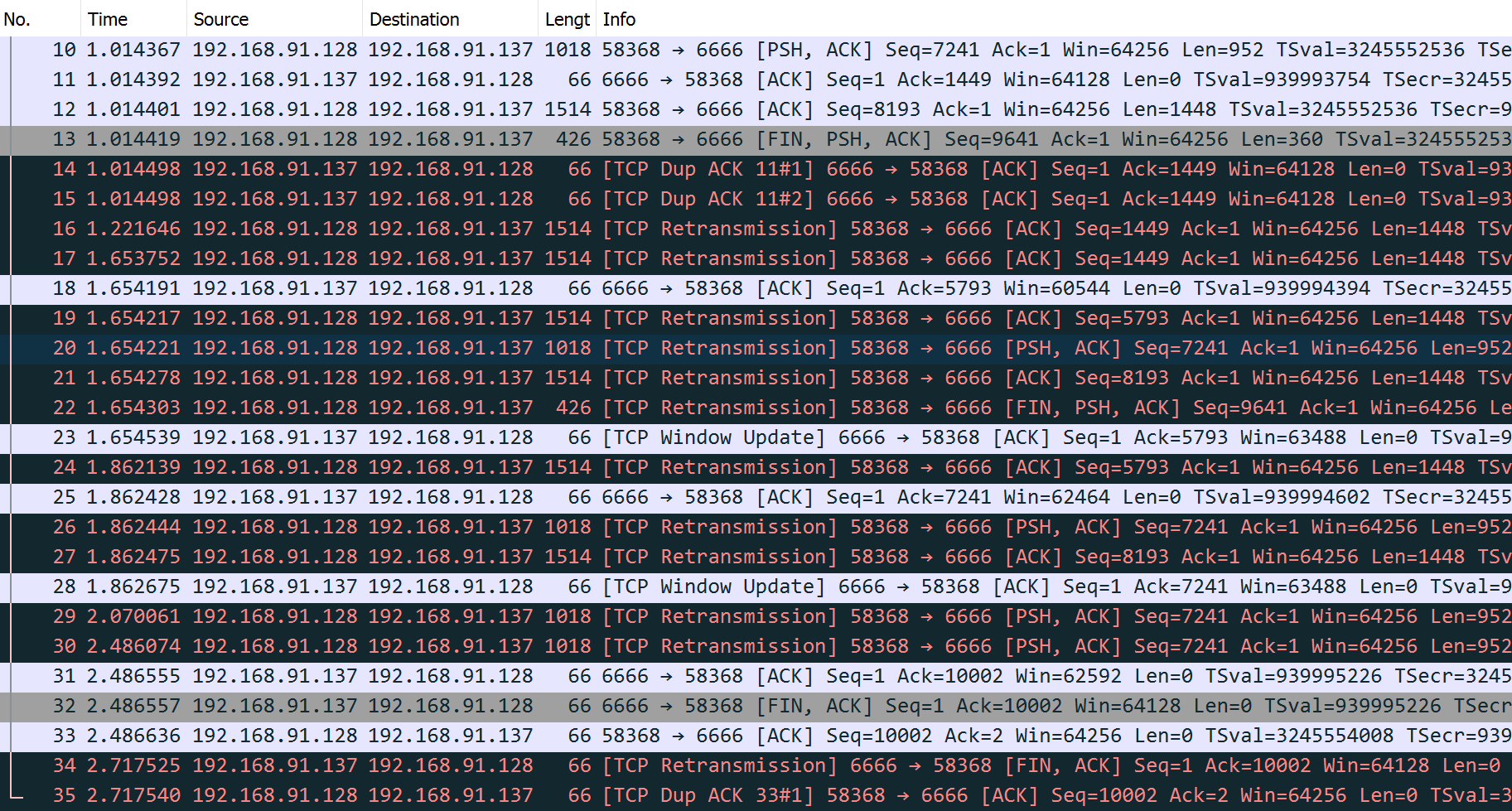
-
The packets 23 and 28 are window update ACKs with a duplicate sequence number (because no data is being carried) but contains a change to the TCP flow control window. The window changes from 65,160 bytes to 63,488 bytes.
Thus, it is not counted toward the three-duplicate-ACK threshold required to initiate a fast retransmit.
Window updates merely provide a copy of the window advertisement.
-
The packets 14 and 15 are all duplicate ACKs for sequence number 1449.
The arrival of the second of these duplicate ACKs triggers the fast retransmit of segment 1449 by packets 16 and 17.
-
The retransmissions from packet 19 to 22 are somewhat different from the first two.
When the first two retransmissions takes place, the sending TCP notes the highest sequence number (called the recovery point) it had sent just before it performed the retransmission (9641 + 360 = 10001).
TCP is considered to be recovering from loss after a retransmission until it receives an ACK that matches or exceeds the sequence number of the recovery point.
In this example, the ACKs at packet 18 are not for 10001, but instead for 5793.
-
This number is larger than the previous highest ACK value seen (1449), but not enough to meet or exceed the recovery point (10001).
-
This type of ACK is called a partial ACK for this reason.
When partial ACKs arrive, the sending TCP immediately sends the segments that appears to be missing (5793 to 9641 in this case) and continues this way until the recovery point is matched or exceeded by an arriving ACK.
If permitted by congestion control procedures, it may also send new data it has not yet sent.
-
-
Because no SACKs are being used, the sender can learn of at most one receiver hole per round-trip time, indicated by the increase in the ACK number of returning packets, which can only occur once a retransmission filling the receiver’s lowest-numbered hole has been received and ACKed.
Show tcpdump trace
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
00:00:00.000000 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [S], seq 2395807434, win 64240, options [mss 1460,nop,nop,TS val 3245551521 ecr 0,nop,wscale 7], length 0
00:00:01.013807 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [S], seq 2395807434, win 64240, options [mss 1460,nop,nop,TS val 3245552536 ecr 0,nop,wscale 7], length 0
00:00:01.014094 IP 192.168.91.137.6666 > 192.168.91.128.58368: Flags [S.], seq 3105090969, ack 2395807435, win 65160, options [mss 1460,nop,nop,TS val 939993754 ecr 3245552536,nop,wscale 7], length 0
00:00:01.014138 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [.], ack 1, win 502, options [nop,nop,TS val 3245552536 ecr 939993754], length 0
00:00:01.014253 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [.], seq 1:1449, ack 1, win 502, options [nop,nop,TS val 3245552536 ecr 939993754], length 1448
00:00:01.014303 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [P.], seq 1449:2897, ack 1, win 502, options [nop,nop,TS val 3245552536 ecr 939993754], length 1448
00:00:01.014329 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [.], seq 2897:4345, ack 1, win 502, options [nop,nop,TS val 3245552536 ecr 939993754], length 1448
00:00:01.014330 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [P.], seq 4345:5793, ack 1, win 502, options [nop,nop,TS val 3245552536 ecr 939993754], length 1448
00:00:01.014331 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [.], seq 5793:7241, ack 1, win 502, options [nop,nop,TS val 3245552536 ecr 939993754], length 1448
00:00:01.014367 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [P.], seq 7241:8193, ack 1, win 502, options [nop,nop,TS val 3245552536 ecr 939993754], length 952
00:00:01.014392 IP 192.168.91.137.6666 > 192.168.91.128.58368: Flags [.], ack 1449, win 501, options [nop,nop,TS val 939993754 ecr 3245552536], length 0
00:00:01.014401 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [.], seq 8193:9641, ack 1, win 502, options [nop,nop,TS val 3245552536 ecr 939993754], length 1448
00:00:01.014419 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [FP.], seq 9641:10001, ack 1, win 502, options [nop,nop,TS val 3245552536 ecr 939993754], length 360
00:00:01.014498 IP 192.168.91.137.6666 > 192.168.91.128.58368: Flags [.], ack 1449, win 501, options [nop,nop,TS val 939993754 ecr 3245552536], length 0
00:00:01.014498 IP 192.168.91.137.6666 > 192.168.91.128.58368: Flags [.], ack 1449, win 501, options [nop,nop,TS val 939993754 ecr 3245552536], length 0
00:00:01.221646 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [.], seq 1449:2897, ack 1, win 502, options [nop,nop,TS val 3245552743 ecr 939993754], length 1448
00:00:01.653752 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [.], seq 1449:2897, ack 1, win 502, options [nop,nop,TS val 3245553175 ecr 939993754], length 1448
00:00:01.654191 IP 192.168.91.137.6666 > 192.168.91.128.58368: Flags [.], ack 5793, win 473, options [nop,nop,TS val 939994394 ecr 3245553175], length 0
00:00:01.654217 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [.], seq 5793:7241, ack 1, win 502, options [nop,nop,TS val 3245553176 ecr 939994394], length 1448
00:00:01.654221 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [P.], seq 7241:8193, ack 1, win 502, options [nop,nop,TS val 3245553176 ecr 939994394], length 952
00:00:01.654278 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [.], seq 8193:9641, ack 1, win 502, options [nop,nop,TS val 3245553176 ecr 939994394], length 1448
00:00:01.654303 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [FP.], seq 9641:10001, ack 1, win 502, options [nop,nop,TS val 3245553176 ecr 939994394], length 360
00:00:01.654539 IP 192.168.91.137.6666 > 192.168.91.128.58368: Flags [.], ack 5793, win 496, options [nop,nop,TS val 939994394 ecr 3245553175], length 0
00:00:01.862139 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [.], seq 5793:7241, ack 1, win 502, options [nop,nop,TS val 3245553384 ecr 939994394], length 1448
00:00:01.862428 IP 192.168.91.137.6666 > 192.168.91.128.58368: Flags [.], ack 7241, win 488, options [nop,nop,TS val 939994602 ecr 3245553384], length 0
00:00:01.862444 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [P.], seq 7241:8193, ack 1, win 502, options [nop,nop,TS val 3245553384 ecr 939994602], length 952
00:00:01.862475 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [.], seq 8193:9641, ack 1, win 502, options [nop,nop,TS val 3245553384 ecr 939994602], length 1448
00:00:01.862675 IP 192.168.91.137.6666 > 192.168.91.128.58368: Flags [.], ack 7241, win 496, options [nop,nop,TS val 939994602 ecr 3245553384], length 0
00:00:02.070061 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [P.], seq 7241:8193, ack 1, win 502, options [nop,nop,TS val 3245553592 ecr 939994602], length 952
00:00:02.486074 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [P.], seq 7241:8193, ack 1, win 502, options [nop,nop,TS val 3245554008 ecr 939994602], length 952
00:00:02.486555 IP 192.168.91.137.6666 > 192.168.91.128.58368: Flags [.], ack 10002, win 489, options [nop,nop,TS val 939995226 ecr 3245554008], length 0
00:00:02.486557 IP 192.168.91.137.6666 > 192.168.91.128.58368: Flags [F.], seq 1, ack 10002, win 501, options [nop,nop,TS val 939995226 ecr 3245554008], length 0
00:00:02.486636 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [.], ack 2, win 502, options [nop,nop,TS val 3245554008 ecr 939995226], length 0
00:00:02.717525 IP 192.168.91.137.6666 > 192.168.91.128.58368: Flags [F.], seq 1, ack 10002, win 501, options [nop,nop,TS val 939995457 ecr 3245554008], length 0
00:00:02.717540 IP 192.168.91.128.58368 > 192.168.91.137.6666: Flags [.], ack 2, win 502, options [nop,nop,TS val 3245554239 ecr 939995226], length 0
5. Retransmission with Selective Acknowledgments
With the standardization of the Selective Acknowledgment options in [RFC2018], a SACK-capable TCP receiver is able to describe data it has received with sequence numbers beyond the cumulative ACK Number field it sends in the primary portion of the TCP header.
-
The gaps between the ACK number and other in-window data cached at the receiver are called holes.
-
Data with sequence numbers beyond the holes are called out-of-sequence data because that data is not contiguous, in terms of its sequence numbers, with the other data the receiver has already received.
The job of a sending TCP is to fill the holes in the receiver by retransmitting any data the receiver is missing, yet to be as efficient as possible by not resending data the receiver already has.
In many circumstances, the properly operating SACK sender is able to fill these holes more quickly and with fewer unnecessary retransmissions than a comparable non-SACK sender because it does not have to wait an entire RTT to learn about additional holes.
When the SACK option is being used, an ACK can be augmented with up to three or four SACK blocks that contain information about out-of-sequence data at the receiver.
-
Each SACK block contains two 32-bit sequence numbers representing the first and last sequence numbers (plus 1) of a continuous block of out-of-sequence data being held at the receiver.
-
A SACK option that specifies n blocks has a length of 8n + 2 bytes (8n bytes for the sequence numbers and 2 to indicate the option kind and length), so the 40 bytes available to hold TCP options can specify a maximum of four blocks.
-
It is expected that SACK will often be used in conjunction with the TSOPT, which takes an additional 10 bytes (plus 2 bytes of padding), meaning that SACK is typically able to include only three blocks per ACK.
-
With three distinct blocks, up to three holes can be reported to the sender.
-
If not limited by congestion control, all three could be filled within one round-trip time using a SACK-capable sender.
-
An ACK packet containing one or more SACK blocks is sometimes called simply a SACK.
=> [.], seq 1:1449, ack 1, [TS val 3251433112 ecr 945874299], length 1448
=> [P.], seq 1449:2897, ack 1, [TS val 3251433112 ecr 945874299], length 1448
=> [.], seq 2897:4345, ack 1, [TS val 3251433112 ecr 945874299], length 1448
=> [P.], seq 4345:5793, ack 1, [TS val 3251433112 ecr 945874299], length 1448
=> [.], seq 5793:7241, ack 1, [TS val 3251433112 ecr 945874299], length 1448
=> [P.], seq 7241:8193, ack 1, [TS val 3251433112 ecr 945874299], length 952
<= [.], ack 1449, [TS val 945874300 ecr 3251433112], length 0
=> [.], seq 8193:9641, ack 1, [TS val 3251433113 ecr 945874300], length 1448
=> [FP.], seq 9641:10001, ack 1, [TS val 3251433113 ecr 945874300], length 360
<= [.], ack 1449, [TS val 945874300 ecr 3251433112,sack 1 {2897:5793}], length 0
<= [.], ack 1449, [TS val 945874300 ecr 3251433112,sack 2 {8193:10002}{2897:5793}], length 0
=> [.], seq 1449:2897, ack 1, [TS val 3251433113 ecr 945874300], length 1448
=> [.], seq 5793:7241, ack 1, [TS val 3251433113 ecr 945874300], length 14485.1. SACK Receiver Behavior
A SACK-capable receiver is allowed to generate SACKs if it has received the SACK-Permitted option during the TCP connection establishment.
// The SACK-Permitted option is exchanged in SYN segments to indicate the capability to generate and process SACK information.
// Most modern TCPs support the MSS, Timestamps, Window Scale, and SACK-Permitted options during connection establishment.
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [S], seq 3680115076, win 64240, options [mss 1460,sackOK,TS val 3251433112 ecr 0,nop,wscale 7], length 0
IP 192.168.91.137.6666 > 192.168.91.128.56276: Flags [S.], seq 2651302134, ack 3680115077, win 65160, options [mss 1460,sackOK,TS val 945874299 ecr 3251433112,nop,wscale 7], length 0Generally speaking, a receiver generates SACKs whenever there is any out-of-order data in its buffer. This can happen either:
-
because data was lost in transit, or
-
because it has been reordered and newer data has arrived at the receiver before older data.
The receiver places in the first SACK block the sequence number range contained in the segment it has most recently received.
-
Because the space in a SACK option is limited, it is best to ensure that the most recent information is always provided to the sending TCP, if possible.
-
Other SACK blocks are listed in the order in which they appeared as first blocks in previous SACK options.
That is, they are filled in by repeating the most recently sent SACK blocks (in other segments) that are not subsets of another block about to be placed in the option being constructed.
<= [.], ack 1449, [TS val 945874300 ecr 3251433112], length 0 <= [.], ack 1449, [TS val 945874300 ecr 3251433112,sack 1 {2897:5793}], length 0 <= [.], ack 1449, [TS val 945874300 ecr 3251433112,sack 2 {8193:10002}{2897:5793}], length 0The purpose of including more than one SACK block in a SACK option and repeating these blocks across multiple SACKs is to provide some redundancy in the case where SACKs are lost.
-
If SACKs were never lost, [RFC2018] points out that only one SACK block would be required per SACK for full SACK functionality.
-
Unfortunately, SACKs and regular ACKs are sometimes lost and are not retransmitted by TCP unless they contain data (or the SYN or FIN control bit fields are turned on).
-
5.2. SACK Sender Behavior
A SACK-capable sender must be used that treats the SACK blocks appropriately and performs selective retransmission by sending only those segments missing at the receiver, a process also called selective repeat.
The SACK sender keeps track of any cumulative ACK information it receives (like any TCP sender), plus any SACK information it receives.
When a SACK-capable sender has the opportunity to perform a retransmission, usually because it has received a SACK or seen multiple duplicate ACKs, it has the choice of whether it sends new data or retransmits old data.
-
The SACK information provides the sequence number ranges present at the receiver, so the sender can infer what segments likely need to be retransmitted to fill the receiver’s holes.
-
The simplest approach is to have the sender first fill the holes at the receiver and then move on to send more new data [RFC3517] if the congestion control procedures allow. This is the most common approach.
5.3. Example
To understand how the use of SACK alters the sender and receiver behaviors, we repeat the preceding fast retransmit experiment, but this time the sender and receiver are using SACK.
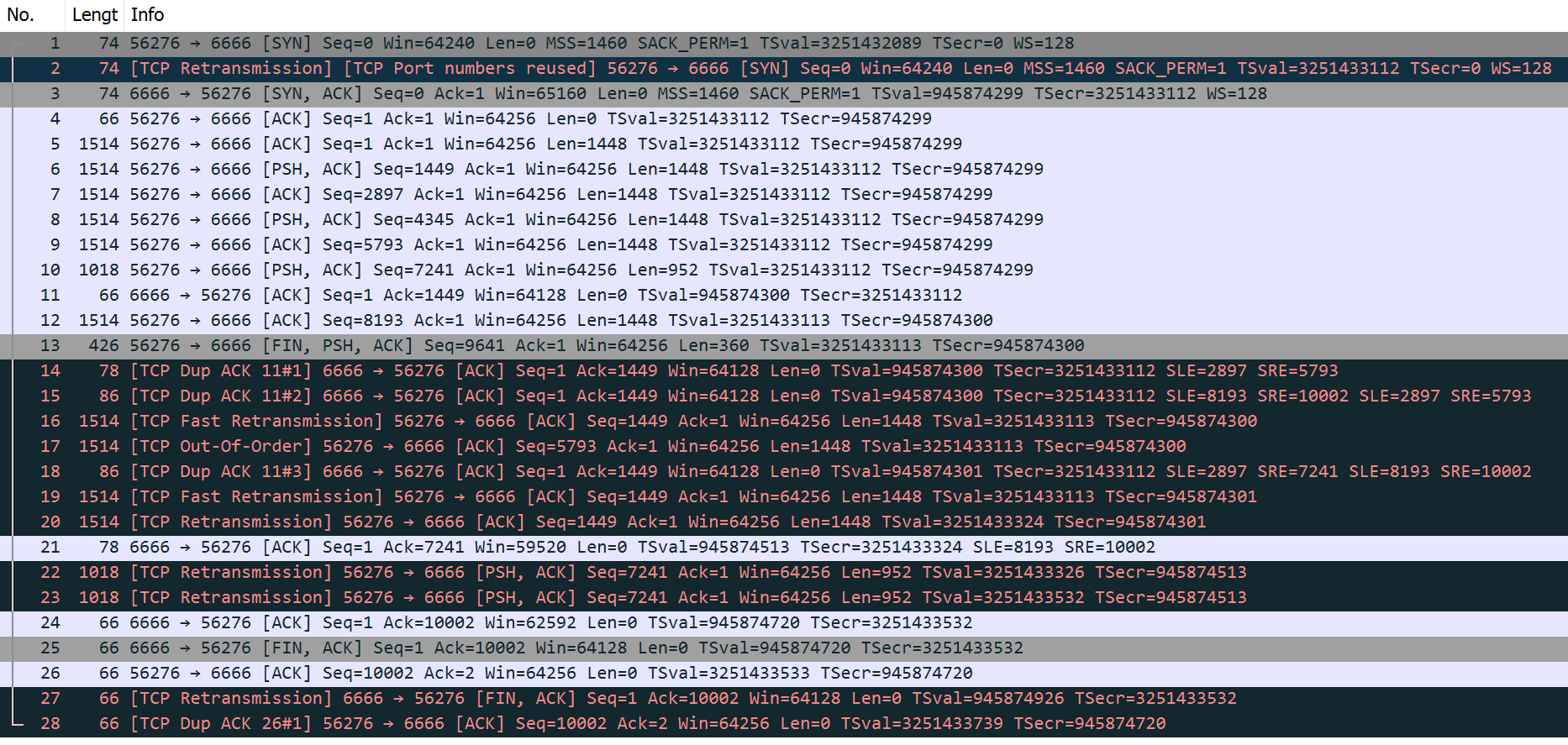
-
The SYN packet from the sender, the first packet of the trace, also contains an identical option.
These options are present only at connection setup, and thus they only ever appear in segments with the SYN bit field set.
Once the connection is permitted to use SACKs, packet loss generally causes the receiver to start producing SACKs.
-
The ACK at packet 14 for 1449 contains a SACK block of [2897:5793], indicating a hole at the receiver.
The receiver is missing the sequence number range [1449,2896], which corresponds to the single 1448-byte packet starting with sequence number 1449.
-
The SACK arriving at packet 15 contains two SACK blocks: [8193:10002] and [2897:5793].
Recall that the first SACK blocks from previous SACKs are repeated in later positions in subsequent SACKs for robustness against ACK loss.
This SACK is a duplicate ACK for sequence number 1449 and suggests that the receiver now requires the missing segments starting with sequence numbers 1449 and 5793.
-
The SACK sender has not had to wait an RTT to retransmit lost segment 5793 after retransmitting segment 1449.
Show tcpdump trace
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [S], seq 3680115076, win 64240, options [mss 1460,sackOK,TS val 3251432089 ecr 0,nop,wscale 7], length 0
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [S], seq 3680115076, win 64240, options [mss 1460,sackOK,TS val 3251433112 ecr 0,nop,wscale 7], length 0
IP 192.168.91.137.6666 > 192.168.91.128.56276: Flags [S.], seq 2651302134, ack 3680115077, win 65160, options [mss 1460,sackOK,TS val 945874299 ecr 3251433112,nop,wscale 7], length 0
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [.], ack 1, win 502, options [nop,nop,TS val 3251433112 ecr 945874299], length 0
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [.], seq 1:1449, ack 1, win 502, options [nop,nop,TS val 3251433112 ecr 945874299], length 1448
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [P.], seq 1449:2897, ack 1, win 502, options [nop,nop,TS val 3251433112 ecr 945874299], length 1448
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [.], seq 2897:4345, ack 1, win 502, options [nop,nop,TS val 3251433112 ecr 945874299], length 1448
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [P.], seq 4345:5793, ack 1, win 502, options [nop,nop,TS val 3251433112 ecr 945874299], length 1448
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [.], seq 5793:7241, ack 1, win 502, options [nop,nop,TS val 3251433112 ecr 945874299], length 1448
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [P.], seq 7241:8193, ack 1, win 502, options [nop,nop,TS val 3251433112 ecr 945874299], length 952
IP 192.168.91.137.6666 > 192.168.91.128.56276: Flags [.], ack 1449, win 501, options [nop,nop,TS val 945874300 ecr 3251433112], length 0
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [.], seq 8193:9641, ack 1, win 502, options [nop,nop,TS val 3251433113 ecr 945874300], length 1448
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [FP.], seq 9641:10001, ack 1, win 502, options [nop,nop,TS val 3251433113 ecr 945874300], length 360
IP 192.168.91.137.6666 > 192.168.91.128.56276: Flags [.], ack 1449, win 501, options [nop,nop,TS val 945874300 ecr 3251433112,nop,nop,sack 1 {2897:5793}], length 0
IP 192.168.91.137.6666 > 192.168.91.128.56276: Flags [.], ack 1449, win 501, options [nop,nop,TS val 945874300 ecr 3251433112,nop,nop,sack 2 {8193:10002}{2897:5793}], length 0
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [.], seq 1449:2897, ack 1, win 502, options [nop,nop,TS val 3251433113 ecr 945874300], length 1448
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [.], seq 5793:7241, ack 1, win 502, options [nop,nop,TS val 3251433113 ecr 945874300], length 1448
IP 192.168.91.137.6666 > 192.168.91.128.56276: Flags [.], ack 1449, win 501, options [nop,nop,TS val 945874301 ecr 3251433112,nop,nop,sack 2 {2897:7241}{8193:10002}], length 0
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [.], seq 1449:2897, ack 1, win 502, options [nop,nop,TS val 3251433113 ecr 945874301], length 1448
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [.], seq 1449:2897, ack 1, win 502, options [nop,nop,TS val 3251433324 ecr 945874301], length 1448
IP 192.168.91.137.6666 > 192.168.91.128.56276: Flags [.], ack 7241, win 465, options [nop,nop,TS val 945874513 ecr 3251433324,nop,nop,sack 1 {8193:10002}], length 0
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [P.], seq 7241:8193, ack 1, win 502, options [nop,nop,TS val 3251433326 ecr 945874513], length 952
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [P.], seq 7241:8193, ack 1, win 502, options [nop,nop,TS val 3251433532 ecr 945874513], length 952
IP 192.168.91.137.6666 > 192.168.91.128.56276: Flags [.], ack 10002, win 489, options [nop,nop,TS val 945874720 ecr 3251433532], length 0
IP 192.168.91.137.6666 > 192.168.91.128.56276: Flags [F.], seq 1, ack 10002, win 501, options [nop,nop,TS val 945874720 ecr 3251433532], length 0
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [.], ack 2, win 502, options [nop,nop,TS val 3251433533 ecr 945874720], length 0
IP 192.168.91.137.6666 > 192.168.91.128.56276: Flags [F.], seq 1, ack 10002, win 501, options [nop,nop,TS val 945874926 ecr 3251433532], length 0
IP 192.168.91.128.56276 > 192.168.91.137.6666: Flags [.], ack 2, win 502, options [nop,nop,TS val 3251433739 ecr 945874720], length 0
6. Spurious Timeouts and Retransmissions
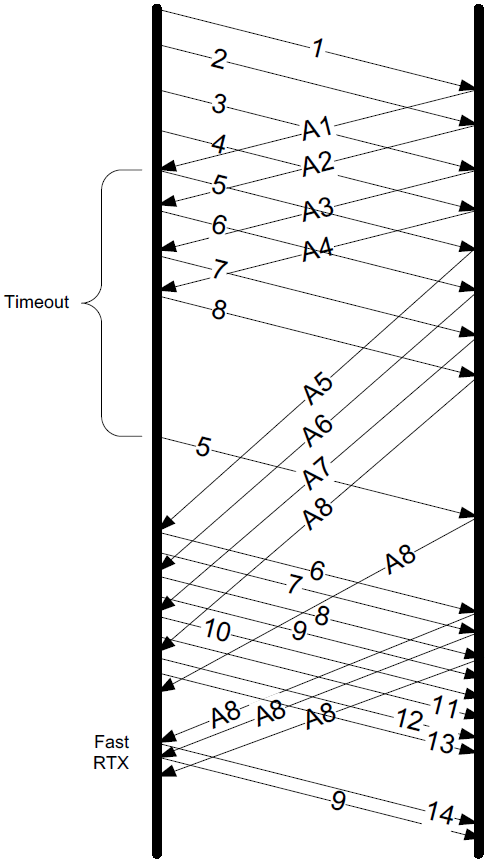
Under a number of circumstances, TCP may initiate a retransmission even when no data has been lost.
Such undesirable retransmissions are called spurious retransmissions and are caused by spurious timeouts (timeouts firing too early) and other reasons such as packet reordering, packet duplication, or lost ACKs.
Spurious timeouts can occur when the real RTT has recently increased significantly, beyond the RTO. This happens more frequently in environments where lower-layer protocols have widely varying performance (e.g., wireless).
A number of approaches have been suggested to deal with spurious timeouts. They generally involve a detection algorithm and a response algorithm.
-
The detection algorithm attempts to determine whether a timeout or timer-based retransmission was spurious.
-
The response algorithm is invoked once a timeout or retransmission is deemed spurious.
Its purpose is to undo or mitigate some action that is otherwise normally performed by TCP when a retransmission timer expires.
6.1. Duplicate SACK (DSACK) Extension
With a non-SACK TCP, an ACK can indicate only the highest in-sequence segment back to the sender. With SACK, it can signal other (out-of-order) segments as well.
DSACK or D-SACK (stands for duplicate SACK [RFC2883]) is a rule, applied at the SACK receiver and interoperable with conventional SACK senders, that causes the first SACK block to indicate the sequence numbers of a duplicate segment that has arrived at the receiver, which is usually to determine when a retransmission was not necessary and to learn additional facts about the network.
The change to the SACK receiver is to allow a SACK block to be included even if it covers sequence numbers below (or equal to) the cumulative ACK Number field.
-
It applies equally well in cases where the DSACK information is above the cumulative ACK Number field; this happens for duplicated out-of-order segments.
-
DSACK information is included in only a single ACK, and such an ACK is called a DSACK.
-
DSACK information is not repeated across multiple SACKs as conventional SACK information is.
Exactly what a sender given DSACK information is supposed to do with it is not specified by [RFC2883].
6.2. The Eifel Detection Algorithm
The experimental Eifel Detection Algorithm [RFC3522] deals with the retransmission ambiguity problem using the TCP TSOPT to detect spurious retransmissions.
-
After a retransmission timeout occurs, Eifel awaits the next acceptable ACK.
-
If the next acceptable ACK indicates that the first copy of a retransmitted packet (called the original transmit) was the cause for the ACK, the retransmission is considered to be spurious.
The Eifel Detection Algorithm is able to detect spurious behavior earlier than the approach using only DSACK because it relies on ACKs generated as a result of packets arriving before loss recovery is initiated.
DSACKs, conversely, are able to be sent only after a duplicate segment has arrived at the receiver and able to be acted upon only after the DSACK is returned to the sender.
Detecting spurious retransmissions early can offer advantages, because it allows the sender to avoid most of the go-back-N behavior.
The mechanics of the Eifel Detection Algorithm are simple. It requires the use of the TCP TSOPT.
-
When a retransmission is sent (either a timer-based retransmission or a fast retransmit), the TSV value is stored.
-
When the first acceptable ACK covering its sequence number is received, the incoming ACK’s TSER is examined.
-
If it is smaller than the stored value, the ACK corresponds to the original transmission of the packet and not the retransmission, implying that the retransmission must have been spurious.
-
This approach is fairly robust to ACK loss as well.
-
If an ACK is lost, any subsequent ACKs still have TSER values less than the stored TSV of the retransmitted segment.
-
Thus, a retransmission can be deemed spurious as a result of any of the window’s worth of ACKs arriving, so a loss of any single ACK is not likely to cause a problem.
-
The Eifel Detection Algorithm can be combined with DSACKs which can be beneficial when an entire window’s worth of ACKs are lost but both the original transmit and retransmission have arrived at the receiver.
-
In this particular case, the arriving retransmit causes a DSACK to be generated.
-
The Eifel Detection Algorithm would by default conclude that the retransmission is spurious.
-
It is thought, however, that if so many ACKs are being lost, allowing TCP to believe the retransmission was not spurious is useful (e.g., to induce it to start sending more slowly—a consequence of the congestion control procedures).
-
Thus, arriving DSACKs cause the Eifel Detection Algorithm to conclude that the corresponding retransmission is not spurious.
6.3. Forward-RTO Recovery (F-RTO)
Forward-RTO Recovery (F-RTO) [RFC5682] is a standard algorithm for detecting spurious retransmissions.
-
It does not require any TCP options, so when it is implemented in a sender, it can be used effectively even with an older receiver that does not support the TCP TSOPT.
-
It attempts to detect only spurious retransmissions caused by expiration of the retransmission timer; it does not deal with the other causes for spurious retransmissions or duplications mentioned before.
F-RTO makes a modification to the action TCP ordinarily takes after a timer-based retransmission.
-
These retransmissions are for the smallest sequence number for which no ACK has yet been received.
-
Ordinarily, TCP continues sending additional adjacent packets in order as additional ACKs arrive. This is the go-back-N behavior.
F-RTO modifies the ordinary behavior of TCP by having TCP send new (so far unsent) data after the timeout-based retransmission when the first ACK arrives. It then inspects the second arriving ACK.
-
If either of the first two ACKs arriving after the retransmission was sent are duplicate ACKs, the retransmission is deemed OK.
-
If they are both acceptable ACKs that advance the sender’s window, the retransmission is deemed to have been spurious.
-
If the transmission of new data results in the arrival of acceptable ACKs, the arrival of the new data is moving the receiver’s window forward.
-
If such data is only causing duplicate ACKs, there must be one or more holes at the receiver.
-
In either case, the reception of new data at the receiver does not harm the overall data transfer performance (provided there are sufficient buffers at the receiver).
-
6.4. The Eifel Response Algorithm
The Eifel Response Algorithm [RFC4015] is a standard set of operations to be executed by a TCP once a retransmission has been deemed spurious.
Because the response algorithm is logically decoupled from the Eifel Detection Algorithm, it can be used with any of the detection algorithms we just discussed.
The Eifel Response Algorithm was originally intended to operate for both timer-based and fast retransmit spurious retransmissions but is currently specified only for timer-based retransmissions.
7. Packet Reordering and Duplication
In addition to packet loss, other packet delivery anomalies such as duplication and reordering can also affect TCP’s operation. In both of these cases, we wish TCP to be able to distinguish between packets that are reordered or duplicated and those that are lost.
7.1. Reordering
Packet reordering can occur in an IP network because IP provides no guarantee that relative ordering between packets is maintained during delivery.
This can be beneficial (to IP at least), because IP can choose another path for traffic (e.g., that is faster) without having to worry about the consequences that doing so may cause traffic freshly injected into the network to pass ahead of older traffic, resulting in the order of packet arrivals at the receiver not matching the order of transmission at the sender.
There are other reasons packet reordering may occur. For example, some high-performance routers employ multiple parallel data paths within the hardware [BPS99], and different processing delays among packets can lead to a departure order that does not match the arrival order.
Reordering may take place in the forward path or the reverse path of a TCP connection (or in some cases both). The reordering of data segments has a somewhat different effect on TCP as does reordering of ACK packets.
Recall that because of asymmetric routing, it is frequently the case that ACKs travel along different network links (and through different routers) from data packets on the forward path.
When traffic is reordered, TCP can be affected in several ways.
-
If reordering takes place in the reverse (ACK) direction, it causes the sending TCP to receive some ACKs that move the window significantly forward followed by some evidently old redundant ACKs that are discarded.
This can lead to an unwanted burstiness (instantaneous high-speed sending) behavior in the sending pattern of TCP and also trouble in taking advantage of available network bandwidth, because of the behavior of TCP’s congestion control.
-
If reordering occurs in the forward direction, TCP may have trouble distinguishing this condition from loss.
Both loss and reordering result in the receiver receiving out-of-order packets that create holes between the next expected packet and the other packets received so far.
-
When reordering is moderate (e.g., two adjacent packets switch order), the situation can be handled fairly quickly.
-
When reorderings are more severe, TCP can be tricked into believing that data has been lost even though it has not.
This can result in spurious retransmissions, primarily from the fast retransmit algorithm.
-
Because a TCP receiver is supposed to immediately ACK any out-of-sequence data it receives in order to help induce fast retransmit to be triggered on packet loss, any packet that is reordered within the network causes a receiver to produce a duplicate ACK.
If fast retransmit were to be invoked whenever any duplicate ACK is received at the sender, a large number of unnecessary retransmissions would occur on network paths where a small amount of reordering is common.
To handle this situation, fast retransmit is triggered only after the duplicate threshold (dupthresh) has been reached.
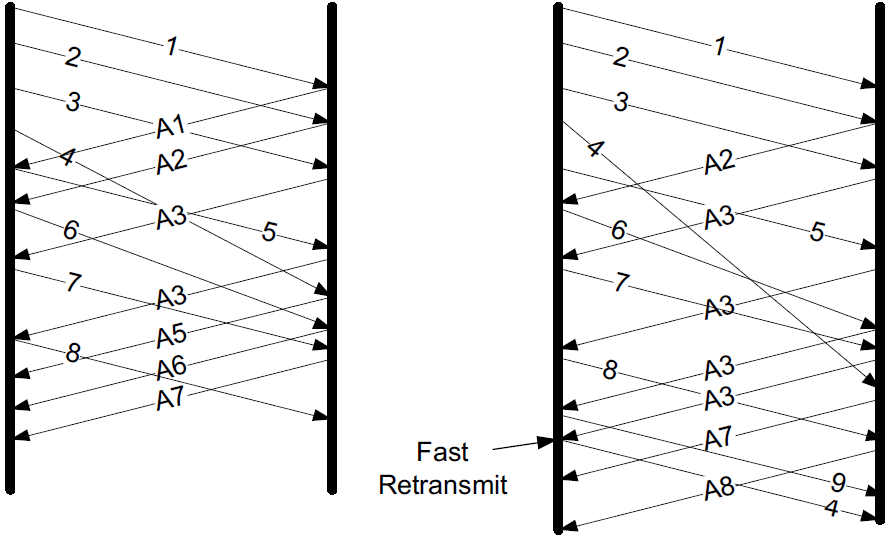
-
The left portion of the figure indicates how TCP behaves with light reordering, where dupthresh is set to 3.
In this case, the single duplicate ACK does not affect TCP. It is effectively ignored and TCP overcomes the reordering.
-
The right-hand side indicates what happens when a packet has been more severely reordered.
Because it is three positions out of sequence, three duplicate ACKs are generated. This invokes the fast retransmit procedure in the sending TCP, producing a duplicate segment at the receiver.
The problem of distinguishing loss from reordering is not trivial. Dealing with it involves trying to decide when a sender has waited long enough to try to fill apparent holes at the receiver.
Fortunately, severe reordering on the Internet is not common [J03], so setting dupthresh to a relatively small number (such as the default of 3) handles most circumstances. That said, there are a number of research projects that modify TCP to handle more severe reordering [LLY07]. Some of these adjust dupthresh dynamically, as does the Linux TCP implementation.
7.2. Duplication
Although rare, the IP protocol may deliver a single packet more than one time. This can happen, for example, when a link-layer network protocol performs a retransmission and creates two copies of the same packet.
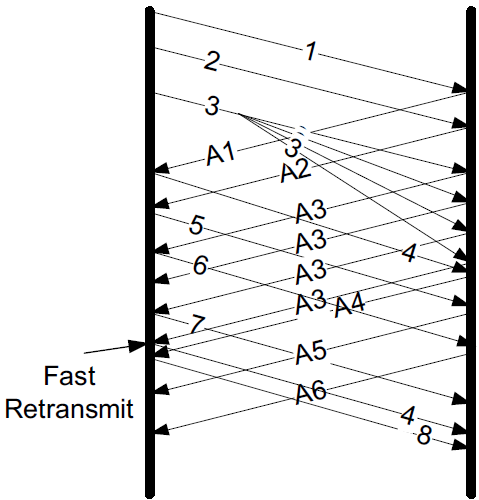
The effect of packet 3 being duplicated is to produce a series of duplicate ACKs from the receiver. This is enough to trigger a spurious fast retransmit, as the non-SACK sender may mistakenly believe that packets 5 and 6 have arrived earlier. With SACK (and DSACK, in particular) this is more easily diagnosed at the sender.
With DSACK, each of the duplicate ACKs for A3 contains DSACK information that segment 3 has already been received. Furthermore, none of them contains an indication of any out-of-order data, meaning the arriving packets (or their ACKs) must have been duplicates. TCP can often suppress spurious retransmissions in such cases.
8. Destination Metrics
Newer TCP implementations maintain many of the metrics such as srtt, rttvar and so on. in a routing or forwarding table entry or other systemwide data structure that exists even after TCP connections are closed.
When a new connection is created, TCP consults the data structure to see if there is any preexisting information regarding the path to the destination host with which it will be communicating.
If so, initial values for srtt, rttvar, and so on can be initialized to some value based on previous, relatively recent experience.
When a TCP connection closes down, it has the opportunity to update the statistics. This can be accomplished by replacing the existing statistics or updating them in some other way.
In the case of Linux 2.6, the values are updated to be the maximum of the existing values and those measured by the most recent TCP. These values can be inspected using the ip program available from the iproute2 suite of tools:
$ ip route show cache 10.170.109.10
10.170.109.10 via 192.168.91.137 dev ens32
cache expires 558se cmtu 1500 rtt 29ms rttvar 29ms cwnd 2 advmss 1460 hoplimit 649. Repacketization
When TCP times out and retransmits, it does not have to retransmit the identical segment. Instead, TCP is allowed to perform repacketization, sending a bigger segment, which can increase performance. Naturally, this bigger segment cannot exceed the MSS announced by the receiver and should not exceed the path MTU.
This is allowed in the protocol because TCP identifies the data being sent and acknowledged by its byte number, not its segment (or packet) number.
TCP’s ability to retransmit a segment with a different size from the original segment provides another way of addressing the retransmission ambiguity problem. This has been the basis of an idea called STODER [TZZ05] that uses repacketization to detect spurious timeouts.
We can easily see repacketization in action. We use our nc program as a server and connect to it with telnet.
-
First we type the line
hello there.This produces a segment of 13 data bytes, including the carriage-return and newline characters produced when the Enter key is pressed.
-
We then disconnect the network and type
line number 2(14 bytes, including the newline). -
We then wait about 45s, type
and 3, terminate the connection, and reconnect the network again:x@node-0:~$ telnet node-1 6666 Trying 192.168.91.137... Connected to node-1. Escape character is '^]'. hello there (1) line number 2 (2) and 3 (3) ^] telnet> q Connection closed. (4)1 (first line gets sent OK), (then we disconnect the Ethernet cable) 2 (this line gets retransmitted) 3 (this line gets transmitted and also carries the FIN bit field) 4 (reconnect Ethernet) The following highlighted line 7 show how the retransmission for sequence number 14 resulted in a repacketization to form a larger packet of size 22 bytes.
1 2 3 4 5 6 7 8 9
00:00:03.941676 IP 192.168.91.128.36242 > 192.168.91.137.6666: Flags [P.], seq 1:14, ack 1, win 502, options [nop,nop,TS val 3767361706 ecr 1569370162], length 13 00:00:03.942475 IP 192.168.91.137.6666 > 192.168.91.128.36242: Flags [.], ack 14, win 509, options [nop,nop,TS val 1569374104 ecr 3767361706], length 0 00:00:19.901087 IP 192.168.91.128.36242 > 192.168.91.137.6666: Flags [P.], seq 14:29, ack 1, win 502, options [nop,nop,TS val 3767377666 ecr 1569374104], length 15 .... 00:00:46.705168 IP 192.168.91.128.36242 > 192.168.91.137.6666: Flags [P.], seq 14:29, ack 1, win 502, options [nop,nop,TS val 3767404470 ecr 1569374104], length 15 00:00:51.189357 IP 192.168.91.128.36242 > 192.168.91.137.6666: Flags [FP.], seq 29:36, ack 1, win 502, options [nop,nop,TS val 3767408954 ecr 1569374104], length 7 00:01:13.587320 IP 192.168.91.128.36242 > 192.168.91.137.6666: Flags [FP.], seq 14:36, ack 1, win 502, options [nop,nop,TS val 3767431351 ecr 1569374104], length 22 00:01:13.587777 IP 192.168.91.137.6666 > 192.168.91.128.36242: Flags [F.], seq 1, ack 37, win 509, options [nop,nop,TS val 1569443750 ecr 3767431351], length 0 00:01:13.587800 IP 192.168.91.128.36242 > 192.168.91.137.6666: Flags [.], ack 2, win 502, options [nop,nop,TS val 3767431352 ecr 1569443750], length 0
Appendix A: Dropping Packets in Linux using tc and iptables
There are two simple ways to randomly drop packets on a Linux computer: using tc, the program dedicated for controlling traffic; and using iptables, the built-in firewall. [NETEM][IPTABLES][EBADNET][DPLTC]
A.1. Dropping Packets with tc
tc controls the transmit queues of your kernel. Normally when applications on your computer generate data to send, the data is passed to your kernel (via TCP and IP) for transmission on the network interface. The packets are transmitted in a first-in-first-out (FIFO) order.
tc allows you to change the queuing mechanisms (e.g. giving priority to specific type of packets), as well as emulate links by delaying and dropping packets.
Here we will use tc to drop packets. Because tc controls the transmit queues, we use it on a source computer (normally tc doesn’t impact on what is received by your computer, but there are exceptions).
x@node-0:~$ sudo tc qdisc replace dev ens32 root netem loss 25%netem is a special type of queuing discipline used for emulating networks. The above command tells the Linux kernel to drop on average 25% of the packets in the transmit queue. You can use different values of loss (e.g. 10%).
When using tc you can show the current queue disciplines using:
x@node-0:~$ sudo tc qdisc show dev ens32
qdisc netem 8001: root refcnt 2 limit 1000 loss 25%To show that it works, lets run an PING test. On computer node-1 (the computer where tc is NOT used) run:
x@node-1:~$ ping node-0 -c 4
PING node-0.localdomain (192.168.91.129) 56(84) bytes of data.
64 bytes from 192.168.91.129 (192.168.91.129): icmp_seq=1 ttl=64 time=0.424 ms
64 bytes from 192.168.91.129 (192.168.91.129): icmp_seq=3 ttl=64 time=3.14 ms
64 bytes from 192.168.91.129 (192.168.91.129): icmp_seq=4 ttl=64 time=0.643 ms
--- node-0.localdomain ping statistics ---
4 packets transmitted, 3 received, 25% packet loss, time 22ms
rtt min/avg/max/mdev = 0.424/1.400/3.135/1.230 msTo delete the above queue discipline use the delete command instead of replace:
x@node-0:~$ sudo tc qdisc delete dev ens32 root netem loss 25%
x@node-0:~$ sudo tc qdisc show dev ens32
qdisc pfifo_fast 0: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1|
When loss is used locally (not on a bridge or router), the loss is reported to the upper level protocols. This may cause TCP to resend and behave as if there was no loss. When testing protocol reponse to loss it is best to use a netem on a bridge or router. [netem] |
A.2. Dropping Packets with iptables
iptables allows you to create rules that specify how packets coming into your computer and going out of your computer are treated (and for routers, also forwarded by the router). The rules for packets coming in are in the INPUT chain, packets going out are OUTPUT, and packets forwarded are in the FORWARD chain. We will only use the INPUT chain.
The rules can filter packets based on common packet identifiers (IP addresses, ports, protocol numbers) as well as other matching criteria. We will use a special statistic matching module. For each packet that matches the filter, some action is applied (e.g. DROP the packet, ACCEPT the packet, or some more complex operation).
On computer node-1 (the destination), to view the current set of rules:
x@node-1:~$ sudo iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationThere are no rules in either of the three chains. Note that the default policy (if a packet does not match any rule) is to ACCEPT packets.
Now to add a rule to the INPUT chain to drop 25% of incoming packets on computer node-1:
x@node-1:~$ sudo iptables -A INPUT -m statistic --mode random --probability 0.25 -j DROP
x@node-1:~$ sudo iptables -L INPUT --line-numbers
Chain INPUT (policy ACCEPT)
num target prot opt source destination
1 DROP all -- anywhere anywhere statistic mode random probability 0.25000000000To demonstrate the packet dropping, run another PING test on the source node-0:
x@node-0:~$ ping node-1.local -c 4
PING node-1.local (192.168.91.135) 56(84) bytes of data.
64 bytes from 192.168.91.135 (192.168.91.135): icmp_seq=1 ttl=64 time=0.547 ms
64 bytes from 192.168.91.135 (192.168.91.135): icmp_seq=2 ttl=64 time=1.91 ms
64 bytes from 192.168.91.135 (192.168.91.135): icmp_seq=3 ttl=64 time=0.513 ms
--- node-1.local ping statistics ---
4 packets transmitted, 3 received, 25% packet loss, time 3007ms
rtt min/avg/max/mdev = 0.513/0.988/1.905/0.648 msReturning to computer node-1, to delete a rule you can use the -D option:
x@node-1:~$ sudo iptables -D INPUT -m statistic --mode random --probability 0.25 -j DROP
x@node-1:~$ sudo iptables -L INPUT
Chain INPUT (policy ACCEPT)
target prot opt source destination(or you can refer to rules by number, e.g. iptables -D INPUT 1 to delete rule 1 from the INPUT chain).
Alternatively we can specify to drop every n packets, starting from packet p. And we can combine with the standard filtering mechanisms of firewalls to only drop packets belong to a particular source/destination pair or application.
x@node-1:~$ sudo iptables -A INPUT -p udp --dport 6666 -m statistic --mode nth --every 4 --packet 3 -j DROPThis rule should drop packet 3, 7, 11, … for only one of the connections (with destination port 6666).
Here is the output of an iperf3 test at the source node-0. There are 25% packets dropped by the destination (receiver).
x@node-0:~$ iperf3 -c node-1 -p 6666 -t 10 -u
Connecting to host node-1, port 6666
[ 5] local 192.168.91.128 port 52026 connected to 192.168.91.137 port 6666
....
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Jitter Lost/Total Datagrams
[ 5] 0.00-10.00 sec 1.25 MBytes 1.05 Mbits/sec 0.000 ms 0/906 (0%) sender
[ 5] 0.00-10.04 sec 962 KBytes 784 Kbits/sec 0.337 ms 226/906 (25%) receiverReferences
-
[TCPIP1] Kevin Fall, W. Stevens TCP/IP Illustrated: The Protocols, Volume 1. 2nd edition, Addison-Wesley Professional, 2011
-
[J88] V. Jacobson, Congestion Avoidance and Control, See https://ee.lbl.gov/papers/congavoid.pdf
-
[IPTABLES] Using iptables [online]. https://www.netfilter.org/documentation/HOWTO/packet-filtering-HOWTO-7.html
-
[EBADNET] Emulating Bad Networks [online]. https://samwho.dev/blog/emulating-bad-networks/
-
[DPLTC] Dropping Packets in Ubuntu Linux using tc and iptables [online]. https://sandilands.info/sgordon/dropping-packets-in-ubuntu-linux-using-tc-and-iptables
-
[RFC1122] R. Braden, ed., Requirements for Internet Hosts—Communication Layers, Internet RFC 1122/STD 0003, Oct. 1989, See https://www.rfc-editor.org/rfc/rfc1112
-
[RFC2018] M. Mathis, J. Mahdavi, S. Floyd, and A. Romanow, TCP Selective Acknowledgment Options, Internet RFC 2018, Oct. 1996, See https://www.rfc-editor.org/rfc/rfc2018
-
[RFC2883] S. Floyd, J. Mahdavi, M. Mathis, and M. Podolsky, An Extension to the Selective Acknowledgement (SACK) Option for TCP, Internet RFC 2883, July 2000, See https://www.rfc-editor.org/rfc/rfc2883
-
[RFC3517] E. Blanton, M. Allman, K. Fall, and L. Wang, A Conservative Selective Acknowledgment (SACK)-Based Loss Recovery Algorithm for TCP, Internet RFC 3517, Apr. 2003, See https://www.rfc-editor.org/rfc/rfc3517
-
[RFC3522] R. Ludwig and M. Meyer, The Eifel Detection Algorithm for TCP, Internet RFC 3522 (experimental), Apr. 2003.
-
[RFC5681] M. Allman, V. Paxson, E. Blanton, TCP Congestion Control, Internet RFC 5681, Sept. 2009, See https://www.rfc-editor.org/rfc/rfc5681
-
[RFC5682] P. Sarolahti, M. Kojo, K. Yamamoto, and M. Hata, Forward RTORecovery (F-RTO): An Algorithm for Detecting Spurious Retransmission Timeouts with TCP, Internet RFC 5682, Sept. 2009.
-
[RFC6298] V. Paxson, M. Allman, and J. Chu, Computing TCP’s Retransmission Timer, Internet RFC 6298, June 2011, See https://www.rfc-editor.org/rfc/rfc6298
-
[J03] S. Jaiswal et al. Measurement and Classification of Out-of-Sequence Packets in a Tier-1 IP Backbone, Proc. IEEE INFOCOM, Apr. 2003.
-
[LLY07] K. Leung, V. Li, and D. Yang "An Overview of Packet Reordering in Transmission Control Protocol (TCP): Problems, Solutions and Challenges". IEEE Trans. Parallel and Distributed Systems, 18(4), Apr. 2007.
-
[TZZ05] K. Tan and Q. Zhang STODER: A Robust and Efficient Algorithm for Handling Spurious Timeouts in TCP. Proc. IEEE Globecomm, Dec. 2005.