
"Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once." — Rob Pike
- 1. Threads and threading
- 1.1. Processes and threads
- 1.2. How to use multithreading in .NET
- 1.3. Using threads and threading
- 1.4. Cancellation in Managed Threads
- 1.5. Foreground and background threads
- 1.6. The managed thread pool
- 1.7. Overview of synchronization primitives
- 1.8. The volatile keyword
- 1.9. ThreadLocal<T>
- 1.10. Lazy<T>
- 1.11. Thread-safe collections
- 2. Asynchronous programming
- 3. Parallel programming in .NET
- Appendix A: FAQ
- A.1. What happens on Thread.Sleep(0) in .NET?
- A.2. What are the worker and completion port threads?
- A.3. How does .NET identify I/O-bound or compute-bound operations?
- A.4. How does CLR manage the number of threads (worker and I/O threads) in the ThreadPool?
- A.5. What’s the algorithm of the thread pool in .NET?
- A.6. What if Interlocked.Increment a 64-bit integer on a 32-bit hardware?
- A.7. How does .NET make the multiple CPU instructions as an atomic?
- A.8. I heard there are some risk on atomic operations in Go or sth else?
- A.9. What’s ABA problems?
- A.10. How to understand 'hardware, compilers, and the language memory model'?
- A.11. Anyway, for a single operation like Interlocked.Increment, it will always ensure it as an atomic?
- A.12. How to understand the volatile keyword in .NET?
- A.13. What’s the diff of volatile keyword and Volatile class?
- A.14. It seems we should avoid to use the volatile keyword?
- A.15. What’s the diff of asynchronous and parallel programming in .NET?
- A.16. What’s the control meaning in async and await programming?
- A.17. How to understand "Async methods don’t require multithreading because an async method doesn’t run on its own thread."?
- A.18. Can the async/await improve the responsiveness on ASP.NET Core?
- A.19. Is there a SynchronizationContext on ASP.NET Core?
- A.20. What’s the diff of AsOrdered and AsUnordered in PLINQ?
- References
1. Threads and threading
Multithreading can be used to increase the responsiveness of an application and, if an application runs on a multiprocessor or multi-core system, increase its throughput. [1]
1.1. Processes and threads
A process is an executing program and an operating system uses processes to separate the applications that are being executed.
A thread is the basic unit to which an operating system allocates processor time.
-
Each thread has a scheduling priority and maintains a set of structures the system uses to save the thread context when the thread’s execution is paused.
-
The thread context includes all the information the thread needs to seamlessly resume execution, including the thread’s set of CPU registers and stack.
-
Multiple threads can run in the context of a process.
-
All threads of a process share its virtual address space.
-
A thread can execute any part of the program code, including parts currently being executed by another thread.
-
| .NET Framework provides a way to isolate applications within a process with the use of application domains. (Application domains are not available on .NET Core.) |
By default, a .NET program is started with a single thread, often called the primary thread. However, it can create additional threads to execute code in parallel or concurrently with the primary thread. These threads are often called worker threads.
1.2. How to use multithreading in .NET
Starting with .NET Framework 4, the recommended way to utilize multithreading is to use Task Parallel Library (TPL) and Parallel LINQ (PLINQ).
Both TPL and PLINQ rely on the ThreadPool threads. The System.Threading.ThreadPool class provides a .NET application with a pool of worker threads.
At last, the System.Threading.Thread class represents a managed thread.
1.3. Using threads and threading
With .NET, applications can be wrote that perform multiple operations at the same time. Operations with the potential of holding up other operations can execute on separate threads, a process that is known as multithreading or free threading. [2]
1.3.1. Create and start a new thread
A new thread can be created by creating a new instance of the System.Threading.Thread class. A delegate or method name can be provided to the constructor to be executed on the new thread. To start a created thread, call the Thread.Start method.
new Thread(() => Console.WriteLine("Hello Thread")).Start();1.3.2. Stop a thread
To terminate the execution of a thread, use the System.Threading.CancellationToken which provides a unified way to cooperatively stop threads.
Sometimes it’s not possible to stop a thread cooperatively because it runs third-party code not designed for cooperative cancellation. To terminate the execution of a thread forcibly, in .NET Framework, use the Thread.Abort method that raises a ThreadAbortException on the thread on which it’s invoked.
The Thread.Abort method isn’t supported in .NET Core. To terminate the execution of third-party code forcibly in .NET Core, run it in the separate process and use the Process.Kill method.
|
Use the Thread.Join method to make the calling thread (that is, the thread that calls the method) wait for the termination of the thread being stopped.
1.3.3. Pause or interrupt a thread
Use the Thread.Sleep method to pause the current thread for a specified amount of time. A blocked thread can be interrupted by calling the Thread.Interrupt method.
Calling the Thread.Sleep method causes the current thread to immediately block for the number of milliseconds or the time interval that passed to the method, and yields the remainder of its time slice to another thread. Once that interval elapses, the sleeping thread resumes execution. [4]
Calling the Thread.Sleep(0) causes the current thread to yield its remaining time slice immediately, voluntarily handing over the CPU to other threads, though it might not lead to a context switch if no same- or higher-priority threads are waiting.
|
Calling Thread.Sleep with a value of Timeout.Infinite causes a thread to sleep until it is interrupted by another thread that calls the Thread.Interrupt method on the sleeping thread, or until it is terminated by a call to its Thread.Abort method.
|
One thread cannot call Thread.Sleep on another thread. Thread.Sleep is a static method that always causes the current thread to sleep.
|
A waiting thread can be interrupted by calling the Thread.Interrupt to throw a ThreadInterruptedException to break the thread out of the blocking call.
// Interrupts a thread that is in the WaitSleepJoin thread state.
public void Interrupt ();-
The waiting thread should catch the
ThreadInterruptedExceptionand do whatever is appropriate to continue working. -
If the thread ignores the exception, the runtime catches the exception and stops the thread.
-
If this thread is not currently blocked in a wait, sleep, or join state, it will be interrupted when it next begins to block.
ThreadState.WaitSleepJoin: The thread is blocked.This could be the result of calling
Sleep(Int32)orJoin(), of requesting a lock - for example, by callingEnter(Object)orWait(Object, Int32, Boolean)- or of waiting on a thread synchronization object such asManualResetEvent. -
If the thread never blocks, the exception is never thrown, and thus the thread might complete without ever being interrupted.
-
If a wait is a managed wait, then
Thread.InterruptandThread.Abortboth wake the thread immediately. -
If a wait is an unmanaged wait (for example, a platform invoke call to the Win32
WaitForSingleObjectfunction), neitherThread.InterruptnorThread.Abortcan take control of the thread until it returns to or calls into managed code. -
In managed code, the behavior is as follows:
-
Thread.Interruptwakes a thread out of any wait it might be in and causes aThreadInterruptedExceptionto be thrown in the destination thread. -
.NET Framework only:
Thread.Abortwakes a thread out of any wait it might be in and causes aThreadAbortExceptionto be thrown on the thread.
-
Thread sleepingThread = new Thread(() =>
{
Console.WriteLine("Thread '{0}' about to sleep indefinitely.", Thread.CurrentThread.Name);
try
{
Thread.Sleep(Timeout.Infinite);
}
catch (ThreadInterruptedException)
{
Console.WriteLine("Thread '{0}' awoken.", Thread.CurrentThread.Name);
}
finally
{
Console.WriteLine("Thread '{0}' executing finally block.", Thread.CurrentThread.Name);
}
Console.WriteLine("Thread '{0} finishing normal execution.", Thread.CurrentThread.Name);
});
sleepingThread.Name = "Sleeping";
sleepingThread.Start();
Thread.Sleep(2000);
sleepingThread.Interrupt();
// Thread 'Sleeping' about to sleep indefinitely.
// Thread 'Sleeping' awoken.
// Thread 'Sleeping' executing finally block.
// Thread 'Sleeping finishing normal execution.1.3.4. Busy waiting
Busy waiting (a.k.a, spinning) is a technique where a thread repeatedly checks for a condition to be true without releasing the CPU, which can lead to inefficient CPU usage.
Calling the Thread.SpinWait method causes a thread to wait the number of times defined by the iterations parameter.
-
In contrast to blocking (like using
Thread.Sleep()or synchronization primitives as locks), a busy-waiting thread continuously polls a condition, consuming CPU cycles even though it’s not performing useful work. -
Compared to a basic loop,
Thread.SpinWaitminimizes CPU waste by adjusting its spinning behavior with adaptive spinning and hardware-level optimizations, backing off after a few spins, and may yield control to the OS for a context switch once a threshold is reached.int iterations = 10; // Number of spins before the thread may yield while (!conditionMet) { Thread.SpinWait(iterations); // Spins for the specified number of iterations }
|
The |
1.4. Cancellation in Managed Threads
Starting with .NET Framework 4, .NET uses a unified model for cooperative cancellation of asynchronous or long-running synchronous operations which is based on a lightweight object called a cancellation token. [3]
-
The object that invokes one or more cancelable operations, for example by creating new threads or tasks, passes the token to each operation. Individual operations can in turn pass copies of the token to other operations.
-
At some later time, the object that created the token can use it to request that the operations stop what they are doing.
-
Only the requesting object can issue the cancellation request, and each listener is responsible for noticing the request and responding to it in an appropriate and timely manner.
The general pattern for implementing the cooperative cancellation model is:
-
Instantiate a
CancellationTokenSourceobject, which manages and sends cancellation notification to the individual cancellation tokens. -
Pass the token returned by the
CancellationTokenSource.Tokenproperty to each task or thread that listens for cancellation. -
Provide a mechanism for each task or thread to respond to cancellation.
-
Call the
CancellationTokenSource.Cancelmethod to provide notification of cancellation.
// Create the token source.
CancellationTokenSource cts = new CancellationTokenSource();
// Pass the token to the cancelable operation.
ThreadPool.QueueUserWorkItem(obj =>
{
if (obj is CancellationToken token)
{
for (int i = 0; i < 100000; i++)
{
if (token.IsCancellationRequested)
{
Console.WriteLine("In iteration {0}, cancellation has been requested...", i + 1);
// Perform cleanup if necessary.
//...
// Terminate the operation.
break;
}
// Simulate some work.
Thread.SpinWait(500000);
}
}
}, cts.Token);
Thread.Sleep(2500);
// Request cancellation.
cts.Cancel();
Console.WriteLine("Cancellation set in token source...");
Thread.Sleep(2500);
// Cancellation should have happened, so call Dispose.
cts.Dispose(); // or using CancellationTokenSource cts = ...
// The example displays output like the following:
// Cancellation set in token source...
// In iteration 1430, cancellation has been requested...
The CancellationTokenSource class implements the IDisposable interface. Be sure to call the Dispose method when finished using the cancellation token source to free any unmanaged resources it holds.
|
The following illustration shows the relationship between a token source and all the copies of its token.
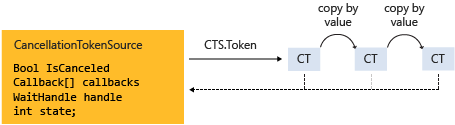
The cooperative cancellation model makes it easier to create cancellation-aware applications and libraries, and it supports the following features:
-
Cancellation is cooperative and is not forced on the listener. The listener determines how to gracefully terminate in response to a cancellation request.
-
Requesting is distinct from listening. An object that invokes a cancelable operation can control when (if ever) cancellation is requested.
-
The requesting object issues the cancellation request to all copies of the token by using just one method call.
-
A listener can listen to multiple tokens simultaneously by joining them into one linked token.
-
User code can notice and respond to cancellation requests from library code, and library code can notice and respond to cancellation requests from user code.
-
Listeners can be notified of cancellation requests by polling, callback registration, or waiting on wait handles.
In more complex cases, it might be necessary for the user delegate to notify library code that cancellation has occurred.
-
In such cases, the correct way to terminate the operation is for the delegate to call the
ThrowIfCancellationRequested(), method, which will cause anOperationCanceledExceptionto be thrown. -
Library code can catch this exception on the user delegate thread and examine the exception’s token to determine whether the exception indicates cooperative cancellation or some other exceptional situation.
The System.Threading.Tasks.Task and System.Threading.Tasks.Task<TResult> classes support cancellation by using cancellation tokens. The operation can be terminated by using one of these options:
-
By returning from the delegate. In many scenarios, this option is sufficient. However, a task instance that’s canceled in this way transitions to the
TaskStatus.RanToCompletionstate, not to theTaskStatus.Canceledstate.
-
By throwing an
OperationCanceledExceptionand passing it the token on which cancellation was requested. -
The preferred way to perform is to use the
ThrowIfCancellationRequestedmethod to throw aOperationCanceledExceptionif this token has had cancellation requested.A task that’s canceled in this way transitions to the
Canceledstate, which the calling code can use to verify that the task responded to its cancellation request.
When a task instance observes an OperationCanceledException thrown by the user code, it compares the exception’s token to its associated token (the one that was passed to the API that created the Task).
-
If the tokens are same and the token’s
IsCancellationRequestedproperty returnstrue, the task interprets this as acknowledging cancellation and transitions to theCanceledstate. -
If don’t use a
WaitorWaitAllmethod to wait for the task, then the task just sets its status toCanceled.
If a Task is being waited on and it transitions to the Canceled state, a System.Threading.Tasks.TaskCanceledException exception wrapped in an AggregateException exception is thrown to indicate successful cancellation instead of a faulty situation. Therefore, the task’s Exception property returns null.
If the token’s IsCancellationRequested property returns false or if the exception’s token doesn’t match the Task’s token, the OperationCanceledException is treated like a normal exception, causing the Task to transition to the Faulted state. The presence of other exceptions will also cause the Task to transition to the Faulted state.
It’s possible that a task might continue to process some items after cancellation is requested.
|
Please note that if use |
1.5. Foreground and background threads
A managed thread is either a background thread or a foreground thread.
-
Background threads are identical to foreground threads with one exception: a background thread does not keep the managed execution environment running.
-
Once all foreground threads have been stopped in a managed process (where the .exe file is a managed assembly), the system stops all background threads and shuts down.
Use the Thread.IsBackground property to determine whether a thread is a background or a foreground thread, or to change its status.
-
Threads that belong to the managed thread pool (that is, threads whose
IsThreadPoolThreadproperty istrue) are background threads. -
All threads that enter the managed execution environment from unmanaged code are marked as background threads.
-
All threads generated by creating and starting a new
Threadobject are by default foreground threads.
The |
1.6. The managed thread pool
The System.Threading.ThreadPool class provides an application with a pool of worker threads that are managed by the system, allowing concentration on application tasks rather than thread management. [5]
-
For short tasks that require background processing, the managed thread pool is an easy way to take advantage of multiple threads.
-
Use of the thread pool is significantly easier in Framework 4 and later, since
TaskandTask<TResult>objects can be created to perform asynchronous tasks on thread pool threads.
.NET uses thread pool threads for many purposes, including Task Parallel Library (TPL) operations, asynchronous I/O completion, timer callbacks, registered wait operations, asynchronous method calls using delegates, and System.Net socket connections.
1.6.1. Thread pool characteristics
Thread pool threads are background threads.
-
Each thread uses the default stack size, runs at the default priority, and is in the multithreaded apartment.
-
Once a thread in the thread pool completes its task, it’s returned to a queue of waiting threads, where it can be reused, thus avoiding the cost of creating a new thread for each task.
| There is only one thread pool per process. |
public static class MyThreadPool
{
private readonly static BlockingCollection<(Action, ExecutionContext?)> s_workItems = [];
public static void QueueUserWorkItem(Action callBack)
{
s_workItems.Add((callBack, ExecutionContext.Capture()));
}
static MyThreadPool()
{
for (int i = 0; i < Environment.ProcessorCount; i++)
{
new Thread(_ =>
{
while (true)
{
(Action workItem, ExecutionContext? context) = s_workItems.Take();
if (context is null)
{
workItem();
}
else
{
ExecutionContext.Run(context, delegate { workItem(); }, null);
}
}
})
{ IsBackground = true }.UnsafeStart();
}
}
}1.6.2. Exceptions in thread pool threads
Unhandled exceptions in thread pool threads terminate the process. There are three exceptions to this rule:
-
A
System.Threading.ThreadAbortExceptionis thrown in a thread pool thread becauseThread.Abortwas called. -
A
System.AppDomainUnloadedExceptionis thrown in a thread pool thread because the application domain is being unloaded. -
The common language runtime or a host process terminates the thread.
1.6.3. Maximum number of thread pool threads
The number of operations that can be queued to the thread pool is limited only by available memory. However, the thread pool limits the number of threads that can be active in the process simultaneously.
-
If all thread pool threads are busy, additional work items are queued until threads to execute them become available.
-
The default size of the thread pool for a process depends on several factors, such as the size of the virtual address space.
-
A process can call the
ThreadPool.GetMaxThreadsmethod to determine the number of threads.
1.6.4. Thread pool minimums
The thread pool provides new worker threads or I/O completion threads on demand until it reaches a specified minimum for each category.
-
A process can use the
ThreadPool.GetMinThreadsmethod to obtain these minimum values. -
When demand is low, the actual number of thread pool threads can fall below the minimum values.
When a minimum is reached, the thread pool can create additional threads or wait until some tasks complete.
-
The thread pool creates and destroys worker threads in order to optimize throughput, which is defined as the number of tasks that complete per unit of time.
-
Too few threads might not make optimal use of available resources, whereas too many threads could increase resource contention.
|
A process can use the |
1.6.5. When not to use thread pool threads
There are several scenarios in which it’s appropriate to create and manage threads instead of using thread pool threads:
-
A foreground thread is required.
-
A thread with a particular priority is needed.
-
Tasks cause the thread to block for long periods of time. The thread pool has a maximum number of threads, so a large number of blocked thread pool threads might prevent tasks from starting.
-
Threads need to be placed into a single-threaded apartment. All ThreadPool threads are in the multithreaded apartment.
-
A stable identity needs to be associated with the thread, or a thread should be dedicated to a task.
1.7. Overview of synchronization primitives
.NET provides a range of types to synchronize access to a shared resource or coordinate thread interaction. [6]
1.7.1. WaitHandle and lightweight synchronization types
Multiple .NET synchronization primitives derive from the System.Threading.WaitHandle class, which encapsulates a native operating system synchronization handle and uses a signaling mechanism for thread interaction.
-
System.Threading.Mutex, which grants exclusive access to a shared resource. The state of a mutex is signaled if no thread owns it.Mutex mux = new(); int count = 0; Parallel.For(0, 101, i => { mux.WaitOne(); try { count += i; } finally { mux.ReleaseMutex(); } }); Console.Write(count); // 5050 -
System.Threading.Semaphore, which limits the number of threads that can access a shared resource or a pool of resources concurrently. The state of a semaphore is set to signaled when its count is greater than zero, and nonsignaled when its count is zero.Semaphore mux = new(1, 1); int count = 0; Parallel.For(0, 101, i => { mux.WaitOne(); try { count += i; } finally { mux.Release(); } }); Console.Write(count); // 5050 -
System.Threading.EventWaitHandle, which represents a thread synchronization event and can be either in a signaled (allowing waiting threads to proceed) or unsignaled (blocking waiting threads) state.-
An
EventWaitHandlecreated with theEventResetMode.AutoResetflag resets automatically when signaled, after releasing a single waiting thread. -
An
EventWaitHandlecreated with theEventResetMode.ManualResetflag remains signaled until its Reset method is called. -
System.Threading.AutoResetEvent, which derives fromEventWaitHandleand, when signaled, resets automatically to an unsignaled state after releasing a single waiting thread. -
System.Threading.ManualResetEvent, which derives fromEventWaitHandleand, when signaled, stays in a signaled state until theResetmethod is called.EventWaitHandle mux = new(true, EventResetMode.AutoReset); int count = 0; Parallel.For(0, 101, i => { mux.WaitOne(); try { count += i; } finally { mux.Set(); // Sets the state of the event to signaled. } }); Console.Write(count); // 5050
-
In .NET Framework, because WaitHandle derives from System.MarshalByRefObject, these types can be used to synchronize the activities of threads across application domain boundaries.
In .NET Framework, .NET Core, and .NET 5+, some of these types can represent named system synchronization handles, which are visible throughout the operating system and can be used for the inter-process synchronization:
-
Mutex
-
Semaphore (on Windows)
-
EventWaitHandle (on Windows)
Lightweight synchronization types don’t rely on underlying operating system handles and typically provide better performance.
-
However, they cannot be used for the inter-process synchronization. Use those types for thread synchronization within one application.
-
Some of those types are alternatives to the types derived from
WaitHandle. -
For example,
SemaphoreSlimis a lightweight alternative toSemaphore.public class SemaphoreSlim : IDisposable public sealed class Semaphore : WaitHandleSemaphoreSlim mux = new(1, 1); int count = 0; Parallel.For(0, 101, i => { mux.Wait(); try { count += i; } finally { mux.Release(); } }); Console.Write(count); // 5050
1.7.2. Synchronization of access to a shared resource
.NET provides a range of synchronization primitives to control access to a shared resource by multiple threads.
1.7.2.1. Monitor
The System.Threading.Monitor class grants mutually exclusive access to a shared resource by acquiring or releasing a lock on the object that identifies the resource.
-
While a lock is held, the thread that holds the lock can again acquire and release the lock.
-
The
Entermethod acquires a released lock. -
The
Monitor.TryEntermethod can also be used to specify the amount of time during which a thread attempts to acquire a lock. -
Any other thread is blocked from acquiring the lock and the
Monitor.Entermethod waits until the lock is released. -
Because the Monitor class has thread affinity, the thread that acquired a lock must release the lock by calling the
Monitor.Exitmethod. -
The interaction of threads can be coordinated to acquire a lock on the same object by using the
Monitor.Wait,Monitor.Pulse, andMonitor.PulseAllmethods.
|
Use the |
var ch = new BlockingChannel<int?>();
ThreadPool.QueueUserWorkItem(async _ =>
{
for (int i = 0; i < 10; i++)
{
await Task.Delay(200);
ch.Write(i);
}
ch.Write(null);
});
foreach (var v in ch)
{
if (v == null) break;
Console.Write($"{v} ");
}
sealed class BlockingChannel<T> : IEnumerable<T?>
{
private T? _data;
private bool _hasData;
private readonly object _lockObj = new();
public void Write(T? data)
{
lock (_lockObj)
{
while (_hasData) Monitor.Wait(_lockObj); // releases and blocks: conditional variable
_data = data;
_hasData = true;
Monitor.Pulse(_lockObj); // wake one waiting thread on _lockObj: Waiting → Ready
}
}
public T? Read()
{
lock (_lockObj)
{
while (!_hasData) Monitor.Wait(_lockObj); // conditional variable
var data = _data;
_hasData = false;
Monitor.Pulse(_lockObj);
return data;
}
}
public IEnumerator<T?> GetEnumerator()
{
while (true)
{
yield return Read();
}
}
IEnumerator IEnumerable.GetEnumerator() => GetEnumerator();
}
// $ dotnet run
// 0 1 2 3 4 5 6 7 8 9// Go
package main
import (
"fmt"
)
func main() {
ch := make(chan int)
go func(ch chan<- int) {
for i := 0; i < 10; i++ {
ch <- i
}
close(ch)
}(ch)
for v := range ch {
fmt.Printf("%d ", v)
}
}1.7.2.2. Lock
.NET 9 is introducing a new System.Threading.Lock type as a better alternative to existing monitor-based locking.
-
It is recommended to use the
EnterScopemethod with a language construct that automatically disposes the returnedLock.Scopesuch as the C#usingkeyword, or to use the C#lockkeyword, as these ensure that the lock is exited in exceptional cases. -
When using the C#
lockkeyword or similar to enter and exit a lock, the type of the expression must be preciselySystem.Threading.Lock. -
If the type of the expression is anything else, such as
Objector a generic type likeT, a different implementation that is not interchangeable can be used instead (such asMonitor).public sealed class ExampleDataStructure { private readonly Lock _lockObj = new(); public void Modify() { lock (_lockObj) { // Critical section associated with _lockObj } using (_lockObj.EnterScope()) { // Critical section associated with _lockObj } _lockObj.Enter(); try { // Critical section associated with _lockObj } finally { _lockObj.Exit(); } if (_lockObj.TryEnter()) { try { // Critical section associated with _lockObj } finally { _lockObj.Exit(); } } } }
1.7.2.3. Mutex
The System.Threading.Mutex class, like Monitor, grants exclusive access to a shared resource.
-
Use one of the
Mutex.WaitOnemethod overloads to request the ownership of a mutex. -
Like Monitor, Mutex has thread affinity and the thread that acquired a mutex must release it by calling the
Mutex.ReleaseMutexmethod. -
Unlike
Monitor, theMutexclass can be used for inter-process synchronization.-
To do that, use a named mutex, which is visible throughout the operating system.
-
To create a named mutex instance, use a Mutex constructor that specifies a name.
-
Call the
Mutex.OpenExistingmethod to open an existing named system mutex.
-
1.7.2.4. SpinLock
The System.Threading.SpinLock structure, like Monitor, grants exclusive access to a shared resource based on the availability of a lock.
-
When SpinLock attempts to acquire a lock that is unavailable, it waits in a loop, repeatedly checking until the lock becomes available.
int sum = 0; SpinLock spin = new(); Parallel.For(1, 101, i => { bool locked = false; try { spin.Enter(ref locked); sum += i; } finally { if (locked) spin.Exit(); } }); Console.Write(sum); // 5050
1.7.2.5. SpinWait
The System.Threading.SpinWait is a lightweight synchronization type that you can use in low-level scenarios to avoid the expensive context switches and kernel transitions that are required for kernel events.
-
On multicore computers, when a resource is not expected to be held for long periods of time, it can be more efficient for a waiting thread to spin in user mode for a few dozen or a few hundred cycles, and then retry to acquire the resource.
-
If the resource is available after spinning, then several thousand cycles have been saved.
-
If the resource is still not available, then only a few cycles have been spent and a kernel-based wait can still be entered.
-
The spinning-then-waiting combination is sometimes referred to as a two-phase wait operation.
-
-
On single-processor machines, yields are always used instead of busy waits, and on computers with Intel processors employing Hyper-Threading technology, it helps to prevent hardware thread starvation.
-
SpinWaitis designed to be used in conjunction with the .NET types that wrap kernel events such asManualResetEvent.// a two-phase wait operation int[] nums = Enumerable.Range(0, 10).ToArray(); var latch = new Latch(); var task = Parallel.ForEachAsync(nums, (i, _) => { latch.Wait(); nums[i]++; return ValueTask.CompletedTask; }); await Task.Run(async () => { for (int i = 0; i < 3; i++) { await Task.Delay(1_000); Console.WriteLine("tick!"); } Console.WriteLine("The door is opening..."); latch.Set(); }); Console.WriteLine(string.Join(' ', nums)); // tick! // tick! // tick! // The door is opening... // 1 2 3 4 5 6 7 8 9 10 sealed class Latch { private readonly Lock _lockObj = new(); private readonly ManualResetEvent _mre = new(false); private bool _state = false; public void Set() { lock (_lockObj) { _state = true; _mre.Set(); } } public void Wait() { if (!_state) { var spin = new SpinWait(); while (!_state) { if (!spin.NextSpinWillYield) { spin.SpinOnce(); } else { _mre.WaitOne(); } } } } } -
When performing a spinning operation until a condition is true without a two-phase wait, enabling
SpinWaitto perform its context switches ensures it behaves responsibly in the Windows operating system environment.// a lock-free concurrent stack sealed class MyConcurrentStack<T> { private class Node { public Node? Next { get; set; } public T Value { get; set; } = default!; } private volatile Node? _head; public void Push(T item) { var spin = new SpinWait(); var node = new Node { Value = item }; Node? head; while (true) { head = _head; node.Next = head; if (Interlocked.CompareExchange(ref _head, node, head) == head) break; spin.SpinOnce(); if (spin.Count > 100) { spin.Reset(); Thread.Yield(); } } } public bool TryPop(out T item) { item = default!; var spin = new SpinWait(); Node? head; while (true) { head = _head; if (head is null) return false; if (Interlocked.CompareExchange(ref _head, head?.Next, head) == head) { item = head!.Value; return true; } spin.SpinOnce(); } } } -
SpinWaitis not generally useful for ordinary applications.-
In most cases, the synchronization classes provided by the .NET Framework should be used, such as
Monitor. -
For most purposes where spin waiting is required, however, the
SpinWaittype should be preferred over theThread.SpinWaitmethod.
-
1.7.2.6. ReaderWriterLockSlim
The System.Threading.ReaderWriterLockSlim class grants exclusive access to a shared resource for writing and allows multiple threads to access the resource simultaneously for reading.
-
ReaderWriterLockSlimmight be used to synchronize access to a shared data structure that supports thread-safe read operations but requires exclusive access to perform write operations. -
When a thread requests exclusive access (e.g., by calling the
EnterWriteLockmethod), subsequent reader and writer requests block until all existing readers have exited the lock, and the writer has entered and exited the lock. -
Use upgradeable mode when a thread usually accesses the resource that is protected in read mode, but may need to enter write mode if certain conditions are met.
-
A thread in upgradeable mode can downgrade to read mode or upgrade to write mode.
-
Only one thread can enter upgradeable mode at any given time.
-
If a thread is in upgradeable mode, and there are no threads waiting to enter write mode, any number of other threads can enter read mode, even if there are threads waiting to enter upgradeable mode.
class SynchronizedDictionary<TKey, TValue> : IDisposable where TKey : notnull { private readonly Dictionary<TKey, TValue> _dictionary = new Dictionary<TKey, TValue>(); private readonly ReaderWriterLockSlim _lock = new ReaderWriterLockSlim(); public void Add(TKey key, TValue value) { _lock.EnterWriteLock(); try { _dictionary.Add(key, value); } finally { _lock.ExitWriteLock(); } } public void TryAddValue(TKey key, TValue value) { _lock.EnterUpgradeableReadLock(); try { if (_dictionary.TryGetValue(key, out var res) && res != null && res.Equals(value)) return; _lock.EnterWriteLock(); try { _dictionary[key] = value; } finally { _lock.ExitWriteLock(); } } finally { _lock.ExitUpgradeableReadLock(); } } public bool TryGetValue(TKey key, [MaybeNullWhen(false)] out TValue value) { _lock.EnterReadLock(); try { return _dictionary.TryGetValue(key, out value); } finally { _lock.ExitReadLock(); } } private bool _disposed; protected virtual void Dispose(bool disposing) { if (!_disposed) { if (disposing) { // perform managed resource cleanup here _lock.Dispose(); } // perform unmanaged resource cleanup here _disposed = true; } } ~SynchronizedDictionary() => Dispose(disposing: false); public void Dispose() { Dispose(disposing: true); GC.SuppressFinalize(this); } }
-
1.7.2.7. Semaphore and SemaphoreSlim
The System.Threading.Semaphore and System.Threading.SemaphoreSlim classes limit the number of threads that can access a shared resource or a pool of resources concurrently.
-
Additional threads that request the resource wait until any thread releases the semaphore.
-
Because the semaphore doesn’t have thread affinity, a thread can acquire the semaphore and another one can release it.
-
SemaphoreSlim is a lightweight alternative to Semaphore and can be used only for synchronization within a single process boundary.
-
On Windows, Semaphore can be used for the inter-process synchronization.
-
SemaphoreSlim doesn’t support named system semaphores.
var ch = new BlockingChannel<int?>(); ThreadPool.QueueUserWorkItem(async _ => { for (int i = 0; i < 10; i++) { await Task.Delay(200); await ch.WriteAsync(i); } await ch.WriteAsync(null); }); await foreach (var v in ch) { if (v == null) break; Console.Write($"{v} "); } sealed class BlockingChannel<T> : IAsyncEnumerable<T?> { private T? _data; private readonly SemaphoreSlim _readSemaphore = new(0); private readonly SemaphoreSlim _writeSemaphore = new(1); public async ValueTask WriteAsync(T? data, CancellationToken cancellationToken = default) { await _writeSemaphore.WaitAsync(cancellationToken).ConfigureAwait(false); cancellationToken.ThrowIfCancellationRequested(); _data = data; _readSemaphore.Release(); } public async ValueTask<T?> ReadAsync(CancellationToken cancellationToken = default) { await _readSemaphore.WaitAsync(cancellationToken).ConfigureAwait(false); cancellationToken.ThrowIfCancellationRequested(); var data = _data; _writeSemaphore.Release(); return data; } public async IAsyncEnumerator<T?> GetAsyncEnumerator(CancellationToken cancellationToken = default) { while (true) { cancellationToken.ThrowIfCancellationRequested(); yield return await ReadAsync(cancellationToken); } } } // $ dotnet run // 0 1 2 3 4 5 6 7 8 9// Resource Pooling: Limit to 10 connections private static SemaphoreSlim _connectionSemaphore = new SemaphoreSlim(10); public async Task UseDatabaseConnectionAsync() { // Acquire a connection slot await _connectionSemaphore.WaitAsync(); try { // Use the database connection // ... } finally { // Release the connection slot _connectionSemaphore.Release(); } }// Throttling: Limit to 5 concurrent requests private static SemaphoreSlim _requestSemaphore = new SemaphoreSlim(5); public async Task SendRequestAsync() { // Wait for a request slot await _requestSemaphore.WaitAsync(); try { // Send the request // ... } finally { // Release the request slot _requestSemaphore.Release(); } }
1.7.3. Thread interaction, or signaling
Thread interaction (or thread signaling) means that a thread must wait for notification, or a signal, from one or more threads in order to proceed.
1.7.3.1. EventWaitHandle
The System.Threading.EventWaitHandle class represents a thread synchronization event.
A synchronization event can be either in an unsignaled or signaled state.
The behavior of an EventWaitHandle that has been signaled depends on its reset mode:
-
An
EventWaitHandlecreated with theEventResetMode.AutoResetflag resets automatically after releasing a single waiting thread.-
It’s like a turnstile that allows only one thread through each time it’s signaled.
-
The System.Threading.AutoResetEvent class, which derives from
EventWaitHandle, represents that behavior.
-
-
An
EventWaitHandlecreated with theEventResetMode.ManualResetflag remains signaled until itsResetmethod is called.-
It’s like a gate that is closed until signaled and then stays open until someone closes it.
-
The System.Threading.ManualResetEvent class, which derives from
EventWaitHandle, represents that behavior. -
The System.Threading.ManualResetEventSlim class is a lightweight alternative to
ManualResetEvent.
-
On Windows, EventWaitHandle can be used for the inter-process synchronization.
-
To do that, create an
EventWaitHandleinstance that represents a named system synchronization event by using one of theEventWaitHandleconstructors that specifies a name or theEventWaitHandle.OpenExistingmethod.
| Event wait handles are not .NET events. There are no delegates or event handlers involved. The word "event" is used to describe them because they have traditionally been referred to as operating-system events, and because the act of signaling the wait handle indicates to waiting threads that an event has occurred. |
-
Event Wait Handles That Reset Automatically [7]
An automatic reset event can be created by specifying
EventResetMode.AutoResetwhen creating theEventWaitHandleobject.-
As its name implies, this synchronization event resets automatically when signaled, after releasing a single waiting thread.
-
Signal the event by calling its
Setmethod. -
Automatic reset events are usually used to provide exclusive access to a resource for a single thread at a time.
-
A thread requests the resource by calling the
WaitOnemethod. -
If no other thread is holding the wait handle, the method returns true and the calling thread has control of the resource.
-
If an automatic reset event is signaled when no threads are waiting, it remains signaled until a thread attempts to wait on it.
-
The event releases the thread and immediately resets, blocking subsequent threads.
-
-
Event Wait Handles That Reset Manually [7]
A manual reset event can be created by specifying
EventResetMode.ManualResetwhen creating theEventWaitHandleobject.-
As its name implies, this synchronization event must be reset manually after it has been signaled. Until it is reset, by calling its
Resetmethod, threads that wait on the event handle proceed immediately without blocking. -
A manual reset event acts like the gate of a corral. When the event is not signaled, threads that wait on it block, like horses in a corral.
-
When the event is signaled, by calling its
Setmethod, all waiting threads are free to proceed. The event remains signaled until itsResetmethod is called. -
Like horses leaving a corral, it takes time for the released threads to be scheduled by the operating system and to resume execution.
-
If the
Resetmethod is called before all the threads have resumed execution, the remaining threads once again block. -
Which threads resume and which threads block depends on random factors like the load on the system, the number of threads waiting for the scheduler, and so on.
-
EventWaitHandle ewh = new EventWaitHandle(false, EventResetMode.ManualReset); ThreadPool.QueueUserWorkItem(_ => { ewh.WaitOne(); Console.WriteLine("FooSingled"); }); ThreadPool.QueueUserWorkItem(_ => { ewh.WaitOne(); Console.WriteLine("BarSingled"); }); ewh.Set(); Thread.Sleep(1000); // $ dotnet run // BarSingled // FooSingled -
1.7.3.2. CountdownEvent
The System.Threading.CountdownEvent class represents an event that becomes set when its count is zero.
-
While
CountdownEvent.CurrentCountis greater than zero, a thread that callsCountdownEvent.Waitis blocked. -
Call
CountdownEvent.Signalto decrement an event’s count.ConcurrentQueue<int> numbers = new(Enumerable.Range(1, 100)); CountdownEvent cde = new(numbers.Count); int sum = 0; for (int i = 0; i < Environment.ProcessorCount; i++) { ThreadPool.QueueUserWorkItem(_ => { while (numbers.TryDequeue(out int number)) { Interlocked.Add(ref sum, number); cde.Signal(); } }); } cde.Wait(); Console.Write(sum); // 5050 -
In contrast to
ManualResetEventorManualResetEventSlim, which can be used to unblock multiple threads with a signal from one thread,CountdownEventcan be used to unblock one or more threads with signals from multiple threads.
1.7.3.3. Barrier
The System.Threading.Barrier class represents a thread execution barrier.
-
A thread that calls the
Barrier.SignalAndWaitmethod signals that it reached the barrier and waits until other participant threads reach the barrier. -
When all participant threads reach the barrier, they proceed and the barrier is reset and can be used again.
-
It might be used when one or more threads require the results of other threads before proceeding to the next computation phase.
ConcurrentQueue<int> numbers = new(Enumerable.Range(1, 100)); using Barrier barrier = new(3); // 3 worker threads int sum = 0; for (int i = 0; i < barrier.ParticipantCount; i++) { ThreadPool.QueueUserWorkItem(_ => { while (numbers.TryDequeue(out int number)) { Interlocked.Add(ref sum, number); } barrier.SignalAndWait(); // Worker threads signal the barrier }); } barrier.AddParticipant(); // main thread barrier.SignalAndWait(); Console.Write(sum); // 5050
1.7.4. Interlocked
The System.Threading.Interlocked class provides static methods that perform simple atomic operations on a variable.
// bad code: only for demo
int sum = 0;
Parallel.For(1, 101, i =>
{
int local;
do
{
local = sum;
} while (Interlocked.CompareExchange(ref sum, local + i, local) != local);
});
Console.Write(sum); // 50501.8. The volatile keyword
The volatile keyword indicates that a field might be modified by multiple threads that are executing at the same time. [9]
-
The compiler, the runtime system, and even hardware may rearrange reads and writes to memory locations for performance reasons.
-
Fields that are declared
volatileare excluded from certain kinds of optimizations. -
There is no guarantee of a single total ordering of volatile writes as seen from all threads of execution.
-
On a multiprocessor system:
-
a volatile read operation does not guarantee to obtain the latest value written to that memory location by any processor.
-
a volatile write operation does not guarantee that the value written would be immediately visible to other processors.
-
-
The
volatilekeyword can only be applied to fields of a class or struct of these types (local variables cannot be declared volatile):-
Reference types.
-
Pointer types (in an unsafe context). Note that although the pointer itself can be volatile, the object that it points to cannot. In other words, it cannot declare a "pointer to volatile."
-
Simple types such as
sbyte,byte,short,ushort,int,uint,char,float, andbool. -
An
enumtype with one of the following base types:byte,sbyte,short,ushort,int, oruint. -
Generic type parameters known to be reference types.
-
IntPtrandUIntPtr. -
Other types, including
doubleandlong, cannot be marked volatile because reads and writes to fields of those types cannot be guaranteed to be atomic; for atomic operations, useInterlockedorlockstatement.
-
|
The It is typically used as a flag or indicator to let threads poll for changes and make decisions based on the value. It’s a simple, lightweight way to signal between threads, e.g., to indicate whether a task should stop or proceed. |
1.9. ThreadLocal<T>
-
ThreadLocal<T>is a class in C# that provides thread-local storage, meaning each thread gets its own independent instance of a value. It’s especially useful in scenarios where data should be private to each thread, preventing shared access and avoiding synchronization mechanisms like locks orInterlockedfor those specific data.ThreadLocal<int> sum = new(); ThreadPool.QueueUserWorkItem(_ => { sum.Value = Enumerable.Range(1, 100).Sum(); Console.WriteLine($"{"100:",5} {sum.Value}"); }); ThreadPool.QueueUserWorkItem(_ => { sum.Value = Enumerable.Range(1, 1_000).Sum(); Console.WriteLine($"{"1000:",5} {sum.Value}"); }); Console.WriteLine($"{"0:",5} {sum.Value}"); Console.ReadLine(); // 0: 0 // 1000: 500500 // 100: 5050-
A
staticfield marked withThreadStaticAttributeis not shared between threads.-
Each executing thread has a separate instance of the field, and independently sets and gets values for that field.
-
If the field is accessed on a different thread, it will contain a different value.
-
Do not specify initial values for fields marked with
ThreadStaticAttribute, because such initialization occurs only once, when the class constructor executes, and therefore affects only one thread.ThreadPool.QueueUserWorkItem(_ => { Accumulator.A100(); }); ThreadPool.QueueUserWorkItem(_ => { Accumulator.A1000(); }); Console.ReadLine(); // 1000: 500500 // 100: 5050 sealed class Accumulator { [ThreadStatic] private static int sum; public static void A100() { sum = Enumerable.Range(1, 100).Sum(); Console.WriteLine($"{"100:",5} {sum}"); } public static void A1000() { sum = Enumerable.Range(1, 1_000).Sum(); Console.WriteLine($"{"1000:",5} {sum}"); } }
-
-
1.10. Lazy<T>
-
Use
Lazy<T>to lazy initialization to defer the creation of a large or resource-intensive object, or the execution of a resource-intensive task, particularly when such creation or execution might not occur during the lifetime of the program.-
If the lazily initialized object will be accessed by multiple threads, use
Lazy<T>()orLazy<T>(Func<T>)to ensure thread-safety. -
The default behavior is thread-safe, and only one instance (i.e., a singleton) of the object will be created even if multiple threads try to access it.
-
In the default mode (
ExecutionAndPublication), only one instance is created in the first thread and shared across threads. -
In
PublicationOnlymode, multiple threads may create temporary instances during initialization, but only one instance will be retained and used.
-
-
If thread safety is not required, use
Lazy<T>(Boolean)withisThreadSafeset tofalse. -
If the lazily initialized object does not require additional initialization, use the parameterless constructor
Lazy<T>(), otherwise useLazy<T>(Func<T>)to provide a factory method for initialization.sealed class LargeObject { private static readonly Lazy<LargeObject> s_lazy = new(() => { Thread.Sleep(1000); // lazy return new LargeObject(); }); // singleton public static LargeObject Instance { get; } = s_lazy.Value; public override string ToString() { return "I'm lazy"; } }
-
1.11. Thread-safe collections
The System.Collections.Concurrent namespace includes several collection classes that are both thread-safe and scalable.
-
Multiple threads can safely and efficiently add or remove items from these collections, without requiring additional synchronization in user code.
-
When writing new code, use the concurrent collection classes to write multiple threads to the collection concurrently.
-
If only reading from a shared collection, then use the classes in the System.Collections.Generic namespace.
Some of the concurrent collection types use lightweight synchronization mechanisms such as SpinLock, SpinWait, SemaphoreSlim, and CountdownEvent.
-
These synchronization types typically use busy spinning for brief periods before they put the thread into a true
Waitstate. -
When wait times are expected to be short, spinning is far less computationally expensive than waiting, which involves an expensive kernel transition.
-
For collection classes that use spinning, this efficiency means that multiple threads can add and remove items at a high rate.
The ConcurrentQueue<T> and ConcurrentStack<T> classes don’t use locks at all. Instead, they rely on Interlocked operations to achieve thread safety.
The following table lists the collection types in the System.Collections.Concurrent namespace:
| Type | Description |
|---|---|
Provides bounding and blocking functionality for any type that implements |
|
Thread-safe implementation of a dictionary of key-value pairs. |
|
Thread-safe implementation of a FIFO (first-in, first-out) queue. |
|
Thread-safe implementation of a LIFO (last-in, first-out) stack. |
|
Thread-safe implementation of an unordered collection of elements. |
|
The interface that a type must implement to be used in a |
|
What’s the diff of BlockingCollection<T> and Channel<T> ?
*
Benefits of
Benefits of
In general, However, if you have a legacy application where you cannot use async and await extensively, or where you are using ThreadPool and Tasks heavily, then |
2. Asynchronous programming
The core of async programming is the Task and Task<T> objects, which model asynchronous operations. They are supported by the async and await keywords. The model is fairly simple in most cases: [30]
-
For I/O-bound code,
awaitan operation that returns aTaskorTask<T>inside of anasyncmethod.-
If the code is waiting for something (e.g., data from a database), it is I/O-bound.
-
Use
asyncandawaitwithoutTask.Runor the Task Parallel Library.
-
-
For CPU-bound code,
awaitan operation that is started on a background thread with theTask.Runmethod.-
If the code is performing heavy computation, it is CPU-bound.
-
Use
asyncandawait, but offload the work to another thread usingTask.Runfor responsiveness. -
If the task is suitable for parallelism, consider the Task Parallel Library.
-
-
The
awaitkeyword is where the magic happens that yields control to the caller of the method that performedawait, and it ultimately allows a UI to be responsive or a service to be elastic.
.NET provides three patterns for performing asynchronous operations: [10]
-
Task-based Asynchronous Pattern (TAP), which uses a single method to represent the initiation and completion of an asynchronous operation.
-
TAP was introduced in .NET Framework 4.
-
It’s the recommended approach to asynchronous programming in .NET.
-
The
asyncandawaitkeywords in C# and theAsyncandAwaitoperators in Visual Basic add language support for TAP.string hostname = "asp.net"; IPAddress[] addrs = await Dns.GetHostAddressesAsync(hostname); // Avoids blocking the current thread while waiting for the operation to complete Console.WriteLine(addrs[0]); // 40.118.185.161
-
-
Event-based Asynchronous Pattern (EAP), which is the event-based legacy model for providing asynchronous behavior.-
It requires a method that has the
Asyncsuffix and one or more events, event handler delegate types, and EventArg-derived types. -
EAP was introduced in .NET Framework 2.0.
-
It’s no longer recommended for new development.
WebClient http = new(); http.DownloadStringCompleted += (_, e) => { if (e.Error is not null) { Console.WriteLine(e.Error.Message); } Console.WriteLine(e.Result.Length); // vary, e.g., 247965 }; http.DownloadStringAsync(new Uri("https://asp.net")); // Avoids blocking the current thread while waiting for the operation to complete Console.ReadKey(); // Wait for the HTTP operation to complete
-
-
Asynchronous Programming Model (APM)pattern (also called the IAsyncResult pattern), which is the legacy model that uses theIAsyncResultinterface to provide asynchronous behavior.-
In this pattern, asynchronous operations require
BeginandEndmethods (for example,BeginWriteandEndWriteto implement an asynchronous write operation). -
This pattern is no longer recommended for new development.
string hostname = "asp.net"; IAsyncResult ar = Dns.BeginGetHostAddresses(hostname, null, null); // Avoids blocking the current thread while waiting for the operation to complete IPAddress[] addrs = Dns.EndGetHostAddresses(ar); Console.WriteLine(addrs[0]); // 40.118.185.161
-
2.1. Tasks and ValueTasks
In .NET Framework 4.0, Task type was introduced the System.Threading.Tasks. [17]
-
At its heart, a
Taskis just a data structure that represents the eventual completion of some asynchronous operation (other frameworks call a similar type a “promise” or a “future”). -
A
Taskis created to represent some operation, and then when the operation it logically represents completes, the results are stored into thatTask. -
Unlike
IAsyncResult,Tasksupports built-in continuations, enabling asynchronous callbacks to execute reliably whether the task is completed, not yet completed, or completing concurrently with the notification request.class MyTask { private bool _completed; private Exception? _exception; private Action<MyTask>? _continuation; private ExecutionContext? _context; public struct Awaiter(MyTask t) : INotifyCompletion { public Awaiter GetAwaiter() => this; public bool IsCompleted => t.IsCompleted; public void OnCompleted(Action continuation) => t.ContinueWith(continuation); public void GetResult() => t.Wait(); } public Awaiter GetAwaiter() => new Awaiter(this); ... } -
ValueTask<TResult>was introduced in .NET Core 2.0 as a struct capable of wrapping either aTResultor aTask<TResult>. -
Only if performance analysis proves it worthwhile should a
ValueTaskbe used instead of aTask. [28]public readonly struct ValueTask<TResult> { private readonly Task<TResult>? _task; private readonly TResult _result; ... } -
The default task scheduler provides work-stealing for load-balancing, thread injection/retirement for maximum throughput, and overall good performance, which should be sufficient for most scenarios.
-
In .NET Framework 4.5,
Task.Runwas introduced as a simpler alternative toTask.Factory.StartNewfor common scenarios of offloading work to the thread pool. [29]Task.Run(someAction); // equivalent to: Task.Factory.StartNew(someAction, CancellationToken.None, TaskCreationOptions.DenyChildAttach, TaskScheduler.Default);
2.2. ExecutionContext and SynchronizationContext
-
ExecutionContextis a state bag that holds ambient information about the current execution environment or context to capture all of this state from one thread and then restore it onto another thread while the logical flow of control continues. [27]// ambient state captured into ec ExecutionContext ec = ExecutionContext.Capture(); // restored during the invocation of a delegate ExecutionContext.Run(ec, delegate { // code here will see ec’s state as ambient }, null); -
SynchronizationContextwas also introduced in .NET Framework 2.0, as an abstraction for a general scheduler.i [17]-
In particular, SynchronizationContext‘s most used method is
Post, which queues a work item to whatever scheduler is represented by that context. -
The base implementation of
SynchronizationContext, for example, just represents theThreadPool, and so the base implementation ofSynchronizationContext.Postsimply delegates toThreadPool.QueueUserWorkItem, which is used to ask theThreadPoolto invoke the supplied callback with the associated state on one the pool’s threads. -
However, SynchronizationContext‘s bread-and-butter isn’t just about supporting arbitrary schedulers, rather it’s about supporting scheduling in a manner that works according to the needs of various application models.
-
WinForms provides the
WindowsFormSynchronizationContexttype which overridesPostto callControl.BeginInvoke.public sealed class WindowsFormsSynchronizationContext : SynchronizationContext, IDisposable { public override void Post(SendOrPostCallback d, object? state) => _controlToSendTo?.BeginInvoke(d, new object?[] { state }); ... } -
WPF provides the
DispatcherSynchronizationContexttype which overridesPostto callDispatcher.BeginInvoke.public sealed class DispatcherSynchronizationContext : SynchronizationContext { public override void Post(SendOrPostCallback d, Object state) => _dispatcher.BeginInvoke(_priority, d, state); ... }
-
-
2.3. AsyncLocal<T>
The AsyncLocal<T> class represents ambient data that is local to a given asynchronous control flow, such as an asynchronous method.
-
Because the task-based asynchronous programming model tends to abstract the use of threads, the
AsyncLocal<T>designed to flow with the asynchronous logical operation to persist data across threads. -
A continuation task created with
ContinueWithis considered a separate and independent task, even if it’s attached to the original task, which is not part of the same logical asynchronous operation thatAsyncLocaltracks.ThreadLocal<string> _threadLocal = new(); // for per-thread data AsyncLocal<string> _asyncLocal = new(); // for per-async-flow data await Task.Run(async () => { _threadLocal.Value = "Thread Local Value 1"; _asyncLocal.Value = "Async Local Value 1"; PrintValues(1); await Task.Delay(100); PrintValues(2); await Task.Run(() => PrintValues(3)); }).ContinueWith(_ => PrintValues(4)); PrintValues(5); void PrintValues(int point) { Console.WriteLine( $"[{point}] " + $"[Task: {Task.CurrentId,1}] " + $"[Thread: {Environment.CurrentManagedThreadId,1}] " + $"[ThreadLocal: {_threadLocal.Value}] " + $"[AsyncLocal: {_asyncLocal.Value}]"); }$ dotnet run [1] [Task: 1] [Thread: 4] [ThreadLocal: Thread Local Value 1] [AsyncLocal: Async Local Value 1] [2] [Task: ] [Thread: 4] [ThreadLocal: Thread Local Value 1] [AsyncLocal: Async Local Value 1] [3] [Task: 2] [Thread: 6] [ThreadLocal: ] [AsyncLocal: Async Local Value 1] [4] [Task: 3] [Thread: 6] [ThreadLocal: ] [AsyncLocal: ] [5] [Task: ] [Thread: 6] [ThreadLocal: ] [AsyncLocal: ] $ dotnet run [1] [Task: 1] [Thread: 4] [ThreadLocal: Thread Local Value 1] [AsyncLocal: Async Local Value 1] [2] [Task: ] [Thread: 4] [ThreadLocal: Thread Local Value 1] [AsyncLocal: Async Local Value 1] [3] [Task: 2] [Thread: 4] [ThreadLocal: Thread Local Value 1] [AsyncLocal: Async Local Value 1] [4] [Task: 3] [Thread: 4] [ThreadLocal: Thread Local Value 1] [AsyncLocal: ] [5] [Task: ] [Thread: 4] [ThreadLocal: Thread Local Value 1] [AsyncLocal: ]
2.4. WPF threading model
Typically, WPF applications start with two threads: one for handling rendering and another for managing the UI. [11]
-
The rendering thread effectively runs hidden in the background while the UI thread receives input, handles events, paints the screen, and runs application code.
-
Most applications use a single UI thread, although in some situations it is best to use several.
The UI thread queues work items inside an object called a Dispatcher.
-
The Dispatcher selects work items on a priority basis and runs each one to completion.
-
Every UI thread must have at least one Dispatcher, and each Dispatcher can execute work items in exactly one thread.
-
The trick to building responsive, user-friendly applications is to maximize the Dispatcher throughput by keeping the work items small.
-
A background thread can ask the UI thread to perform an operation on its behalf by registering a work item with the Dispatcher of the UI thread.
-
The Dispatcher class provides the methods for registering work items:
Dispatcher.InvokeAsync,Dispatcher.BeginInvoke, andDispatcher.Invoketo schedule a delegate for execution.-
Invokeis a synchronous call – that is, it doesn’t return until the UI thread actually finishes executing the delegate. -
InvokeAsyncandBeginInvokeare asynchronous and return immediately.
-
2.5. The async and await keywords
Asynchronous programming can help avoid performance bottlenecks and enhance the overall responsiveness of an application. However, traditional techniques for writing asynchronous applications can be complicated, making them difficult to write, debug, and maintain.
C# supports simplified approach, async programming, that leverages asynchronous support in the .NET runtime to let the compiler does the difficult work that the developer used to do, and the application retains a logical structure that resembles synchronous code. [16]

Asynchrony is essential for activities that are potentially blocking, such as web access.
-
Access to a web resource sometimes is slow or delayed.
-
If such an activity is blocked in a synchronous process, the entire application must wait.
-
In an asynchronous process, the application can continue with other work that doesn’t depend on the web resource until the potentially blocking task finishes.
Asynchrony proves especially valuable for applications that access the UI thread because all UI-related activity usually shares one thread.
-
If any process is blocked in a synchronous application, all are blocked, and the application stops responding, and the user might conclude that it has failed when instead it’s just waiting.
-
When using asynchronous methods, the application continues to respond to the UI, and allow the user to resize or minimize a window, for example, or close the application if there’s no desire to wait for it to finish.
Async methods are intended to be non-blocking operations.
-
An await expression in an async method doesn’t block the current thread while the awaited task is running.
-
Instead, the expression signs up the rest of the method as a continuation and returns control to the caller of the async method.
The async and await keywords don’t cause additional threads to be created.
-
Async methods don’t require multithreading because an async method doesn’t run on its own thread. The method runs on the current synchronization context and uses time on the thread only when the method is active.
-
Use
Task.Runto move CPU-bound work to a background thread, but a background thread doesn’t speed up the process of waiting because the process itself is inherently waiting for some external result, not doing any computation.
If the async modifier is used to specify that a method is an async method, it enables the following two capabilities.
-
The marked async method can use
awaitto designate suspension points.-
The
awaitoperator tells the compiler that the async method can’t continue past that point until the awaited asynchronous process is complete. -
In the meantime, control returns to the caller of the async method.
-
The suspension of an async method at an await expression doesn’t constitute an exit from the method, and finally blocks don’t run.
-
-
The marked async method can itself be awaited by methods that call it.
-
An async method typically contains one or more occurrences of an await operator, but the absence of await expressions doesn’t cause a compiler error.
-
If an async method doesn’t use an
awaitoperator to mark a suspension point, the method executes as a synchronous method does, despite theasyncmodifier. -
The compiler issues a warning for such methods.
-
-
An async method can also have a
voidreturn type that is used primarily to define event handlers, where avoidreturn type is required. [16]-
Async event handlers often serve as the starting point for async programs.
-
An async method that has a
voidreturn type can’t be awaited, and the caller of a void-returning method can’t catch any exceptions that the method throws -
An async method can’t declare
in,reforoutparameters, but the method can call methods that have such parameters. -
Similarly, an async method can’t return a value by reference, although it can call methods with
refreturn values.
-
-
An async method might return an async stream, represented by
IAsyncEnumerable<T>that provides a way to enumerate items read from a stream when elements are generated in chunks with repeated asynchronous calls.await foreach (string word in ReadWordsFromStreamAsync()) { Console.WriteLine(word); } static async IAsyncEnumerable<string> ReadWordsFromStreamAsync() { string data = @"This is a line of text. Here is the second line of text. And there is one more for good measure. Wait, that was the penultimate line."; using var readStream = new StringReader(data); string? line = await readStream.ReadLineAsync(); while (line != null) { foreach (string word in line.Split(' ', StringSplitOptions.RemoveEmptyEntries)) { yield return word; } line = await readStream.ReadLineAsync(); } }
2.6. Task.ConfigureAwait
Don’t Need ConfigureAwait(false), But Still Use It in Libraries. [22]
|
When an asynchronous method awaits a Task directly, continuation usually occurs in the same thread that created the task, depending on the async context.
-
SynchronizationContextmakes it possible to call reusable helpers and automatically be scheduled back whenever and to wherever the calling environment deems fit. -
As a result, it’s natural to expect that to "just work" with async/await, and it does.
button1.Text = await Task.Run(() => ComputeMessage());-
That invocation of
ComputeMessageis offloaded to the thread pool, and upon the method’s completion, execution transitions back to the UI thread associated with the button, and the setting of itsTextproperty happens on that thread.
-
-
That integration with
SynchronizationContextis left up to the awaiter implementation to be responsible for actually invoking or queueing the supplied continuation when the represented asynchronous operation completes. [18]
The ConfigureAwait method is simply a method that returns a struct (a ConfiguredTaskAwaitable) that wraps the original task it was called on as well as the specified Boolean value.
-
ConfigureAwait(continueOnCapturedContext: false)is used to avoid forcing the callback to be invoked on the original context or scheduler to improve performance by avoiding unnecessary context switches.object scheduler = null; if (continueOnCapturedContext) { scheduler = SynchronizationContext.Current; if (scheduler is null && TaskScheduler.Current != TaskScheduler.Default) { scheduler = TaskScheduler.Current; } } -
Use
ConfigureAwait(false)when the continuation does not need to be run on the original context, such as in background worker threads or library code where context is not important. -
Using
ConfigureAwait(false)can help avoid deadlocks in certain scenarios, especially in UI-based applications where the main thread is waiting for an async task to complete while the continuation is trying to marshal back to the same thread. -
It is recommended to use
ConfigureAwait(false)in library code or when performing I/O-bound work unless the continuation explicitly requires a UI or thread-specific context.
2.7. System.Threading.Channels
The System.Threading.Channels namespace provides a set of synchronization data structures for passing data between producers and consumers asynchronously via a FIFO queue.
public sealed class MySimpleChannel<T>
{
private readonly ConcurrentQueue<T> _queue = new ConcurrentQueue<T>();
private readonly SemaphoreSlim _semaphore = new SemaphoreSlim(0);
public void Write(T value)
{
_queue.Enqueue(value); // store the data
_semaphore.Release(); // notify any consumers that more data is available
}
public async ValueTask<T> ReadAsync(CancellationToken cancellationToken = default)
{
await _semaphore.WaitAsync(cancellationToken).ConfigureAwait(false); // wait
bool gotOne = _queue.TryDequeue(out T item); // retrieve the data
Debug.Assert(gotOne);
return item;
}
}A channel is simply a data structure that’s used to store produced data for a consumer to retrieve, and an appropriate synchronization to enable that to happen safely, while also enabling appropriate notifications in both directions. [8]
-
To create a channel that specifies a maximum capacity, call
Channel.CreateBounded.var channel = Channel.CreateBounded<T>(7); -
To create a channel that is used by any number of readers and writers concurrently, call
Channel.CreateUnbounded.var channel = Channel.CreateUnbounded<T>(); -
Each bounding strategy exposes various creator-defined options, either
BoundedChannelOptionsorUnboundedChannelOptionsrespectively.
3. Parallel programming in .NET
Many personal computers and workstations have multiple CPU cores that enable multiple threads to be executed simultaneously. To take advantage of the hardware, parallelizing code can distribute work across multiple processors. [13]
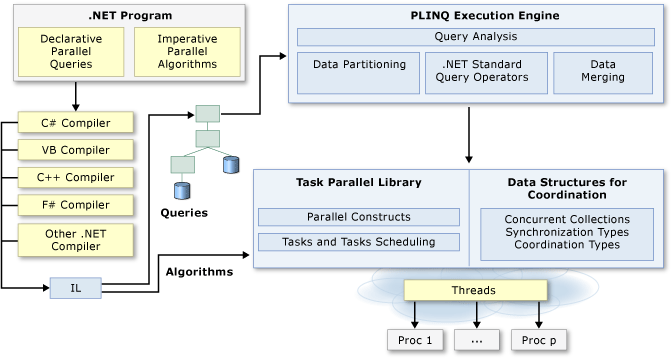
The following illustration provides a high-level overview of the parallel programming architecture in .NET.
3.1. Task Parallel Library (TPL)
The Task Parallel Library (TPL) is a set of public types and APIs in the System.Threading and System.Threading.Tasks namespaces.
-
The purpose of the TPL is to make developers more productive by simplifying the process of adding parallelism and concurrency to applications.
-
The TPL dynamically scales the degree of concurrency to use all the available processors most efficiently.
-
In addition, the TPL handles the partitioning of the work, the scheduling of threads on the ThreadPool, cancellation support, state management, and other low-level details.
In .NET Framework 4, the TPL is the preferred way to write multithreaded and parallel code, but not all code is suitable for parallelization.
-
For example, if a loop performs only a small amount of work on each iteration, or it doesn’t run for many iterations, then the overhead of parallelization can cause the code to run more slowly.
-
Parallelization adds complexity to program execution, so a basic understanding of threading concepts like locks, deadlocks, and race conditions is recommended to use the TPL effectively.
3.2. Data Parallelism
Data parallelism refers to scenarios in which the same operation is performed concurrently (that is, in parallel) on elements in a source collection or array. [14]
-
In data parallel operations, the source collection is partitioned so that multiple threads can operate on different segments concurrently.
-
The Task Parallel Library (TPL) supports data parallelism through the System.Threading.Tasks.Parallel class that provides method-based parallel implementations of
forandforeachloops. -
Both
ForEach/ForandForEachAsync/ForAsyncuse the thread pool to distribute work across multiple threads for parallelism, but async versions are optimized for I/O-bound operations by allowing threads to be released during I/O waits.// Executes a for loop in which iterations may run in parallel. Parallel.For(0, 100, i => { }); await Parallel.ForAsync(0, 100, (i, token) => { return ValueTask.CompletedTask; }); // Executes a foreach operation in which iterations may run in parallel. Parallel.ForEach(Enumerable.Range(0, 100), num => { }); await Parallel.ForEachAsync(Enumerable.Range(0, 100), (num, token) => { return ValueTask.CompletedTask; }); // Executes each of the provided actions, possibly in parallel. Parallel.Invoke(() => { }, delegate { });string path = Path.Combine( Environment.GetFolderPath(Environment.SpecialFolder.UserProfile), ".nuget/packages/"); string[] fileNames = Directory.GetFiles(path, "*", SearchOption.AllDirectories); Stopwatch sw = Stopwatch.StartNew(); for (int i = 0; i < 2; i++) { sw.Restart(); long parallelTotalSize = 0; Parallel.ForEach(fileNames, fileName => Interlocked.Add(ref parallelTotalSize, new FileInfo(fileName).Length)); Console.WriteLine($"Parallel: {parallelTotalSize}, {sw.ElapsedMilliseconds}ms"); sw.Restart(); long totalSize = 0; foreach (string fileName in fileNames) totalSize += new FileInfo(fileName).Length; Console.WriteLine($"Sequential : {totalSize}, {sw.ElapsedMilliseconds}ms"); } // $ dotnet run // Parallel: 2743226084, 400ms // Sequential : 2743226084, 598ms // Parallel: 2743226084, 220ms // Sequential : 2743226084, 429ms -
When a parallel loop runs, the TPL partitions the data source so that the loop can operate on multiple parts concurrently.
-
Behind the scenes, the Task Scheduler partitions the task based on system resources and workload.
-
When possible, the scheduler redistributes work among multiple threads and processors if the workload becomes unbalanced.
-
-
Data parallelism with declarative, or query-like, syntax is supported by PLINQ.
|
False sharing occurs when multiple threads modify variables that reside on the same CPU cache line, leading to performance degradation due to unnecessary cache invalidations.
|
3.3. Dataflow
The Task Parallel Library (TPL) offers the TPL Dataflow Library, which enhances concurrency in applications by supporting actor-based programming and in-process message passing for coarse-grained dataflow and pipelining tasks. [21]
-
The TPL Dataflow Library provides a foundation for message passing and parallelizing CPU-intensive and I/O-intensive applications that have high throughput and low latency.
-
The TPL Dataflow Library consists of dataflow blocks, source blocks, target blocks, and propagator blocks, which are data structures that buffer and process data.
-
A source block acts as a source of data and can be read from.
-
A target block acts as a receiver of data and can be written to.
-
A propagator block acts as both a source block and a target block, and can be read from and written to.
-
-
Dataflow blocks can be connected to form pipelines, which are linear sequences of dataflow blocks, or networks, which are graphs of dataflow blocks.
-
In a pipeline or network, sources asynchronously propagate data to targets as that data becomes available.
-
The
ISourceBlock<TOutput>.LinkTomethod links a source dataflow block to a target block. -
A source can be linked to zero or more targets; targets can be linked from zero or more sources.
-
-
The dataflow programming model is related to the concept of message passing, where independent components of a program communicate with one another by sending messages.
-
One way to propagate messages among application components is to call the
-
Post(synchronous) andSendAsync(asynchronous) methods to send messages to target dataflow blocks, and the -
Receive,ReceiveAsync, andTryReceivemethods to receive messages from source blocks.
-
-
3.4. Parallel LINQ (PLINQ)
Language-Integrated Query (LINQ) is the name for a set of technologies based on the integration of query capabilities directly into the C# language. [19]
-
With LINQ, a query is a first-class language construct, just like classes, methods, and events.
-
A query expression, the most visible "language-integrated" part of LINQ, is written in a declarative query syntax that performs filtering, ordering, and grouping operations on data sources with a minimum of code.
static IEnumerable<TResult> SelectCompiler<TSource, TResult>(IEnumerable<TSource> source, Func<TSource, TResult> selector)
{
ArgumentNullException.ThrowIfNull(source);
ArgumentNullException.ThrowIfNull(selector);
return Impl(source, selector);
static IEnumerable<TResult> Impl(IEnumerable<TSource> source, Func<TSource, TResult> selector)
{
foreach (var item in source)
{
yield return selector(item);
}
}
}
static IEnumerable<TResult> SelectManual<TSource, TResult>(IEnumerable<TSource> source, Func<TSource, TResult> selector)
{
ArgumentNullException.ThrowIfNull(source);
ArgumentNullException.ThrowIfNull(selector);
return new SelectManualEnumerable<TSource, TResult>(source, selector);
}
sealed class SelectManualEnumerable<TSource, TResult> : IEnumerable<TResult>, IEnumerator<TResult>
{
private readonly IEnumerable<TSource> _source;
private readonly Func<TSource, TResult> _selector;
private readonly int _threadId = Environment.CurrentManagedThreadId;
private IEnumerator<TSource>? _enumerator;
private TResult _current = default!;
private int _state = 0;
public SelectManualEnumerable(IEnumerable<TSource> source, Func<TSource, TResult> selector)
{
_source = source;
_selector = selector;
}
public IEnumerator<TResult> GetEnumerator()
{
if (_threadId == Environment.CurrentManagedThreadId && _state == 0)
{
_state = 1;
return this;
}
return new SelectManualEnumerable<TSource, TResult>(_source, _selector) { _state = 1 };
}
IEnumerator IEnumerable.GetEnumerator() => GetEnumerator();
public TResult Current => _current;
object? IEnumerator.Current => Current;
public void Dispose()
{
_state = -1;
_current = default!;
_enumerator?.Dispose();
}
public bool MoveNext()
{
switch (_state)
{
case 1:
_enumerator = _source.GetEnumerator();
_state = 2;
goto case 2;
case 2:
Debug.Assert(_enumerator is not null);
try
{
if (_enumerator.MoveNext())
{
_current = _selector(_enumerator.Current);
return true;
}
}
catch
{
Dispose();
throw;
}
Dispose();
return false;
}
Dispose();
return false;
}
public void Reset()
{
throw new NotSupportedException();
}
}At compile time, query expressions are converted to standard query operator method calls according to the rules defined in the C# specification.
-
Any query that can be expressed by using query syntax can also be expressed by using method syntax.
-
In some cases, query syntax is more readable and concise. In others, method syntax is more readable.
-
There’s no semantic or performance difference between the two different forms.
string sentence = "the quick brown fox jumps over the lazy dog"; // Split the string into individual words to create a collection. string[] words = sentence.Split(' '); // Using query expression syntax. var query = from word in words group word.ToUpper() by word.Length into gr orderby gr.Key select new { Length = gr.Key, Words = gr }; // Using method-based query syntax. var query2 = words. GroupBy(w => w.Length, w => w.ToUpper()). Select(g => new { Length = g.Key, Words = g }). OrderBy(o => o.Length); foreach (var obj in query) { Console.WriteLine("Words of length {0}:", obj.Length); foreach (string word in obj.Words) Console.WriteLine(word); }
To enable LINQ querying of a data source, there are different approaches based on whether the data is in-memory or remote:
-
In-memory data
-
If the data implements
IEnumerable<T>, LINQ to Objects can be used to query it directly. -
If
IEnumerable<T>is not implemented, define LINQ standard query operator methods in the type or as extension methods. -
To implement deferred execution, return an
IEnumerable<T>orIQueryable<T>that yields elements instead of returning a concrete collection (List<T>,Array, etc.).public static IEnumerable<T> MyWhere<T>(this IEnumerable<T> source, Func<T, bool> predicate) { foreach (var item in source) { if (predicate(item)) { yield return item; // Deferred execution happens here } } }
-
-
Remote data
-
The best option for enabling LINQ querying of a remote data source is to implement the
IQueryable<T>interface.using var db = new AppDbContext(); // Microsoft.EntityFrameworkCore.DbContext // IQueryable<T> -> Translates into SQL and executes in the database var expensiveProducts = db.Products.Where(p => p.Price > 100); Console.WriteLine("SQL Query is not executed yet!"); foreach (var product in expensiveProducts) // Execution happens here { Console.WriteLine($"{product.Name}: ${product.Price}"); }
-
Parallel LINQ (PLINQ) is a parallel implementation of the Language-Integrated Query (LINQ) pattern. [20]
-
PLINQ implements the full set of LINQ standard query operators as extension methods for the System.Linq namespace and has additional operators for parallel operations.
-
PLINQ combines the simplicity and readability of LINQ syntax with the power of parallel programming.
A PLINQ query in many ways resembles a non-parallel LINQ to Objects query.
-
PLINQ queries, just like sequential LINQ queries, operate on any in-memory
IEnumerableorIEnumerable<T>data source, and have deferred execution, which means they do not begin executing until the query is enumerated. -
The primary difference is that PLINQ attempts to make full use of all the processors on the system by partitioning the data source into segments, and then executing the query on each segment on separate worker threads in parallel on multiple processors.
The System.Linq.ParallelEnumerable class exposes almost all of PLINQ’s functionality that includes implementations of all the standard query operators that LINQ to Objects supports, although it does not attempt to parallelize each one, and also contains a set of methods that enable behaviors specific to parallel execution.
var files = Directory.EnumerateFiles("/usr/share/man", "*.gz", SearchOption.AllDirectories);
Stopwatch sw = Stopwatch.StartNew();
for (int i = 0; i < 2; i++)
{
sw.Restart();
var parallelTopLetter = files
.AsParallel() // opt in to PLINQ
// .WithExecutionMode(ParallelExecutionMode.ForceParallelism)
// .WithDegreeOfParallelism(Environment.ProcessorCount)
// .WithCancellation(CancellationToken.None)
// .WithMergeOptions(ParallelMergeOptions.Default)
// .AsUnordered()
.Select(SplitLetters)
.SelectMany(w => w)
.GroupBy(char.ToLower)
.OrderByDescending(g => g.Count())
.First();
Console.WriteLine($"Parallel: {parallelTopLetter.Key}: {parallelTopLetter.Count()}, {sw.ElapsedMilliseconds}ms");
sw.Restart();
var sequentialTopLetter = files // .AsParallel().AsSequential()
.Select(SplitLetters)
.SelectMany(w => w)
.GroupBy(char.ToLower)
.OrderByDescending(g => g.Count())
.First();
Console.WriteLine($"Sequential: {sequentialTopLetter.Key}: {sequentialTopLetter.Count()}, {sw.ElapsedMilliseconds}ms");
}
static IEnumerable<char> SplitLetters(string fileName)
{
using var fileStream = new FileStream(fileName, FileMode.Open, FileAccess.Read);
using var gzipStream = new GZipStream(fileStream, CompressionMode.Decompress);
using var reader = new StreamReader(gzipStream);
string? line;
while ((line = reader.ReadLine()) != null)
{
foreach (char c in line.ToCharArray())
{
if (char.IsLetter(c))
yield return c; // deferred execution
}
}
}
// $ dotnet run
// Parallel: e: 29241, 132ms
// Sequential: e: 29241, 50ms
// Parallel: e: 29241, 32ms
// Sequential: e: 29241, 34msParallelEnumerable Operator |
Description |
The entry point for PLINQ. Specifies that the rest of the query should be parallelized, if it is possible. |
|
Specifies that the rest of the query should be run sequentially, as a non-parallel LINQ query. |
|
Specifies that PLINQ should preserve the ordering of the source sequence for the rest of the query, or until the ordering is changed, for example by the use of an orderby (Order By in Visual Basic) clause. |
|
Specifies that PLINQ for the rest of the query is not required to preserve the ordering of the source sequence. |
|
Specifies that PLINQ should periodically monitor the state of the provided cancellation token and cancel execution if it is requested. |
|
Specifies the maximum number of processors that PLINQ should use to parallelize the query. |
|
Provides a hint about how PLINQ should, if it is possible, merge parallel results back into just one sequence on the consuming thread. |
|
Specifies whether PLINQ should parallelize the query even when the default behavior would be to run it sequentially. |
|
A multithreaded enumeration method that, unlike iterating over the results of the query, enables results to be processed in parallel without first merging back to the consumer thread. |
|
|
An overload that is unique to PLINQ and enables intermediate aggregation over thread-local partitions, plus a final aggregation function to combine the results of all partitions. |
|
ForEach and ForAll
In sequential LINQ queries, execution is deferred until the query is enumerated either in a In PLINQ,
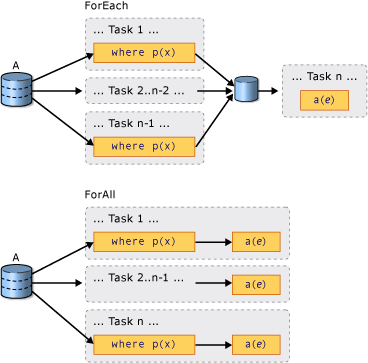
|
Appendix A: FAQ
A.1. What happens on Thread.Sleep(0) in .NET?
|
> What happens on Thread.Sleep(0) in .NET? * In .NET, It’s effectively a way to signal to the operating system that the thread is willing to give up its slice of processor time, if there are other threads that are ready to run on the same processor. However, This can be useful to prevent a thread from consuming too much CPU time in a busy-wait scenario or when you might want to give other threads the chance to run. Remember that using |
A.2. What are the worker and completion port threads?
//
// Summary:
// Sets the number of requests to the thread pool that can be active concurrently.
// All requests above that number remain queued until thread pool threads become
// available.
//
// Parameters:
// workerThreads:
// The maximum number of worker threads in the thread pool.
//
// completionPortThreads:
// The maximum number of asynchronous I/O threads in the thread pool.
//
// Returns:
// true if the change is successful; otherwise, false.
public static bool SetMaxThreads(int workerThreads, int completionPortThreads);
public static bool SetMinThreads(int workerThreads, int completionPortThreads);|
> What are the worker and completion port threads in SetMaxThreads(int workerThreads, int completionPortThreads)? * The
The threadpool maintains two types of threads, worker threads for the most part handle compute operations and I/O threads handle as the name suggests handle I/O bound operations. Asynchronous I/O operations, which are operations that complete at some later point, often use callback methods to signal completion. When the system calls these callback methods, it does so using a thread from the ThreadPool. The It’s typically not necessary to change the ThreadPool size, because the ThreadPool already optimizes the number of threads it uses based on the number of CPUs and the types of tasks it’s running. In most cases, ThreadPool is efficient in managing its threads. Its algorithm aims to efficiently use all available CPU resources while not overloading the system with too many threads at the same time. It tries to maintain a balance. |
A.3. How does .NET identify I/O-bound or compute-bound operations?
|
> How does .NET identify I/O-bound or compute-bound operations? * The .NET runtime itself doesn’t actively categorize tasks as I/O-bound or compute-bound. It’s up to developers to ensure that appropriate APIs and techniques are used for I/O-bound and compute-bound tasks. For I/O-bound operations, which typically include file, database, and network operations, you should use asynchronous methods when they’re available to avoid blocking (or tying up) a thread from the thread pool. When an I/O-bound operation is asynchronous, this generally means the operation is offloaded to the operating system, freeing up the .NET runtime thread to perform other work. I/O bound means the data is transferred between the CPU and the peripheral devices (disk, network, etc.), during which the CPU isn’t doing much work. On the other hand, when a task is compute-bound, meaning it involves heavy computations and keeps the processor busy, developers should generally use synchronous methods and potentially multiple threads to utilize more cores and finish the computations faster. This kind of operation is typically done in parallel to split the work across multiple threads, where each thread uses synchronous code to do its part of the work. So, while .NET doesn’t automatically distinguish between I/O-bound and compute-bound operations, it provides facilities (like asynchronous methods for I/O-bound tasks and parallel processing techniques such as the TPL for compute-bound tasks) for developers to write efficient code for both types of operations. |
|
> How to understand 'It’s up to developers…'? * What "It’s up to developers…" means is that the .NET runtime, or indeed any other runtime, cannot automatically discern if the operation you’re performing is I/O-bound or compute-bound. It’s the responsibility of the developer writing the code to understand what kind of operation they’re performing and to use the correct method to handle it. For example,
The appropriate programming approach (asynchronous or multithreaded) is dictated by the nature of the operation. The developer must know their application, the tasks, and their nature, and then use the appropriate method. The .NET runtime will not do this discernment automatically. |
A.4. How does CLR manage the number of threads (worker and I/O threads) in the ThreadPool?
|
> How does CLR manage the number of threads (worker and I/O threads) in the ThreadPool? * The CLR, or Common Language Runtime, uses a set algorithm to manage the number of threads in its ThreadPool. Upon application startup, the ThreadPool possesses few threads. As requests come in, threads are added to fulfill those requests. The CLR considers several factors to make an adjustment, including the workload demand, number of processors, and the number of existing threads. For each pending task or work item, a check is performed to see if a thread is available. If not, and the current thread count is below the maximum limit, a new thread is created unless we’ve reached the maximum limit "rate". If a ThreadPool thread is idle for some time (around a minute), it gets terminated, which reduces resource usage. If the thread count reaches the max limit and the requests are still not fulfilled, they are queued. "Worker" threads are commonly used for executing synchronous and asynchronous managed code, and "I/O threads" are specifically designated for completing I/O-bound work. Both the maximum threads and "rate" are automatically set based on several factors like the size of virtual memory, number of processors available, etc. The thread injection rate (how often new threads are added) aids to prevent situations where rapidly creating too many threads would cause resource saturation and decrease performance. You can manually get and change the minimum and maximum number of threads in the ThreadPool by using However, it’s recommended to let the CLR manage the threading details because of its smart heuristics and tuning based on extensive research and testing. Custom changes should only be made after careful testing and analysis. |
A.5. What’s the algorithm of the thread pool in .NET?
|
> What’s the algorithm of the thread pool in .NET? * According to .NET’s official documentation, the CLR employs a hill-climbing algorithm for adjusting the number of ThreadPool threads that can run simultaneously. This heuristic algorithm is designed specifically to find the most efficient and effective number of threads for any given workload. Here’s how the algorithm works:
This algorithm works to maintain a balance between the number of threads and the amount of work that needs to be done. By ensuring threads are only created as needed, and cleaning up idle threads, it helps to optimize the system resources and performance. It’s important to note that the .NET ThreadPool’s algorithm is intentionally not publicly documented in detail because it’s subject to change as Microsoft fine-tunes it based on new findings and requirements. As always, it’s recommended to let the CLR manage the ThreadPool for you, unless you have a specific reason and have done careful performance analysis. |
A.6. What if Interlocked.Increment a 64-bit integer on a 32-bit hardware?
|
> About the Interlocked class in .NET, what if we increment a 64-bit integer on a 32-bit hardware? * The In a multithreaded or parallel computing scenario, multiple threads might be trying to increment the value of a shared 64-bit integer simultaneously. In such a case, However, performing atomic operations on a 64-bit integer (long/Int64) in 32-bit hardware requires two CPU instructions, because the size of the long value is greater than the word size of the 32-bit processor. But even then, .NET runtime ensures via Still, it’s important to note that such atomic operations come with a slightly increased performance overhead as compared to non-atomic operations, due to preventing reordering and caching of the value being incremented. Thus, they must be used judiciously. |
A.7. How does .NET make the multiple CPU instructions as an atomic?
|
> How does CLR make the two CPU instructions as an atomic? * The .NET Common Language Runtime (CLR) and the underlying operating system provide certain guarantees to ensure atomicity of operations on 64-bit values, even on 32-bit platforms. The On Windows, for example, this can be achieved using a combination of OS-provided synchronization primitives and specific processor instructions. For instance, the When you call an These atomic operations prevent any thread interference or inconsistencies while performing read-modify-write actions by ensuring that the operation is completed as a single, uninterruptible unit. |
A.8. I heard there are some risk on atomic operations in Go or sth else?
|
> I heard there are some risk on atomic operations in Go or sth else? * Yes, coding with atomic operations can indeed be risky, not just in Go but in any language, if they are misused or misunderstood. Here are a few reasons why this is the case:
In Go, for example, the So while atomic operations are a powerful tool in concurrent programming, they are best suited for a limited set of problems and should be used judiciously and cautiously, usually when performance is a dicerning factor and you’re comfortable and proficient with the complexities of concurrent system behaviour and memory models. |
A.9. What’s ABA problems?
|
> What’s ABA problems? * The ABA problem is a particularly tricky issue that can occur in multi-threaded or concurrent programs that use lock-free data structures and make use of atomic primitives, such as Compare-and-Swap (CAS). Here’s a brief explanation of the ABA problem:
The result here is that Thread A acted on the assumption that nothing had changed when actually something had, but it was effectively invisible to it. This can have outcomes ranging from inconsequential to catastrophic, depending on what the shared data is used for. This is the ABA problem. This issue is typically resolved by assigning a version number or a timestamp along with every change so that the revisiting thread can check not only the value but whether it is the same instance of the value it observed before. This kind of solution is often referred to as "tagging". Double-width Compare-and-Swap (DWCAS) or similar atomic primitives are used to atomically change the value and its associated version number or tag. |
A.10. How to understand 'hardware, compilers, and the language memory model'?
|
> How to understand 'hardware, compilers, and the language memory model'? * Understanding 'hardware, compilers, and the language memory model' is important when working with lower-level concurrent constructs such as atomic operations or volatile fields. Let me break them down:
All these can significantly impact the correctness, performance, and portability of multi-threaded code. Learning about them usually involves studying computer architecture, compilations, operating systems, and of course, the programming language’s specification. For most developers, however, using higher-level synchronization primitives and libraries that abstract these details away is sufficient and recommended. |
A.11. Anyway, for a single operation like Interlocked.Increment, it will always ensure it as an atomic?
|
> Anyway, for a single operation like * Yes, for the This method guarantees that the increment operation, which is otherwise a read-modify-write operation consisting of multiple steps, is executed in a single, unbroken step. No context switch or thread interference can happen in the middle of the operation that could leave the data in an inconsistent state. It can be used safely in a multithreaded and concurrent environment, ensuring that all incrementing operations on a shared variable are done in full, one at a time. Please be aware that while |
A.12. How to understand the volatile keyword in .NET?
|
> How to understand the volatile keyword in .NET? And how to understand "There is no guarantee of a single total ordering of volatile writes as seen from all threads of execution."? * The In multithreaded applications, the The quote "There is no guarantee of a single total ordering of volatile writes as seen from all threads of execution" means that the order in which threads observe volatile writes may not be consistent across all threads. While Here’s an example to illustrate: The volatile keyword ensures that Thread 1 will write to variable A before variable B. If Thread 2 reads variable B, it will see this write (or a later one). However, another volatile read to variable A can still return an older value. This is because the volatile read from variable B does not provide 'release-fence' semantics; it doesn’t force a refresh of all other modifications. This is why it’s often recommended to use higher-level synchronization constructs (like |
|
> How to understand "On a multiprocessor system, a volatile read operation does not guarantee to obtain the latest value written to that memory location by any processor."? * This statement draws attention to an important fact about volatile keyword usage in .NET on a multiprocessor system where threads could be executing on different processors. The volatile keyword in C# tells the compiler not to reorder reads or writes to a field, or cache the field in a register, which helps ensure that all reads and writes on one processor occur in the order they’re specified in the code. Because of this, the volatile keyword is helpful for ensuring consistency in a multithreaded context. However, it does not guarantee immediate visibility on all processors. For example, if one processor writes to a volatile field and another processor reads from that field, the reading processor might not get the most recent value written by the writing processor. The reasons can include delay due to propagation of write from one processor’s cache to others (in a multiprocessor, multi-caching systems) or the order in which these reads and writes are performed. This is why it’s stated that "On a multiprocessor system, a volatile read operation does not guarantee to obtain the latest value written to that memory location by any processor." In general, for complex synchronization or if strong cross-processor memory guarantees are required, usage of higher-level synchronization primitives or constructs (like locks, |
A.13. What’s the diff of volatile keyword and Volatile class?
|
> What’s the diff of volatile keyword and Volatile class? * The The The So, while both are used for volatile memory operations, the |
A.14. It seems we should avoid to use the volatile keyword?
|
> It’s about the happen-before on a memory model. It seems we should avoid to use the volatile keyword? * In general, understanding and correctly using the The primary purpose of However, using Higher-level concurrency constructs (
In the end, |
A.15. What’s the diff of asynchronous and parallel programming in .NET?
|
> What’s the diff of asynchronous and parallel programming in .NET? * In .NET, both asynchronous and parallel programming paradigms are used to execute code that can potentially run concurrently to improve performance. However, they are used in different scenarios and address different types of problems.
Asynchronous programming is about freeing up the main executing thread to do other work when it would otherwise be blocked, usually waiting for I/O operations (like reading a file, downloading from the internet, querying a database, etc.). The goal of asynchronous programming is to make the application more responsive. With async programming, the application can yield control while it waits on these long-running tasks, allowing it to perform other tasks concurrently. In .NET, you often see
Parallel programming, on the other hand, is about executing multiple operations, or tasks, at the same time by utilizing multiple cores of the CPU. This is particularly helpful for CPU-bound work that can be broken down into smaller, independent tasks and processed in parallel. For example, if you’re processing an array of elements, you can use parallel programming to process multiple elements at the same time in different cores. In .NET, this could be achieved using the In summary, use asynchronous programming when dealing with I/O-bound tasks to avoid blocking and keep the application responsive, and use parallel programming when trying to break down CPU-intensive tasks to run simultaneously to improve throughput. |
A.16. What’s the control meaning in async and await programming?
|
> What’s the 'control' meaning in async and await programming? * In the context of asynchronous programming with When you call an When the awaited operation (such as an I/O operation, web request, etc.) completes, the remainder of the So "yielding control" in |
|
> What’s the underneath in 'control', like a thread or sth else? * "Control" primarily refers to the sequence of execution of code or the flow of a program. When we talk about control in the context of On a lower level in .NET runtime, this "control" is facilitated by the Task Scheduler and in many scenarios, the synchronization context. Here’s a simplified view: When a method awaits an operation (e.g. In a UI-based application, the synchronization context is typically tied to the main UI thread, which allows the continuation (the code following the await keyword) to be executed on the same UI thread. This makes async programming easier and safer in a UI context. In an environment without a SynchronizationContext (like in Console applications or thread pool threads), the default TaskScheduler schedules the continuation to run on the ThreadPool. With this in mind, when you call Again, this is a simplified view. In reality, there are several optimizations and mechanisms in place to make async programming more efficient and easier to use. |
|
> Does it mean the 'someTask' will be executed on another thread? * Not necessarily. When you call an async method, it does its work on the same thread that called it until it awaits an incomplete task. At the await, if the task isn’t already complete, the async method is paused and control returns to the caller of the async method. This all happens on the same thread, and no extra threads are created. What happens next depends on what the awaited task is doing. Here’s a simple way to think about it:
When the awaited operation completes, the remainder of the async method is scheduled to continue running. The scheduling depends on the context when the 'await' keyword is encountered. In a UI application, it resumes on the UI thread (as this is the captured context); for a server application, it generally runs on a ThreadPool thread, but not necessarily the same thread as the one it started. Remember, in most cases, async doesn’t mean concurrent or multi-threaded. Async methods don’t require multithreading because an async method doesn’t run on its own thread. The method runs on the current synchronization context and uses time on the thread only when the method is active. You can use |
A.17. How to understand "Async methods don’t require multithreading because an async method doesn’t run on its own thread."?
|
> How to understand "Async methods don’t require multithreading because an async method doesn’t run on its own thread."? * In asynchronous programming, the fundamental misunderstanding is often thinking that "asynchronous" automatically means "on a different thread". This is not strictly true. When you mark a method with An At that point, assuming the task being awaited has not yet completed, the method yields and the remainder of the method is turned into a continuation that will be invoked once the awaited operation completes. What’s important to understand here is that the continuation does not have to run on the same thread where it left off - it could run on whatever thread the completed task calls back on. So an However, if you were to use So to sum it up, |
A.18. Can the async/await improve the responsiveness on ASP.NET Core?
|
> Can the async/await improve the responsiveness on ASP.NET Core? * Yes, utilizing The primary benefit of using In a synchronous ASP.NET Core application without In ASP.NET Core, when you use async methods and await async tasks, the thread handling the request can be used for starting another request as soon as it enters a waiting state (awaiting I/O-bound operation). So by leveraging |
|
> It seems that it is because the I/O operations are offloaded from the current thread, and release the CPU capacity. But who should be in charge of the I/O operations? * Yes, that’s correct. The benefit of The operating system is in charge of coordinating and managing I/O operations. When you start an I/O-bound operation, like reading from disk or making a network request, the request is sent to the operating system. The operating system takes care of the actual I/O operation, interfacing with the necessary hardware, like the disk or network card. From your application’s perspective, once you start an I/O operation and So you can think of I/O-bound |
|
> Actually, if we use sync methods, the current thread will be in wait status for the I/O. but it still can free up CPU. * Yes, you’re correct. Even with synchronous I/O operations, the CPU isn’t actively engaged the whole time. The operating system still manages the I/O operation, and the CPU is freed up to perform other tasks. However, the key difference lies in the usage of threads. In synchronous operations, the thread performing the operation goes into a wait state and cannot be used for anything else. This means the application can handle fewer concurrent operations, as it might run out of available threads if multiple I/O operations are waiting to complete. With asynchronous operations using So while both sync and async free up CPU during I/O operations, async also allows for the thread to be reused during this time, leading to more efficient utilization of system resources. |
|
> This is the non-blocking I/O in essence? * Exactly, using In blocking or synchronous I/O, the execution thread is halted—or "blocked"—until the I/O operation completes. This means the thread can’t be used for any other tasks, regardless of how long the I/O operation takes. Non-blocking or asynchronous I/O, on the other hand, starts the I/O operation and then allows the execution thread to continue other tasks. It doesn’t wait for the I/O operation to complete. Instead, it will be notified once the I/O operation is done, at which point it can proceed with any steps that depend on the result. Thus, by enabling non-blocking I/O, the |
|
* Here’s a summary of the key points regarding the use of
|
A.19. Is there a SynchronizationContext on ASP.NET Core?
|
> Is there a SynchronizationContext on ASP.NET Core? * No, there’s no In traditional .NET Framework, In ASP.NET Framework, However, ASP.NET Core does not have a With that said, developers need to be aware that the code after an |
A.20. What’s the diff of AsOrdered and AsUnordered in PLINQ?
|
> What’s the diff of AsOrdered and AsUnordered in PLINQ? * In PLINQ, the methods The The It’s important to note that by default, PLINQ tries to preserve the original order, so Partitioning is the process in which PLINQ divides the source data into multiple chunks, or partitions, so that it can process them independently and concurrently on multiple cores. Order preservation affects this partitioning process:
Generally, if the order in which results are produced doesn’t matter, you should use |
References
-
[1] https://learn.microsoft.com/en-us/dotnet/standard/threading/threads-and-threading
-
[2] https://learn.microsoft.com/en-us/dotnet/standard/threading/using-threads-and-threading
-
[3] https://learn.microsoft.com/en-us/dotnet/standard/threading/cancellation-in-managed-threads
-
[4] https://learn.microsoft.com/en-us/dotnet/standard/threading/pausing-and-resuming-threads
-
[5] https://learn.microsoft.com/en-us/dotnet/standard/threading/the-managed-thread-pool
-
[6] https://learn.microsoft.com/en-us/dotnet/standard/threading/overview-of-synchronization-primitives
-
[7] https://learn.microsoft.com/en-us/dotnet/standard/threading/eventwaithandle
-
[8] https://devblogs.microsoft.com/dotnet/an-introduction-to-system-threading-channels/
-
[9] https://learn.microsoft.com/en-us/dotnet/csharp/language-reference/keywords/volatile
-
[10] https://learn.microsoft.com/en-us/dotnet/standard/asynchronous-programming-patterns/
-
[11] https://learn.microsoft.com/en-us/dotnet/desktop/wpf/advanced/threading-model
-
[12] https://learn.microsoft.com/en-us/dotnet/framework/performance/lazy-initialization
-
[13] https://learn.microsoft.com/en-us/dotnet/standard/parallel-programming/
-
[14] https://learn.microsoft.com/en-us/dotnet/standard/parallel-programming/data-parallelism-task-parallel-library
-
[15] https://learn.microsoft.com/en-us/dotnet/standard/parallel-programming/task-based-asynchronous-programming
-
[16] https://learn.microsoft.com/en-us/dotnet/csharp/asynchronous-programming/task-asynchronous-programming-model
-
[17] https://devblogs.microsoft.com/dotnet/how-async-await-really-works/
-
[18] https://devblogs.microsoft.com/dotnet/configureawait-faq/
-
[20] https://learn.microsoft.com/en-us/dotnet/standard/parallel-programming/introduction-to-plinq
-
[21] https://learn.microsoft.com/en-us/dotnet/standard/parallel-programming/dataflow-task-parallel-library
-
[22] https://blog.stephencleary.com/2017/03/aspnetcore-synchronization-context.html
-
[23] https://learn.microsoft.com/en-us/windows/win32/fileio/i-o-completion-ports
-
[24] https://devblogs.microsoft.com/dotnet/performance-improvements-in-net-6/
-
[25] https://learn.microsoft.com/en-us/archive/msdn-magazine/2010/september/concurrency-throttling-concurrency-in-the-clr-4-0-threadpool
-
[27] https://devblogs.microsoft.com/pfxteam/executioncontext-vs-synchronizationcontext/
-
[28] https://devblogs.microsoft.com/dotnet/understanding-the-whys-whats-and-whens-of-valuetask/
-
[29] https://devblogs.microsoft.com/pfxteam/task-run-vs-task-factory-startnew/
-
[30] https://learn.microsoft.com/en-us/dotnet/csharp/asynchronous-programming/async-scenarios