
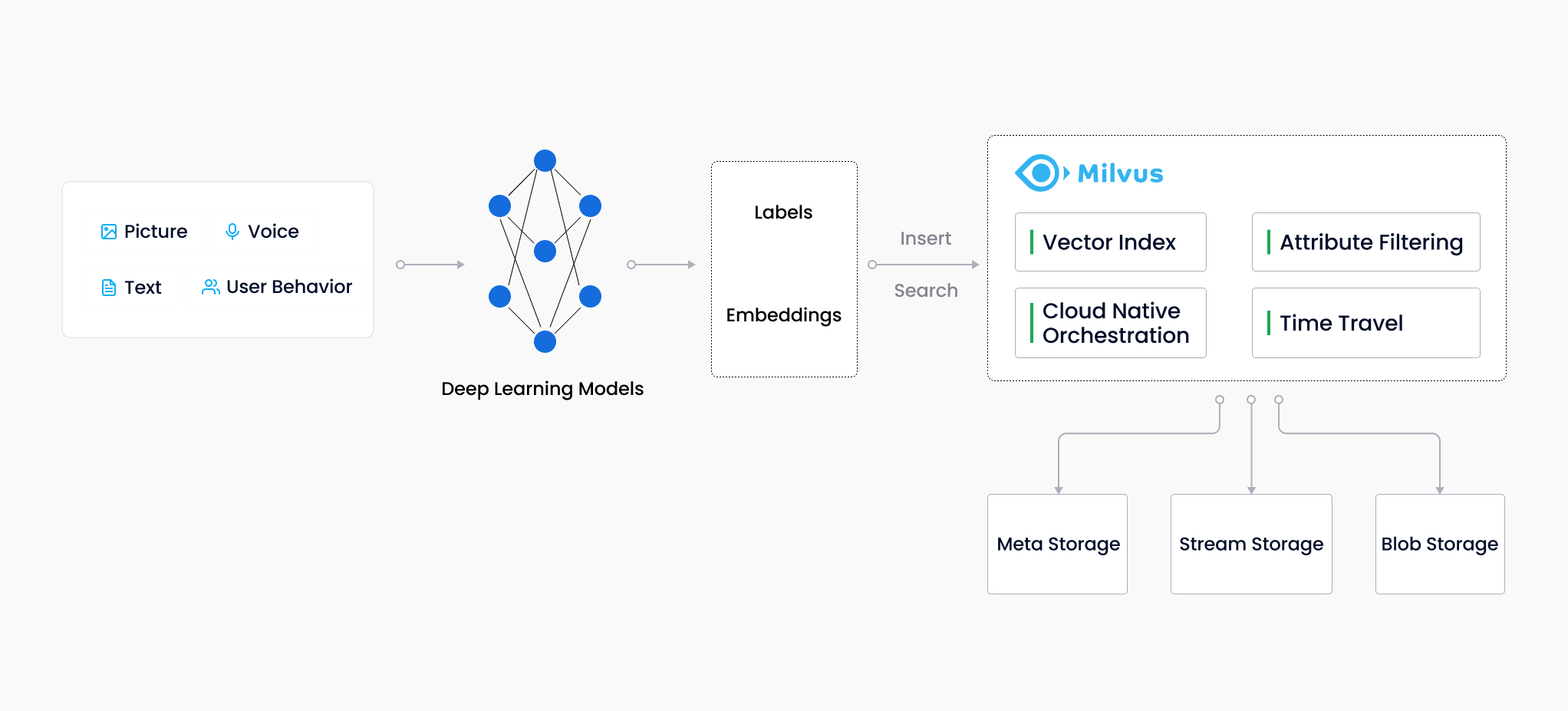
Milvus (/ˈmɪlvəs/) is an open-source vector database to store, index, and manage massive embedding vectors generated by deep neural networks and machine learning (ML) models. [1]
Unlike existing relational databases which mainly deal with structured data following a pre-defined pattern, Milvus is designed from the bottom-up to handle embedding vectors converted from unstructured data, including images, video, audio, and natural language.
Embedding vectors or vectors, the output data format of Neural Network models, can effectively encode information and serve a pivotal role in AI applications such as knowledge base, semantic search, Retrieval Augmented Generation (RAG) and more. Mathematically speaking, an embedding vector is an array of floating-point numbers or binaries. Modern embedding techniques are used to convert unstructured data to embedding vectors.
Milvus is able to analyze the correlation between two vectors by calculating their similarity distance. If the two embedding vectors are very similar, it means that the original data sources are similar as well. Vector similarity search is the process of comparing a vector to a database to find vectors that are most similar to the query vector. Approximate nearest neighbor (ANN) search algorithms are used to accelerate the searching process. If the two embedding vectors are very similar, it means that the original data sources are similar as well.
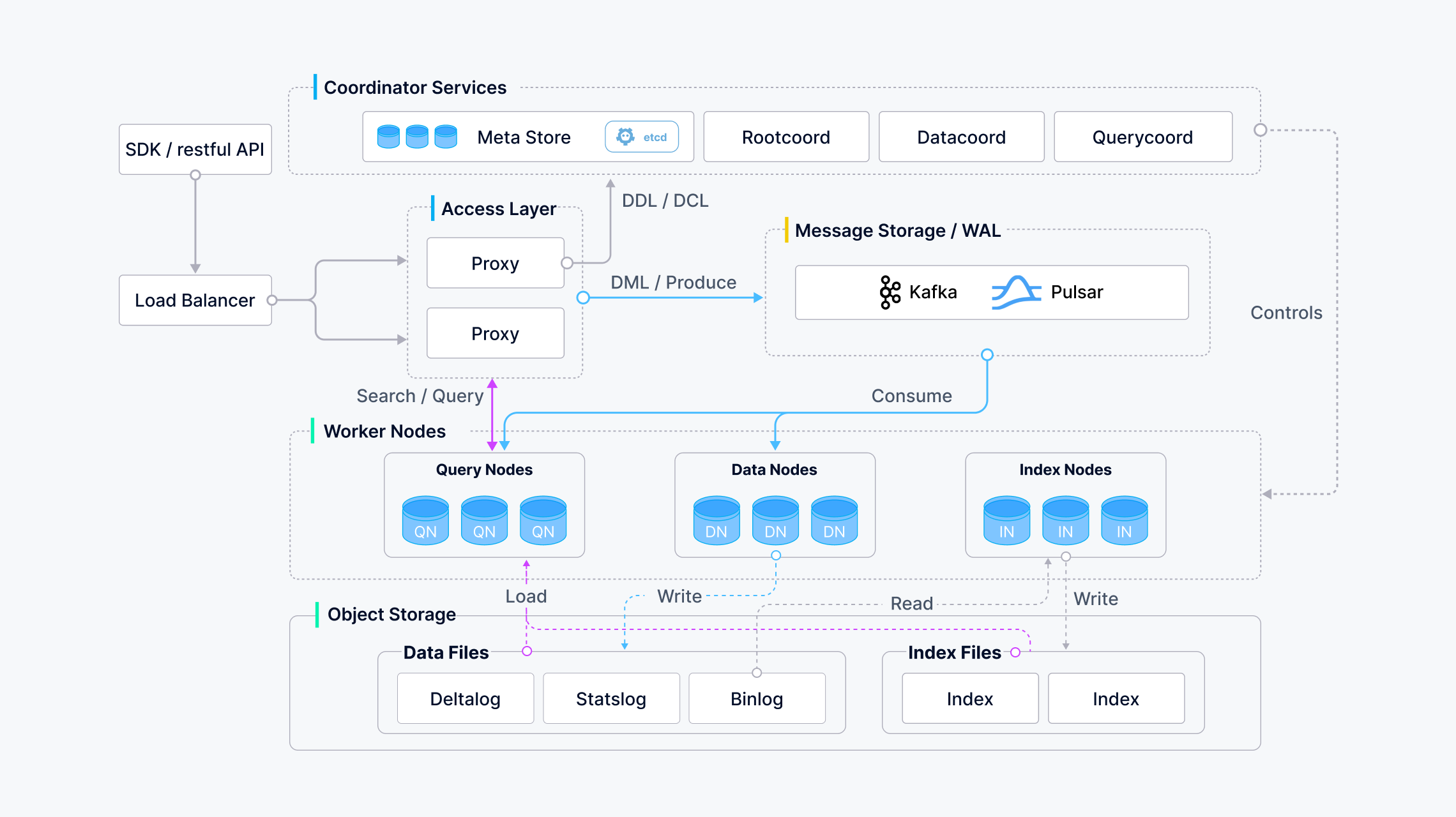
Milvus adopts a shared-storage architecture featuring storage and computing disaggregation and horizontal scalability for its computing nodes. Following the principle of data plane and control plane disaggregation, Milvus comprises four layers: access layer, coordinator service, worker node, and storage. [2]
1. Install Milvus
Milvus Lite is good for getting started with vector search or building demos and prototypes, and supports the following OS distributions and sillicon types: Ubuntu >= 20.04 (x86_64), and macOS >= 11.0 (Apple Silicon and x86_64), and Debian 12 (x86_64) on Windows with WSL 2 enabled. [4] [5]
For a production use case, It’s recommended using Milvus on Docker and Kubenetes, or considering the fully-managed Milvus on Zilliz Cloud.
All deployment modes of Milvus share the same API, so your client side code doesn’t need to change much if moving to another deployment mode. Simply specify the URI and Token of a Milvus server deployed anywhere: [5]
from pymilvus import MilvusClient
# Authentication not enabled
client = MilvusClient("http://localhost:19530")
# Authentication enabled with the root user
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus",
db_name="default"
)
# Authentication enabled with a non-root user
client = MilvusClient(
uri="http://localhost:19530",
token="user:password", # replace this with your token
db_name="default"
)Milvus provides REST and gRPC API, with client libraries in languages such as Python, Java, Go, C# and Node.js.
1.1. Run Milvus with Docker Compose
Milvus provides a Docker Compose configuration file in the Milvus repository. To install Milvus using Docker Compose, just run [install_standalone-docker-compose]
# Download the configuration file
$ wget https://github.com/milvus-io/milvus/releases/download/v2.4.4/milvus-standalone-docker-compose.yml -O docker-compose.yml
# Start Milvus
$ sudo docker compose up -d
Creating milvus-etcd ... done
Creating milvus-minio ... done
Creating milvus-standalone ... doneAfter starting up Milvus, containers named milvus-standalone, milvus-minio, and milvus-etcd are up.
-
The
milvus-etcdcontainer does not expose any ports to the host and maps its data tovolumes/etcdin the current folder. -
The
milvus-miniocontainer serves ports9090and9091locally with the default authentication credentials and maps its data tovolumes/minioin the current folder. -
The
milvus-standalonecontainer serves ports19530locally with the default settings and maps its data tovolumes/milvusin the current folder.
You can check if the containers are up and running using the following command:
$ sudo docker compose ps
Name Command State Ports
--------------------------------------------------------------------------------------------------------------------
milvus-etcd etcd -advertise-client-url ... Up 2379/tcp, 2380/tcp
milvus-minio /usr/bin/docker-entrypoint ... Up (healthy) 9000/tcp
milvus-standalone /tini -- milvus run standalone Up 0.0.0.0:19530->19530/tcp, 0.0.0.0:9091->9091/tcpYou can stop and delete this container as follows
# Stop Milvus
$ sudo docker compose down
# Delete service data
$ sudo rm -rf volumes1.2. Run Milvus Lite locally
Milvus Lite is the lightweight version of Milvus included in the Python SDK of Milvus, which can be imported into a Python application, providing the core vector search functionality of Milvus.
-
Install Milvus
# set up Milvus Lite with pymilvus, the Python SDK library of Milvus pip install "pymilvus>=2.4.2" -
Set up vector database
# connect to Milvus Lite from pymilvus import MilvusClient # generate or load an existing vector database file named milvus_demo.db in the current folder client = MilvusClient("milvus_demo.db") -
Create a collection
# create a collection to store vectors and their associated metadata client.create_collection( collection_name="demo_collection", dimension=768, # The vectors we will use in this demo has 768 dimensions )-
The primary key and vector fields use their default names ("id" and "vector").
-
The metric type (vector distance definition) is set to its default value (COSINE).
-
The primary key field accepts integers and does not automatically increments (namely not using auto-id feature)
-
-
Represent text with vectors
-
To perform semantic search on text, it’s needed to generate vectors for text by downloading embedding models, which can be easily done by using the utility functions from
pymilvus[model]library including essential ML tools such as PyTorch.pip install "pymilvus[model]>=2.4.2" -
Milvus expects data to be inserted organized as a list of dictionaries, where each dictionary represents a data record, termed as an entity.
# generate vector embeddings with default model from pymilvus import model # If connection to https://huggingface.co/ failed, uncomment the following path # import os # os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' # This will download a small embedding model "paraphrase-albert-small-v2" (~50MB). embedding_fn = model.DefaultEmbeddingFunction() # Text strings to search from. docs = [ "Artificial intelligence was founded as an academic discipline in 1956.", "Alan Turing was the first person to conduct substantial research in AI.", "Born in Maida Vale, London, Turing was raised in southern England.", ] vectors = embedding_fn.encode_documents(docs) # The output vector has 768 dimensions, matching the collection that we just created. print("Dim:", embedding_fn.dim, vectors[0].shape) # Dim: 768 (768,) # Each entity has id, vector representation, raw text, and a subject label that we use # to demo metadata filtering later. data = [ {"id": i, "vector": vectors[i], "text": docs[i], "subject": "history"} for i in range(len(vectors)) ] print("Data has", len(data), "entities, each with fields: ", data[0].keys()) print("Vector dim:", len(data[0]["vector"]))Dim: 768 (768,) Data has 3 entities, each with fields: dict_keys(['id', 'vector', 'text', 'subject']) Vector dim: 768 -
Insert data into the collection.
res = client.insert(collection_name="demo_collection", data=data) print(res){'insert_count': 3, 'ids': [0, 1, 2], 'cost': 0}
-
-
Semantic search
-
Milvus accepts one or multiple vector search requests as a list of vectors, where each vector is an array of float numbers, at the same time.
# from pymilvus import MilvusClient, model # # client = MilvusClient("milvus_demo.db") # # # If connection to https://huggingface.co/ failed, uncomment the following path # import os # os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' # # # This will download a small embedding model "paraphrase-albert-small-v2" (~50MB). # embedding_fn = model.DefaultEmbeddingFunction() query_vectors = embedding_fn.encode_queries(["Who is Alan Turing?"]) res = client.search( collection_name="demo_collection", # target collection data=query_vectors, # query vectors limit=2, # number of returned entities output_fields=["text", "subject"], # specifies fields to be returned ) print(res)data: ["[{'id': 2, 'distance': 0.5859944820404053, 'entity': {'text': 'Born in Maida Vale, London, Turing was raised in southern England.', 'subject': 'history'}}, {'id': 1, 'distance': 0.5118255019187927, 'entity': {'text': 'Alan Turing was the first person to conduct substantial research in AI.', 'subject': 'history'}}]"] , extra_info: {'cost': 0}# Vector search with metadata filtering # Insert more docs in another subject. docs = [ "Machine learning has been used for drug design.", "Computational synthesis with AI algorithms predicts molecular properties.", "DDR1 is involved in cancers and fibrosis.", ] vectors = embedding_fn.encode_documents(docs) data = [ {"id": 3 + i, "vector": vectors[i], "text": docs[i], "subject": "biology"} for i in range(len(vectors)) ] client.insert(collection_name="demo_collection", data=data) # This will exclude any text in "history" subject despite close to the query vector. res = client.search( collection_name="demo_collection", data=embedding_fn.encode_queries(["tell me AI related information"]), filter="subject == 'biology'", limit=2, output_fields=["text", "subject"], ) print(res)data: ["[{'id': 4, 'distance': 0.27030572295188904, 'entity': {'text': 'Computational synthesis with AI algorithms predicts molecular properties.', 'subject': 'biology'}}, {'id': 3, 'distance': 0.1642588973045349, 'entity': {'text': 'Machine learning has been used for drug design.', 'subject': 'biology'}}]"] , extra_info: {'cost': 0} -
A query() is an operation that retrieves all entities matching a cretria, such as a filter expression or matching some ids.
# retrieving all entities whose scalar field has a particular value res = client.query( collection_name="demo_collection", filter="subject == 'history'", output_fields=["text", "subject"], )# retrieving entities by primary key directly res = client.query( collection_name="demo_collection", ids=[0, 2], output_fields=["vector", "text", "subject"], )
-
-
Delete entities specifying the primary key or delete all entities matching a particular filter expression.
# Delete entities by primary key res = client.delete(collection_name="demo_collection", ids=[0, 2]) print(res) # Delete entities by a filter expression res = client.delete( collection_name="demo_collection", filter="subject == 'biology'", ) print(res) # Drop collection client.drop_collection(collection_name="demo_collection")[0, 2] [3, 4, 5]
1.3. Milvus Command-Line Interface (CLI)
Milvus Command-Line Interface (CLI), based on Milvus Python SDK, is a command-line tool that supports database connection, data operations, and import and export of data. [6]
-
Install via pip
pip install milvus-cli -
Install with Docker
docker run -it zilliz/milvus_cli:latest -
Commands
milvus_cli > connect -uri http://127.0.0.1:19530 milvus_cli > create database -db testdb milvus_cli > list databases milvus_cli > use database -db testdb milvus_cli > list collections milvus_cli > show collection -c test_collection_insert milvus_cli > list connections milvus_cli > search Collection name (car, test_collection): car The vectors of search data(the length of data is number of query (nq), the dim of every vector in data must be equal to vector field’s of collection. You can also import a csv file out headers): examples/import_csv/search_vectors.csv The vector field used to search of collection (vector): vector Metric type: L2 Search parameter nprobe's value: 10 The max number of returned record, also known as topk: 2 The boolean expression used to filter attribute []: id > 0 The names of partitions to search (split by "," if multiple) ['_default'] []: _default timeout []: Guarantee Timestamp(It instructs Milvus to see all operations performed before a provided timestamp. If no such timestamp is provided, then Milvus will search all operations performed to date) [0]:
2. Schema and collections
In Milvus, schema is used to define the properties of a collection and the fields within. [7]
-
A field schema is the logical definition of a field, and Milvus supports only one primary key field in a collection.
To reduce the complexity in data inserts, Milvus allows to specify a default value for each scalar field during field schema creation, excluding the primary key field.
-
Create a regular field schema:
from pymilvus import FieldSchema id_field = FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, description="primary id") age_field = FieldSchema(name="age", dtype=DataType.INT64, description="age") embedding_field = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128, description="vector") # The following creates a field and use it as the partition key position_field = FieldSchema(name="position", dtype=DataType.VARCHAR, max_length=256, is_partition_key=True) -
Create a field schema with default field values:
from pymilvus import FieldSchema fields = [ FieldSchema(name="id", dtype=DataType.INT64, is_primary=True), # configure default value `25` for field `age` FieldSchema(name="age", dtype=DataType.INT64, default_value=25, description="age"), embedding_field = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128, description="vector") ]
-
-
A collection schema is the logical definition of a collection.
Define the field schemas before defining a collection schema. -
Create a collection schema
from pymilvus import FieldSchema, CollectionSchema id_field = FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, description="primary id") age_field = FieldSchema(name="age", dtype=DataType.INT64, description="age") embedding_field = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128, description="vector") # Enable partition key on a field if you need to implement multi-tenancy based on the partition-key field position_field = FieldSchema(name="position", dtype=DataType.VARCHAR, max_length=256, is_partition_key=True) # Set enable_dynamic_field to True if you need to use dynamic fields. schema = CollectionSchema(fields=[id_field, age_field, embedding_field], auto_id=False, enable_dynamic_field=True, description="desc of a collection")Enable dynamic schema by setting enable_dynamic_fieldtoTruein the collection schema. -
Create a collection with the schema specified:
from pymilvus import Collection collection_name1 = "tutorial_1" collection1 = Collection(name=collection_name1, schema=schema, using='default', shards_num=2)
-
2.1. Load & release collection
Before conducting searches in a collection, ensure that the collection is loaded. During the loading process of a collection, Milvus loads the collection’s index file into memory. Conversely, when releasing a collection, Milvus unloads the index file from memory. [8]
-
To load a collection, use the load_collection() method, specifying the collection name.
# Load the collection client.load_collection( collection_name="customized_setup_2", replica_number=1 # Number of replicas to create on query nodes. Max value is 1 for Milvus Standalone, and no greater than `queryNode.replicas` for Milvus Cluster. ) res = client.get_load_state( collection_name="customized_setup_2" ) print(res) # Output # # { # "state": "<LoadState: Loaded>" # } -
To release a collection, use the release_collection() method, specifying the collection name.
# Release the collection client.release_collection( collection_name="customized_setup_2" ) res = client.get_load_state( collection_name="customized_setup_2" ) print(res) # Output # # { # "state": "<LoadState: NotLoad>" # }
2.2. Dynamic field
The dynamic field in a collection is a reserved JSON field named $meta. It can hold non-schema-defined fields and their values as key-value pairs. Using the dynamic field, search and query both schema-defined fields and any non-schema-defined fields they may have.
-
Enable dynamic field
When defining a schema for a collection, set
enable_dynamic_fieldtoTrueto enable the reserved dynamic field, indicating that any non-schema-defined fields and their values inserted later on will be saved as key-value pairs in the reserved dynamic field.import random, time from pymilvus import connections, MilvusClient, DataType SERVER_ADDR = "http://localhost:19530" # 1. Set up a Milvus client client = MilvusClient( uri=SERVER_ADDR ) # 2. Create a collection schema = MilvusClient.create_schema( auto_id=False, # highlight-next-line enable_dynamic_field=True, ) schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True) schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=5) index_params = MilvusClient.prepare_index_params() index_params.add_index( field_name="id", index_type="STL_SORT" ) index_params.add_index( field_name="vector", index_type="IVF_FLAT", metric_type="L2", params={"nlist": 1024} ) client.create_collection( collection_name="test_collection", schema=schema, index_params=index_params ) res = client.get_load_state( collection_name="test_collection" ) print(res) # Output # # { # "state": "<LoadState: Loaded>" # }# check the details of the collection. res = client.describe_collection( collection_name="test_collection" ) print(res) # Output # # { # "collection_name": "test_collection", # "auto_id": false, # "num_shards": 1, # "description": "", # "fields": [ # { # "field_id": 100, # "name": "id", # "description": "", # "type": 5, # "params": {}, # "is_primary": true # }, # { # "field_id": 101, # "name": "vector", # "description": "", # "type": 101, # "params": { # "dim": 5 # } # } # ], # "aliases": [], # "collection_id": 450568843971279780, # "consistency_level": 2, # "properties": {}, # "num_partitions": 1, # "enable_dynamic_field": true # } -
Insert dynamic data
-
Prepare some randomly generated data for the insertion later on.
colors = ["green", "blue", "yellow", "red", "black", "white", "purple", "pink", "orange", "brown", "grey"] data = [] for i in range(1000): current_color = random.choice(colors) current_tag = random.randint(1000, 9999) data.append({ "id": i, "vector": [ random.uniform(-1, 1) for _ in range(5) ], "color": current_color, "tag": current_tag, "color_tag": f"{current_color}_{str(current_tag)}" }) print(data[0]) -
Insert the data into the collection.
res = client.insert( collection_name="test_collection", data=data, ) print(res) # Output # # { # "insert_count": 1000, # "ids": [ # 0, # 1, # 2, # 3, # 4, # 5, # 6, # 7, # 8, # 9, # "(990 more items hidden)" # ] # } time.sleep(5)
-
-
Search with dynamic fields
# 4. Search with dynamic fields query_vectors = [[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]] res = client.search( collection_name="test_collection", data=query_vectors, filter="color in [\"red\", \"green\"]", search_params={"metric_type": "L2", "params": {"nprobe": 10}}, limit=3 ) print(res) # Output # # [ # [ # { # "id": 863, # "distance": 0.188413605093956, # "entity": { # "id": 863, # "color_tag": "red_2371" # } # }, # { # "id": 799, # "distance": 0.29188022017478943, # "entity": { # "id": 799, # "color_tag": "red_2235" # } # }, # { # "id": 564, # "distance": 0.3492690920829773, # "entity": { # "id": 564, # "color_tag": "red_9186" # } # } # ] # ]
3. Embeddings
Embedding is a machine learning concept for mapping data into a high-dimensional space, where data of similar semantic are placed close together. [9]
-
Typically being a Deep Neural Network from BERT or other Transformer families, the embedding model can effectively represent the semantics of text, images, and other data types with a series of numbers known as vectors.
-
A key feature of these models is that the mathematical distance between vectors in the high-dimensional space can indicate the similarity of the semantics of original text or images, that unlocks many information retrieval applications, such as web search engines like Google and Bing, product search and recommendations on e-commerce sites, and the recently popular Retrieval Augmented Generation (RAG) paradigm in generative AI.
There are two main categories of embeddings, each producing a different type of vector:
-
Dense embedding: Most embedding models represent information as a floating point vector of hundreds to thousands of dimensions. The output is called "dense" vectors as most dimensions have non-zero values.
Dense embedding is a technique used in natural language processing to represent words or phrases as continuous, dense vectors in a high-dimensional space, capturing semantic relationships.
For instance, the popular open-source embedding model BAAI/bge-base-en-v1.5 outputs vectors of 768 floating point numbers (768-dimension float vector).
-
Sparse embedding: In contrast, the output vectors of sparse embeddings has most dimensions being zero, namely "sparse" vectors. These vectors often have much higher dimensions (tens of thousands or more) which is determined by the size of the token vocabulary.
Sparse vectors can be generated by Deep Neural Networks or statistical analysis of text corpora. Due to their interpretability and observed better out-of-domain generalization capabilities, sparse embeddings are increasingly adopted by developers as a complement to dense embeddings.
Milvus is a vector database designed for vector data management, storage, and retrieval. By integrating mainstream embedding and reranking models, it can easily transform original text into searchable vectors or rerank the results using powerful models to achieve more accurate results for RAG, and simplifies text transformation and eliminates the need for additional embedding or reranking components, thereby streamlining RAG development and validation.
To use embedding functions with Milvus, first install the PyMilvus client library with the model subpackage that wraps all the utilities for embedding generation.
pip install pymilvus[model]
# or pip install "pymilvus[model]" for zsh.
# or pipenv install 'pymilvus[model]==2.4.4' 'numpy<2'The model subpackage supports various embedding models, from OpenAI, Sentence Transformers, BGE M3, BM25, to SPLADE pretrained models.
-
Use default embedding function to generate dense vectors
from pymilvus import model # If connection to https://huggingface.co/ failed, uncomment the following path # import os # os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' # This will download a small embedding model "paraphrase-albert-small-v2" (~50MB). embedding_fn = model.DefaultEmbeddingFunction() # Text strings to search from. docs = [ "Artificial intelligence was founded as an academic discipline in 1956.", "Alan Turing was the first person to conduct substantial research in AI.", "Born in Maida Vale, London, Turing was raised in southern England.", ] vectors = embedding_fn.encode_documents(docs) # The output vector has 768 dimensions, matching the collection that we just created. print("Dim:", embedding_fn.dim, vectors[0].shape) # Dim: 768 (768,) # Each entity has id, vector representation, raw text, and a subject label that we use # to demo metadata filtering later. data = [ {"id": i, "vector": vectors[i], "text": docs[i], "subject": "history"} for i in range(len(vectors)) ] print("Data has", len(data), "entities, each with fields: ", data[0].keys()) print("Vector dim:", len(data[0]["vector"]))Dim: 768 (768,) Data has 3 entities, each with fields: dict_keys(['id', 'vector', 'text', 'subject']) Vector dim: 768# To create embeddings for queries, use the encode_queries() method: query_vectors = embedding_fn.encode_queries(["Who is Alan Turing?"]) -
Use sentence transformer embedding function to generate dense vectors with Sentence Transformer pre-trained models
pip install sentence_transformers # (optional) install sentence_transformers manuallyfrom pymilvus import model # If connection to https://huggingface.co/ failed, uncomment the following path # import os # os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' sentence_transformer_ef = model.dense.SentenceTransformerEmbeddingFunction( model_name='all-MiniLM-L6-v2', # Specify the model name device='cpu' # Specify the device to use, e.g., 'cpu', 'cuda:0'. If None, checks if a GPU can be used. ) docs = [ "Artificial intelligence was founded as an academic discipline in 1956.", "Alan Turing was the first person to conduct substantial research in AI.", "Born in Maida Vale, London, Turing was raised in southern England.", ] docs_embeddings = sentence_transformer_ef.encode_documents(docs) # Print embeddings print("Embeddings:", docs_embeddings) # Print dimension and shape of embeddings print("Dim:", sentence_transformer_ef.dim, docs_embeddings[0].shape)Embeddings: [array([-3.09392996e-02, -1.80662833e-02, 1.34775648e-02, 2.77156215e-02, -4.86349640e-03, -3.12581174e-02, -3.55921760e-02, 5.76934684e-03, 2.80773244e-03, 1.35783911e-01, 3.59678417e-02, 6.17732145e-02, ... -4.61330153e-02, -4.85207550e-02, 3.13997865e-02, 7.82178566e-02, -4.75336798e-02, 5.21207601e-02, 9.04406682e-02, -5.36676683e-02], dtype=float32)] Dim: 384 (384,)# To create embeddings for queries, use the encode_queries() method: queries = ["When was artificial intelligence founded", "Where was Alan Turing born?"] query_embeddings = sentence_transformer_ef.encode_queries(queries) # Print embeddings print("Embeddings:", query_embeddings) # Print dimension and shape of embeddings print("Dim:", sentence_transformer_ef.dim, query_embeddings[0].shape)Embeddings: [array([-2.52114702e-02, -5.29330298e-02, 1.14570223e-02, 1.95571519e-02, -2.46500354e-02, -2.66519729e-02, -8.48201662e-03, 2.82961670e-02, -3.65092754e-02, 7.50745758e-02, 4.28900979e-02, 7.18822703e-02, ... -6.76431581e-02, -6.45996556e-02, -4.67132553e-02, 4.78532910e-02, -2.31596199e-03, 4.13446948e-02, 1.06935494e-01, -1.08258888e-01], dtype=float32)] Dim: 384 (384,)