
SQL (pronounced /ˌɛsˌkjuˈɛl/ S-Q-L; or alternatively as /ˈsiːkwəl/ "sequel") stands for Structured Query Language, which is both an ANSI and ISO standard language that was designed to query and manage data in relational database management systems (RDBMSs).
An RDBMS is a database management system based on the relational model (a semantic model for representing data), which in turn is based on two mathematical branches: set theory and predicate logic.
| "NULL marker" or just "NULL" (/nʌl/) is not a NULL value but rather a marker for a missing value. |
SQL comprises several sub-languages for managing different aspects of a database:
-
Data Definition Language (DDL) defines and manages the structure of database objects with statements such as
CREATE,ALTER, andDROP. -
Data Manipulation Language (DML) retrieves and modifies data using statements like
SELECT,INSERT,UPDATE,DELETE, andMERGE. -
Data Control Language (DCL) manages data access and user permissions through statements such as
GRANTandREVOKE. -
Transaction Control Language (TCL) controls the lifecycle of transactions with statements like
COMMITandROLLBACK.
Microsoft provides T-SQL as a dialect of, or an extension to, SQL in SQL Server—its on-premises RDBMS flavor, and in Azure SQL and Azure Synapse Analytics—its cloud-based RDBMS flavors.
T-SQL is based on standard SQL, but it also provides some nonstandard or proprietary extensions. Moreover, T-SQL does not implement all of standard SQL.
To run T-SQL code against a database, a client application needs to connect to a SQL Server instance and be in the context of, or use, the relevant database.
-
In both SQL Server and Azure SQL Managed Instance, the application can still access objects from other databases by adding the database name as a prefix.
-
Azure SQL Database does not support cross-database/three-part name queries.
SQL Server supports a feature called contained databases that breaks the connection between a database user and an instance-level login.
-
The user (Windows or SQL authenticated) is fully contained within the specific database and is not tied to a login at the instance level.
-
When connecting to SQL Server, the user needs to specify the database to connect, and the user cannot subsequently switch to other user databases.
Unless specified otherwise, all T-SQL references to the name of a database object can be a four-part name in the following form:
-- Machine -> * Servers (instances) -> * Databases -> * Schemas -> * Tables, * Views
server_name.[database_name].[schema_name].object_name
| database_name.[schema_name].object_name
| schema_name.object_name
| object_name- 1. Data Integrity
- 2. Logical Query Processing
- 3. Predicates and Operators
- 4. Query Tuning
- 4.1. SQL Server Internals
- 4.2. Data Retrieval Strategies
- 4.2.1. Unordered Clustered Index Scan or Table Scan
- 4.2.2. Unordered Covering Nonclustered Index Scan
- 4.2.3. Ordered Clustered Index Scan
- 4.2.4. Ordered Covering Nonclustered Index Scan
- 4.2.5. Nonclustered Index Seek + Range Scan + Lookups
- 4.2.6. Unordered Nonclustered Index Scan + Lookups
- 4.2.7. Clustered Index Seek + Range Scan
- 4.2.8. Covering Nonclustered Index Seek + Range Scan
- 4.3. Cardinality Estimates
- 4.4. Join Algorithms
- 4.5. Tied Rows and Sorting
- 4.6. Execution Plans Analysis
- 5. Joins
- 6. Subqueries
- 7. Table Expressions
- 8. UNION, UNION ALL, INTERSECT, and EXCEPT
- 9. Data Analysis
- 10. INSERT, DELETE, TRUNCATE, UPDATE, and MERGE
- 11. System-Versioned Temporal Tables
- 12. Transactions and Concurrency
- 13. Programmable Objects
- 14. JSON
- 15. Vectors and embeddings
- Appendix A: Data Types
- References
1. Data Integrity
SQL provides several mechanisms for enforcing data integrity:
-
PRIMARY KEYconstraint -
FOREIGN KEYconstraint with actions likeCASCADE,SET NULL,RESTRICT -
NOT NULLconstraint -
CHECKconstraint -
UNIQUEconstraint -
DEFAULTconstraint -
Triggers
-
Stored procedures
USE TSQLV6;
DROP TABLE IF EXISTS dbo.Employees;
CREATE TABLE dbo.Employees (
empid INT NOT NULL,
firstname VARCHAR(30) NOT NULL,
lastname VARCHAR(30) NOT NULL,
hiredate DATE NOT NULL,
mgrid INT NULL,
ssn VARCHAR(20) NOT NULL,
salary MONEY NOT NULL
);1.1. PRIMARY KEY
A primary key constraint enforces the uniqueness of rows and also disallows NULLs in the constraint attributes.
-
Each unique combination of values in the constraint attributes can appear only once in the table—in other words, only in one row.
-
An attempt to define a primary key constraint on a column that allows NULLs will be rejected by the RDBMS.
-
Each table can have only one primary key.
ALTER TABLE dbo.Employees
ADD CONSTRAINT PK_Employees
PRIMARY KEY (empid);To enforce the uniqueness of the logical primary key constraint, SQL Server will create a unique index behind the scenes.
-
A unique index is a physical object used by SQL Server to enforce uniqueness.
-
Indexes (not necessarily unique ones) are also used to speed up queries by avoiding sorting and unnecessary full table scans (similar to indexes in books).
1.2. UNIQUE
A unique constraint enforces the uniqueness of rows, allowing to implement the concept of alternate keys from the relational model in a database.
Unlike with primary keys, multiple unique constraints can be defined within the same table.
Also, a unique constraint is not restricted to columns defined as NOT NULL.
ALTER TABLE dbo.Employees
ADD CONSTRAINT UNQ_Employees_ssn
UNIQUE(ssn);For the purpose of enforcing a unique constraint, SQL Server handles NULLs just like non-NULL values.
-
Consequently, for example, a single-column unique constraint allows only one NULL in the constrained column.
However, the SQL standard defines NULL-handling by a unique constraint differently, like so: “A unique constraint on T is satisfied if and only if there do not exist two rows R1 and R2 of T such that R1 and R2 have the same non-NULL values in the unique columns.”
-
In other words, only the non-NULL values are compared to determine whether duplicates exist.
-
Consequently, a standard single-column unique constraint would allow multiple NULLs in the constrained column.
1.3. FOREIGN KEY
A foreign key enforces referential integrity.
-
It is defined on one or more attributes in what’s called the referencing table and points to candidate key (primary key or unique constraint) attributes in what’s called the referenced table.
-
Note that the referencing and referenced tables can be one and the same.
-
The foreign key’s purpose is to restrict the values allowed in the foreign key columns to those that exist in the referenced columns.
DROP TABLE IF EXISTS dbo.Orders;
CREATE TABLE dbo.Orders (
orderid INT NOT NULL,
empid INT NOT NULL,
custid VARCHAR(10) NOT NULL,
orderts DATETIME2 NOT NULL,
qty INT NOT NULL,
CONSTRAINT PK_Orders
PRIMARY KEY (orderid)
);-- enforce an integrity rule that restricts the values supported by the empid column in the Orders table to the values that exist in the empid column in the Employees table.
ALTER TABLE dbo.Orders
ADD CONSTRAINT FK_Orders_Employees
FOREIGN KEY(empid)
REFERENCES dbo.Employees(empid);-- restrict the values supported by the mgrid column in the Employees table to the values that exist in the empid column of the same table.
ALTER TABLE dbo.Employees
ADD CONSTRAINT FK_Employees_Employees
FOREIGN KEY(mgrid)
REFERENCES dbo.Employees(empid);| Note that NULLs are allowed in the foreign key columns (mgrid in the last example) even if there are no NULLs in the referenced candidate key columns. |
1.4. CHECK
A check constraint is used to define a predicate that a row must meet to be entered into the table or to be modified.
ALTER TABLE dbo.Employees
ADD CONSTRAINT CHK_Employees_salary
CHECK(salary > 0.00);| Note that a check constraint rejects an attempt to insert or update a row when the predicate evaluates to FALSE. The modification will be accepted when the predicate evaluates to either TRUE or UNKNOWN. |
1.5. DEFAULT
A default constraint is associated with a particular attribute.
-
It’s an expression that is used as the default value when an explicit value is not specified for the attribute when inserting a row.
ALTER TABLE dbo.Orders
ADD CONSTRAINT DFT_Orders_orderts
DEFAULT(SYSDATETIME()) FOR orderts;When done, run the following code for cleanup:
DROP TABLE IF EXISTS dbo.Orders, dbo.Employees;2. Logical Query Processing
The logical query processing in standard SQL defines how a query should be processed and the final result achieved.
(5) SELECT (5-2) DISTINCT (7) TOP(<top_specification>) (5-1) <select_list>
(1) FROM (1-J) <left_table> <join_type> JOIN <right_table> ON <on_predicate>
| (1-A) <left_table> <apply_type> APPLY <right_input_table> AS <alias>
| (1-P) <left_table> PIVOT(<pivot_specification>) AS <alias>
| (1-U) <left_table> UNPIVOT(<unpivot_specification>) AS <alias>
(2) WHERE <where_predicate>
(3) GROUP BY <group_by_specification>
(4) HAVING <having_predicate>
(6) ORDER BY <order_by_list>
(7) OFFSET <offset_specification> ROWS FETCH NEXT <fetch_specification> ROWS ONLY;-
The database engine is free to physically process a query differently by rearranging processing phases, as long as the final result would be the same as that dictated by logical query processing.
-
The database engine’s query optimizer can—and in fact, often does—apply many transformation rules and shortcuts in the physical processing of a query as part of query optimization.
USE TSQLV6;
SELECT empid, YEAR (orderdate) AS orderyear, COUNT(*) AS numorder
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR (orderdate)
HAVING COUNT(*) > 1
ORDER BY empid, orderyear;
If an identifier is irregular—for example, if it has embedded spaces or special characters, starts with a digit, or is a reserved keyword—it must be delimited. There are a couple of ways to delimit identifiers in T-SQL. One is the standard SQL form using double quotes—for example, "Order Details". Another is the T-SQL- specific form using square brackets—for example, [Order Details].
|
In most programming languages, the lines of code are processed in the order that they are written. In SQL, things are different. Even though the SELECT clause appears first in the query, it is logically processed almost last. The clauses are logically processed in the following order:
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
ORDER BY empid, orderyear
FROM → WHERE → GROUP BY → HAVING → SELECT → Expressions → DISTINCT → ORDER BY → TOP/OFFSET-FETCH
|
2.1. FROM
The FROM clause is the very first query clause that is logically processed, which is used to specify the names of the tables to query and table operators that operate on those tables.
FROM Sales.Orders2.2. WHERE
In the WHERE clause, a predicate, or logical expression is specified to filter the rows returned by the FROM phase.
FROM Sales.Orders
WHERE custid = 71
T-SQL uses three-valued predicate logic, where logical expressions can evaluate to TRUE, FALSE, or UNKNOWN. With three-valued logic, saying “returns TRUE” is not the same as saying “does not return FALSE.” The WHERE phase returns rows for which the logical expression evaluates to TRUE, and it doesn’t return rows for which the logical expression evaluates to FALSE or UNKNOWN.
|
2.3. GROUP BY
The GROUP BY phase is used to arrange the rows returned by the previous logical query processing phase in groups determined by the elements, or expressions.
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate)-
If the query is a grouped query, all phases subsequent to the
GROUP BYphase— includingHAVING,SELECT, andORDER BY—operate on groups as opposed to operating on individual rows. -
Each group is ultimately represented by a single row in the final result of the query.
-
All expressions specified in clauses that are processed in phases subsequent to the
GROUP BYphase are required to guarantee returning a scalar (single value) per group.SELECT empid, YEAR(orderdate) AS orderyear, freight -- sum(freight) AS totalfreight FROM Sales.Orders WHERE custid = 71 GROUP BY empid, YEAR(orderdate);Msg 8120, Level 16, State 1, Line 1 Column 'Sales.Orders.freight' is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause. Total execution time: 00:00:00.016-
Expressions based on elements that participate in the
GROUP BYclause meet the requirement because, by definition, each such element represents a distinct value per group. -
Elements that do not participate in the
GROUP BYclause are allowed only as inputs to an aggregate function such asCOUNT,SUM,AVG,MIN, orMAX.-
Note that all aggregate functions that are applied to an input expression ignore NULLs.
The
COUNT(*)function isn’t applied to any input expression; it just counts rows irrespective of what those rows contain.-
For example, consider a group of five rows with the values
30, 10, NULL, 10, 10in a column calledqty. -
The expression
COUNT(*)returns5because there are five rows in the group, whereasCOUNT(qty)returns4because there are four known (non-NULL) values.
-
-
To handle only distinct (unique) occurrences of known values, specify the
DISTINCTkeyword before the input expression to the aggregate function, likeCOUNT(DISTINCT qty),AVG(DISTINCT qty)and so on.
-
-
2.4. HAVING
Whereas the WHERE clause is a row filter, the HAVING clause is a group filter.
-
Only groups for which the
HAVINGpredicate evaluates toTRUEare returned by theHAVINGphase to the next logical query processing phase. -
Groups for which the predicate evaluates to
FALSEorUNKNOWNare discarded. -
The
HAVINGclause is processed after the rows have been grouped, so aggregate functions can be referred to in theHAVINGfilter predicate.SELECT empid, YEAR(orderdate) AS orderyear, SUM(freight) AS totalfreight FROM Sales.Orders WHERE custid = 71 GROUP BY empid, YEAR(orderdate) -- filters only groups (employee and order year) with more than one row, and total freight with more than 500.0 HAVING COUNT(*) > 1 AND SUM(freight) > 500.0 ORDER BY empid, YEAR(orderdate)1 2021 711.13 2 2022 672.16 4 2022 651.83 6 2021 628.31 7 2022 1231.56
2.5. SELECT
The SELECT clause is where to specify the attributes (columns) to return in the result table of the query.
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1-
The
SELECTclause is processed after theFROM,WHERE,GROUP BY, andHAVINGclauses, which means that aliases assigned to expressions in theSELECTclause do not exist as far as clauses that are processed before theSELECTclause are concerned.It’s a typical mistake to try and refer to expression aliases in clauses that are processed before the SELECT clause, such as in the following example in which the attempt is made in the WHERE clause:
SELECT orderid, YEAR(orderdate) AS orderyear FROM Sales.Orders WHERE orderyear > 2021;Msg 207, Level 16, State 1, Line 3 Invalid column name 'orderyear'.One way around this problem is to repeat the expression
YEAR(orderdate)in both theWHEREandSELECTclauses:SELECT orderid, YEAR(orderdate) AS orderyear FROM Sales.Orders WHERE YEAR(orderdate) > 2021;
In addition to supporting the AS clause, T-SQL supports the form <expression> AS <alias>, and also supports the forms <alias> = <expression> (“alias equals expression”) and <expression> <alias> (“expression space alias”).
|
|
In relational theory, a relational expression is applied to one or more input relations using operators from relational algebra, and returns a relation as output, that is, a relation in SQL is a table, and a relational expression in SQL is a table expression. |
|
Recall that a relation’s body is a set of tuples, and a set has no duplicates. Unlike relational theory, which is based on mathematical set theory, SQL is based on multiset theory.
|
2.6. ORDER BY
In terms of logical query processing, ORDER BY comes after SELECT.
-
With T-SQL, elements can also be specified in the
ORDER BYclause that do not appear in theSELECTclause, meaning to sort by something that don’t necessarily want to be returned.SELECT empid, firstname, lastname, country FROM HR.Employees ORDER BY hiredate;SELECT empid, firstname, lastname, country FROM HR.Employees ORDER BY CASE country WHEN 'USA' THEN 1 WHEN 'CHN' THEN 2 WHEN 'JPN' THEN 3 WHEN 'DEU' THEN 4 WHEN 'CAN' THEN 5 WHEN 'KOR' THEN 6 ELSE 7 END, empid; -- tie-breaker -
However, when the
DISTINCTclause is specified, theORDER BYare restricted to list only elements that appear in theSELECTlist.SELECT DISTINCT empid, firstname, lastname, country FROM HR.Employees ORDER BY hiredate;Msg 145, Level 15, State 1, Line 1 ORDER BY items must appear in the select list if SELECT DISTINCT is specified. -
ASCis the default sort order.NULLvalues are treated as the lowest possible values.
|
One of the most important points to understand about SQL is that a table—be it an existing table in the database or a table result returned by a query—has no guaranteed order. That’s because a table is supposed to represent a set of rows (or multiset, if it has duplicates), and a set has no order.
|
2.7. TOP
The TOP filter is a proprietary T-SQL feature that can be used to limit the number or percentage of rows queried returns. It relies on two elements as part of its specification: one is the number or percent of rows to return, and the other is the ordering.
SELECT TOP (5)
orderid, orderdate, custid, empid
FROM Sales.Orders
ORDER BY orderdate DESC;
Note that the TOP filter is handled after DISTINCT.
|
The TOP can use option with the PERCENT keyword, in which case SQL Server calculates the number of rows to return based on a percentage of the number of qualifying rows, rounded up.
SELECT TOP (1) PERCENT
orderid, orderdate, custid, empid
FROM Sales.Orders
ORDER BY orderdate DESC;The query returns nine rows because the Orders table has 830 rows, and 1 percent of 830, rounded up, is 9.
11074 2022-05-06 73 7
11075 2022-05-06 68 8
11076 2022-05-06 9 4
11077 2022-05-06 65 1
11070 2022-05-05 44 2
11071 2022-05-05 46 1
11072 2022-05-05 20 4
11073 2022-05-05 58 2
11067 2022-05-04 17 1In the above query, notice that the ORDER BY list is not unique (because no primary key or unique constraint is defined on the orderdate column).
-
In other words, the ordering is not strict total ordering. Multiple rows can have the same order date.
-
In such a case, the ordering among rows with the same order date is undefined, which makes the query nondeterministic—more than one result can be considered correct.
-
In case of ties, SQL Server filters rows based on optimization choices and physical access order.
-
Note that when using the TOP filter in a query without an
ORDER BYclause, the ordering is completely undefined—SQL Server returns whichevernrows it happens to physically access first, wherenis the requested number of rows. -
To make the query be deterministic, a strict total ordering is needed; in other words, add a tie-breaker.
SELECT TOP (5) orderid, orderdate, custid, empid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC; -- the row with the greater order ID value will be preferred.11077 2022-05-06 65 1 11076 2022-05-06 9 4 11075 2022-05-06 68 8 11074 2022-05-06 73 7 11073 2022-05-05 58 2 -
Instead of adding a tie-breaker to the
ORDER BYlist, a request can be made to return all ties by adding theWITH TIESoption.SELECT TOP (5) WITH TIES orderid, orderdate, custid, empid FROM Sales.Orders ORDER BY orderdate DESC;-
SQL Server first returned the
TOP (5)rows based onorderdateDESCordering, and it also returned all other rows from the table that had the same orderdate value as in the last of the five rows that were accessed. -
Using the
WITH TIESoption, the selection of rows is deterministic, but the presentation order among rows with the same order date isn’t.11077 2022-05-06 65 1 11076 2022-05-06 9 4 11075 2022-05-06 68 8 11074 2022-05-06 73 7 11073 2022-05-05 58 2 11072 2022-05-05 20 4 11071 2022-05-05 46 1 11070 2022-05-05 44 2
-
The TOP filter is very useful, but it has two shortcomings—it’s not standard, and it doesn’t support a skipping capability.
|
2.8. OFFSET-FETCH
T-SQL also supports a standard, TOP-like filter, called OFFSET-FETCH, which does support a skipping option, which makes it very useful for paging purposes.
According to the SQL standard, the OFFSET-FETCH filter is considered an extension to the ORDER BY clause. With the OFFSET clause indicates how many rows to skip, and with the FETCH clause indicates how many rows to filter after the skipped rows.
SELECT orderid, orderdate, custid, empid
FROM Sales.Orders
ORDER BY orderdate, orderid
OFFSET 50 ROWS FETCH NEXT 25 ROWS ONLY;
-- OFFSET 50 ROWS;
-- OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY;
Note that a query that uses OFFSET-FETCH must have an ORDER BY clause. Also, contrary to the SQL standard, T-SQL doesn’t support the FETCH clause without the OFFSET clause. However, OFFSET without FETCH is allowed to skip the indicated number of rows and returns all remaining rows in the result.
|
In the syntax for the OFFSET- FETCH filter, the singular and plural forms ROW and ROWS, and the forms FIRST and NEXT are interchangeable to phrase the filter in an intuitive, English-like manner.
=== OVER
|
A window function is a function that, for each row in the underlying query, operates on a window (set) defined with an OVER clause of rows that is derived from the underlying query result, and computes a scalar (single) result value.
SELECT orderid, custid, freight,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY freight) AS rownum
FROM Sales.Orders
ORDER BY custid, freight;-
For each row in the underlying query, the
OVERclause exposes to the function a subset of the rows from the underlying query’s result set. -
The
OVERclause can restrict the rows in the window by using an optional window partition clause (PARTITION BY). -
It can define ordering for the calculation (if relevant) using a window order clause (
ORDER BY)—not to be confused with the query’s presentationORDER BYclause.
| Window functions are defined by the SQL standard, and T-SQL supports a subset of the features from the standard. |
2.9. CASE
A CASE expression, based on the SQL standard, is a scalar expression that returns a value based on conditional logic.
Note that CASE is an (scalar) expression and not a statement; that is, it returns a value and it is allowed wherever scalar expressions are allowed, such as in the SELECT, WHERE, HAVING, and ORDER BY clauses and in CHECK constraints.
|
There are two forms of CASE expressions: simple and searched.
-
The simple CASE expression has a single test value or expression right after the
CASEkeyword that is compared with a list of possible values or expressions, in theWHENclauses.-
If no value in the list is equal to the tested value, the
CASEexpression returns the value that appears in theELSEclause (orNULLif anELSEclause is not present).SELECT supplierid, COUNT(*) AS numproducts, CASE COUNT(*) % 2 WHEN 0 THEN 'Even' WHEN 1 THEN 'Odd' ELSE 'Unknown' END AS countparity FROM Production.Products GROUP BY supplierid;
-
-
The searched CASE expression returns the value in the
THENclause that is associated with the firstWHENpredicate that evaluates toTRUE.-
If none of the
WHENpredicates evaluates toTRUE, theCASEexpression returns the value that appears in theELSEclause (orNULLif anELSEclause is not present).SELECT orderid, custid, freight, CASE WHEN freight < 1000.00 THEN 'Less than 1000' WHEN freight <= 3000.00 THEN 'Between 1000 and 3000' WHEN freight > 3000.00 THEN 'More than 3000' ELSE 'Unknown' END AS valuecategory FROM Sales.Orders;
-
3. Predicates and Operators
T-SQL has language elements in which predicates can be specified—for example, query filters such as WHERE and HAVING, the JOIN operator’s ON clause, CHECK constraints, and others.
T-SQL uses three-valued predicate logic, where logical expressions can evaluate to TRUE, FALSE, or UNKNOWN.
|
3.1. Predicates: IN, BETWEEN, LIKE, EXISTS, and IS NULL
-
The
INpredicate is used to check whether a value, or scalar expression, is equal to at least one of the elements in a set.SELECT orderid, empid, orderdate FROM Sales.Orders WHERE orderid IN(10248, 10249, 10250); -
The
BETWEENpredicate is used to to check whether a value falls within a specified range, INCLUSIVE of the two delimiters of the range.SELECT orderid, empid, orderdate FROM Sales.Orders WHERE orderid BETWEEN 10300 AND 10310; -
The
LIKEpredicate is used to check whether a character string value meets a specified pattern.SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE N'D%';Notice the use of the letter Nto prefix the string'D%';it stands for National and is used to denote that a character string is of a Unicode data type (NCHARorNVARCHAR), as opposed to a regular character data type (CHARorVARCHAR). -
The
EXISTSorNOT EXISTSpredicate is used to test for the presence or absence of rows in a subquery.SELECT custid, companyname FROM Sales.Customers AS C WHERE EXISTS (SELECT * FROM Sales.Orders AS O WHERE O.custid = C.custid); -
The
IS NULLand its oppositeIS NOT NULLpredicates are used to test forNULLvalues.SELECT empid, firstname, lastname, mgrid FROM HR.Employees WHERE mgrid IS NULL;
3.2. Three-Valued Logic (3VL)
SQL uses three-valued logic (3VL), where expressions can evaluate to one of three states: TRUE, FALSE, or NULL (also called UNKNOWN). It is critical to understand that WHERE and HAVING clauses only accept rows where the condition is TRUE, discarding rows that are FALSE or NULL.
The logical operators AND, OR, and NOT behave as follows:
-
NOTOperator:-
NOT TRUEresults inFALSE. -
NOT FALSEresults inTRUE. -
NOT NULLresults inNULL.
-
-
ANDOperator (Pessimistic): It returnsTRUEonly if both sides areTRUE. It is pessimistic because if one side isFALSE, the result isFALSE, even if the other side isNULL.-
TRUE AND NULLresults inNULL. -
FALSE AND NULLresults inFALSE. -
NULL AND NULLresults inNULL.
-
-
OROperator (Optimistic): It returnsTRUEif either side isTRUE. It is optimistic because if one side isTRUE, the result isTRUE, even if the other side isNULL.-
TRUE OR NULLresults inTRUE. -
FALSE OR NULLresults inNULL. -
NULL OR NULLresults inNULL.
-
3.3. Equality and Distinctness
In SQL, the way NULL values are compared depends on the context, leading to two different types of comparison logic:
-
Equality-based Comparison is the standard comparison used in predicates like
WHEREandJOIN ON. It treatsNULLas an unknown value. Because one unknown cannot be said to be equal to another, the expressionNULL = NULLevaluates toUNKNOWN, notTRUE. -
Distinctness-based Comparison is used by operators that need to group rows or find duplicates, such as
GROUP BY,UNION,INTERSECT, andEXCEPT. For these operations, twoNULLvalues are treated as not distinct from each other (i.e., they are considered identical) which ensures that rows withNULLvalues in the same columns are correctly identified as duplicates.The formal SQL standard predicate for this logic is IS [NOT] DISTINCT FROM. It provides a way to compare values while treating twoNULLvalues as equivalent. For example,NULL IS NOT DISTINCT FROM NULLevaluates toTRUE. It is important to note that T-SQL does not support this predicate, even though its set operators use the underlying distinctness logic.
3.4. Comparison Operators: =, >, <, >=, <=, <>, and ALL, SOME, ANY
-
T-SQL supports the comparison operators:
=,>,<,>=,<=,<>,!=,!>, and!<, of which the last three are not standard and should be avoided using.SELECT orderid, empid, orderdate FROM Sales.Orders WHERE orderdate >= '20220101'; -
The
<>(not equal) operator is used to check whether a value is not equal to another value.SELECT orderid, empid, orderdate FROM Sales.Orders WHERE orderdate <> '20220101'; -
The
ALLkeyword is used with a comparison operator to compare a scalar value with every value in a list or result set returned by a subquery. The condition isTRUEif the comparison isTRUEfor all values in the list.-- Example: Find products whose list price is greater than ALL list prices in the 'Road Bikes' category. SELECT Name, ListPrice FROM Production.Product WHERE ListPrice > ALL (SELECT ListPrice FROM Production.Product WHERE ProductSubcategoryID = 1); -
The
SOMEorANYkeyword (they are synonyms) is used with a comparison operator to compare a scalar value with any value in a list or result set returned by a subquery. The condition isTRUEif the comparison isTRUEfor at least one value in the list.-- Example: Find products whose list price is greater than SOME list prices in the 'Mountain Bikes' category. SELECT Name, ListPrice FROM Production.Product WHERE ListPrice > SOME (SELECT ListPrice FROM Production.Product WHERE ProductSubcategoryID = 2);It’s important to distinguish between
NOT INand<> ANY:-
NOT INmeans "not equal to value A AND not equal to value B AND not equal to value C…" -
<> ANYmeans "not equal to value A OR not equal to value B OR not equal to value C…"
For example, if a subquery returns
(1, 2, 3):-
value NOT IN (1, 2, 3)is true ifvalueis not 1 AND not 2 AND not 3. -
value <> ANY (1, 2, 3)is true ifvalueis not 1 OR not 2 OR not 3.
-
3.5. Logical Operators: OR, AND, and NOT
-
The logical operators
OR,AND, andNOTare used to combine logical expressions.SELECT orderid, empid, orderdate FROM Sales.Orders WHERE orderdate >= '20220101' AND empid NOT IN(1, 3, 5);
3.6. Arithmetic Operators: +, -, *, /, and %
-
T-SQL supports the four obvious arithmetic operators:
+,-,*, and/, and also supports the%operator (modulo), which returns the remainder of integer division.SELECT orderid, productid, qty, unitprice, discount, qty * unitprice * (1 - discount) AS val FROM Sales.OrderDetails;Note that the data type of a scalar expression involving two operands is determined in T-SQL by the operand with the higher data-type precedence.
-
If both operands are of the same data type, the result of the expression is of the same data type as well.
-
If the two operands are of different types, the one with the lower precedence is promoted to the one that is higher.
WITH Numbers AS ( SELECT 5 AS IntValue, 2 AS IntDivisor, 5.0 AS FloatValue ) SELECT IntValue / IntDivisor AS IntegerDivisionResult, -- Integer division CAST(IntValue AS NUMERIC(12, 2)) / CAST(IntDivisor AS NUMERIC(12, 2)) AS DecimalDivisionResult, -- Decimal division with casting FloatValue / IntDivisor AS DecimalDivisionFromFloatResult -- Division with a float FROM Numbers;
-
|
The
|
4. Query Tuning
-
To simulate a cold cache scenario for query performance measurement, run a manual checkpoint to write dirty buffers to disk and then drop all clean buffers from cache.
CHECKPOINT; DBCC DROPCLEANBUFFERS;DBCC DROPCLEANBUFFERSshould only be used isolated test environments as it can severely impact server performance. -
To see the estimated plan in SSMS/ADS, highlight the query and clicking the
Display Estimated Execution Plan(Ctrl+L) button on the SQL Editor toolbar. -
To see the actual plan, enable the
Include Actual Execution Plan(Ctrl+M) button and click theExecutebutton (Alt+X) to execute the query with runtime details like actual rows and executions per operator. -
To get execution plans in XML format, use
SET STATISTICS XML ON(actual plan with execution) orSET SHOWPLAN_XML ON(estimated plan without execution). -
To get execution plans in text/tabular format, use
SET STATISTICS PROFILE ON(actual plan with execution) orSET SHOWPLAN_ALL ON(estimated plan without execution).Rows Executes StmtText StmtId NodeId Parent PhysicalOp LogicalOp 1 1 select count(*) from TableName 1 1 0 NULL NULL 0 0 |--Compute Scalar(DEFINE:([Expr1003]=CONVERT_IMPLICIT(int,[Expr1004],0))) 1 2 1 Compute Scalar Compute Scalar 1 1 |--Stream Aggregate(DEFINE:([Expr1004]=Count(*))) 1 3 2 Stream Aggregate Aggregate 12366 1 |--Index Scan(OBJECT:([DatabaseName].[dbo].[TableName].[IX_TableName_Id])) 1 4 3 Index Scan Index Scan -
To get query performance statistics, use
SET STATISTICS IO, TIME ONfor I/O and time information.(1 row affected) Table 'Table1'. Scan count 1, logical reads 81, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (4 rows affected) SQL Server Execution Times: CPU time = 0 ms, elapsed time = 2 ms.
4.1. SQL Server Internals
A page is an 8-KB unit where SQL Server stores data. With disk-based tables, the page is the smallest I/O unit that SQL Server can read or write. An extent is a unit that contains eight contiguous pages.
-
A table can be organized in one of two ways—either as a heap or as a B- tree (HOBT), technically as a B-tree when it has a clustered index defined on it and as a heap when it doesn’t.
-
A heap is a table that has no clustered index, which means that the data is laid out as a bunch of pages and extents without any order.
-
SQL Server maps the data that belongs to a heap using one or more bitmap pages called index allocation maps (IAMs).
-
An allocation order scan is a heap scan that uses IAM pages to determine which pages and extents belong to the heap and reads them in physical file order, typically resulting in sequential reads when data is not cached.
-
4.1.1. Indexes
-
Indexes on SQL Server disk-based tables are B-trees (a special case of balanced trees), and their leaf level has a doubly linked list, enabling forward and backward scans of the leaf-level index records (entries).
-
A clustered index is structured as a B-tree, and it maintains the entire table’s data, not a copy, in its leaf level.
-
At the leaf level of the clustered index, the physical order in which data pages are stored on disk may not correspond to the sorted logical order of the index keys due to page splits.
-
If page
xpoints to next pagey, and pageyappears before pagexin the file, pageyis considered an out-of-order page.
-
-
A nonclustered index is also structured as a B-tree, in contrast to a clustered index, a leaf row in a nonclustered index contains only the index key columns and a row locator value representing a particular data row.
-
With the nonclustered index seek or range scan, it is more efficient because because leaf rows store only the key columns and a row locator, so more rows fit per page and fewer pages are read.
If the nonclustered index is covering (e.g., via INCLUDE), leaf rows are wider, but avoiding lookups can still reduce total I/O. -
When using multiple predicates, the order of key columns in a nonclustered index is crucial for performance, as it determines whether qualifying rows are stored contiguously in the index leaf, maximizing seeks and minimizing scans.
-
When have multiple equality predicates, place the columns from the predicates in any order in the index key list.
-
When have at most one range predicate, place the columns from the equality predicates first in the key list and the column from the range predicate last.
-
When have multiple range predicates, place the column from the most selective range predicate before the columns from the remaining range predicates.
-
-
-
An index scan is a scan performed on the leaf level of a B-tree index in the sorted order of the index key, using a doubly linked list for inter-page navigation and a row-offset array for intra-page order, supporting both full ordered scans and range scans.
-
An index scan is necessary when the query filters on a non-leading column of the index key to scan a larger portion of the index (or even the entire index) to find the matching entries.
-
-
An index seek is performed when SQL Server needs to find a certain key or range of keys at the leaf level of the index, then scanning forward or backward within that range.
-
An index seek is possible when the query filters on the leading column (or a prefix of the leading columns) of the index key to navigate the B-tree from the root node down to the specific leaf page(s) containing the matching values.
-
-
In SQL Server, the direction of key columns can be indicated in an index definition (ascending by default).
CREATE UNIQUE NONCLUSTERED INDEX [idx] ON [schema1].[Table1] ( [col1], -- same as [col1] ASC [col2] DESC )-
The storage engine currently processes parallel scans only in the forward direction; backward scans are processed serially.
-
If parallelism is a critical factor in the performance of the query, arrange a descending index.
-
-
A filtered index is an index on a subset of rows from the underlying table defined based on a predicate.
CREATE NONCLUSTERED INDEX idx_USA_orderdate ON Sales.Orders(orderdate) INCLUDE(orderid, custid, requireddate) WHERE shipcountry = N'USA'; -
A covering index is an index that contains all the columns required by the query, avoiding lookups to the base table.
-
A clustered index is a covering index because the leaf row is the complete data row.
-
A nonclustered index can be a covering index with an
INCLUDEclause listing all non-key columns required by the query.CREATE INDEX idx_nc_cid_i_oid_eid_sid_od_flr ON dbo.Orders(custid) INCLUDE(orderid, empid, shipperid, orderdate, filler);
-
-
A columnstore index stores data by columns rather than by rows, which leads to substantial performance advantages for analytical queries.
-
A nonclustered columnstore index is a secondary index created on an existing table that is stored in the traditional rowstore format.
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_nc_cs ON dbo.Fact(key1, key2, key3, measure1, measure2, measure3, measure4); -
A clustered columnstore index is the primary storage for the table, with data physically stored in columnstore format.
CREATE CLUSTERED COLUMNSTORE INDEX idx_cl_cs ON dbo.FactCS;
-
|
A general and highly recommended common naming convention format is: For indexes on multiple columns, separate the column names with underscores, and avoid listing
|
4.1.2. Execution Plans
In SQL Server, the relational engine, like a brain including the optimizer, produces execution plans for queries, while the storage engine, like muscles, carries out these instructions, sometimes choosing the best of several options based on performance and consistency.
-
When the plan shows a table scan operator, the storage engine has only one option: to use an allocation order scan.
-
When the plan shows an ordered index scan operator (clustered or nonclustered), the storage engine can use only an index order scan.
-
When the plan shows an unordered index scan operator, the storage engine has two options to scan the data: allocation order scan and index order scan.
-
An allocation order scan can return multiple occurrences of rows and skip rows resulting from splits that take place during the scan.
-
The storage engine opts for this option when the index size is greater than 64 pages and the request is running under the Read Uncommitted isolation level.
-
When the query is running under the default Read Committed isolation level or higher, the storage engine will opt for an index order scan to prevent such phenomena from happening because of splits.
-
-
An index order scan is safer in the sense that it won’t read multiple occurrences of the same row or skip rows because of splits.
-
If an index key is modified after the row was read by an index order scan and the row is moved to a point in the leaf that the scan hasn’t reached yet, the scan will read the row a second time or never reach that row.
-
It can happen in Read Uncommitted, Read Committed, and even Repeatable Read because the update was done to a row that was not yet read, but cannot happen under the isolation levels Serializable, Read Committed Snapshot, and Snapshot.
-
-
4.1.3. Cardinality Estimates
A query optimizer, the main component in the relational engine (also known as the query processor), is responsible for generating physical execution plans for the queries.
A cardinality estimator, that makes cardinality estimates of the number of rows returned by each operator, is employed by the optimizer to make decisions about access methods, join and aggregation algorithms, and memory allocation for sort and hash operations.
-
It is not a simple task to make accurate cardinality estimations without actually running the query and without a time machine.
-
Underestimations will tend to result in the following (not an exhaustive list):
-
For filters, preferring an index seek and lookups to a scan.
-
For aggregates, joins, and distinct, preferring order-based algorithms to hash-based ones.
-
For sort and hash operations, there might be spills to tempdb as a result of an insufficient memory grant.
-
Preferring a serial plan over a parallel one.
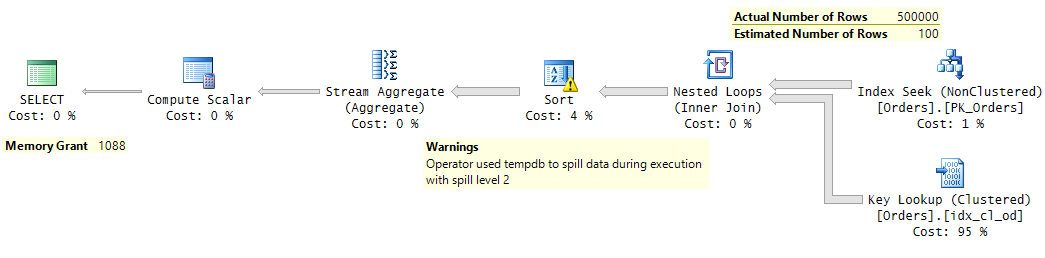 Figure 1. Plan with underestimated cardinality
Figure 1. Plan with underestimated cardinality
-
-
Overestimations will tend to result in pretty much the inverse of underestimations (again, not an exhaustive list):
-
For filters, preferring a scan to an index seek and lookups.
-
For aggregates, joins, and distinct, preferring hash-based algorithms to order-based ones.
-
For sort and hash operations, there won’t be spills, but very likely there will be a larger memory grant than needed, resulting in wasting memory.
-
Preferring a parallel plan over a serial one.
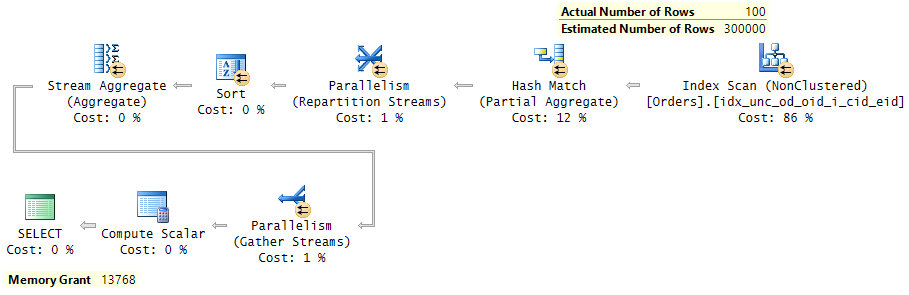 Figure 2. Plan with overestimated cardinality
Figure 2. Plan with overestimated cardinality
-
-
-
SQL Server relies on statistics about the data in its cardinality estimates.
-
Whenever creating an index, SQL Server creates statistics using a full scan of the data.
-
When additional statistics are needed, SQL Server might create them automatically using a sampled percentage of the data.
-
SQL Server creates three main types of statistics: header, density vectors, and a histogram.
-
4.1.4. Parallel Query Execution
Parallel query execution (intraquery parallelism or parallelism) uses multiple processor cores to simultaneously process smaller chunks of data, leveraging modern hardware’s increased computing power for efficient large-data processing.
Parallel processing, splitting work across multiple processor cores, can be implemented using two main models:
-
a factory-line model (where each core performs a single action on data passed between cores) and
-
a stream-based model (where each core processes a subset of data through all required operations).
While the factory-line model might seem intuitively better for human tasks, database systems like SQL Server use stream-based models.
-
Processors can efficiently switch between tasks as long as data is in local cache, and minimizing data movement between memory and storage is crucial for performance.
-
Stream-based models can scale much better than factory-line models with large datasets, distributing rows across cores as evenly as possible using various algorithms for parallel execution of all operations on each subset of data.
A query plan will be either entirely serial—processed using a single worker thread—or it will include one or more parallel branches, which are areas of the plan that are processed using multiple threads.
-
The query processor can merge parallel streams into a single stream or create parallel streams from a single stream, resulting in plans with interleaved serial and parallel zones.
-
All parallel zones in a plan use the same number of threads, known as the degree of parallelism (DOP), determined by server settings, hints, and runtime conditions.
-
A given set of threads might be reused by multiple zones over the course of the plan.
-
Parallel operators in the execution plan are marked with a circle icon with two arrows.
-
Within a parallel zone, each thread processes a unique stream of rows before passing them to the next zone (serial or parallel).
Parallel query plans rely on the Exchange (displayed as Parallelism) operator, which manages worker threads and data streams.
-
Each SQL Server query plan operator has, internally, two logical interfaces: a consumer interface, which takes rows from upstream, and a producer interface, which passes rows downstream.
-
While most operators handle their consumer and producer interfaces on the same thread and process single row streams, Exchange operators involve multiple threads and handle multiple streams, keeping other operators unaware of the parallelism.
-
The number of threads on each side of the exchange depends on the type of exchange:
A query plan can be read right-to-left (data flow) or left-to-right (operator logic). -
Gather Streams operators will have DOP threads on the consumer side and one thread on the producer side.
-
From a data-flow perspective, it merges multiple parallel streams into a single serial stream, marking the end of a parallel zone.
-
From an operator-logic perspective, it starts a parallel zone by invoking parallel worker threads.
-
-
Distribute Streams operators will have one thread on the consumer side and DOP threads on the producer side.
-
From a data-flow perspective, it splits a serial stream into multiple parallel streams, marking the start of a parallel zone.
-
From an operator-logic perspective, it marks the end of a parallel zone.
-
-
Repartition Streams operators will have DOP threads on each side of the exchange.
-
From both data-flow and operator-logic perspectives, it redistributes rows from multiple parallel streams onto different threads based on a new scheme, effectively joining two adjacent parallel zones.
-
-
Parallel query plans use five row distribution strategies across threads on the producer side of Distribute or Repartition exchanges:
-
Hash: Assigns rows to threads based on a hash function, grouping rows with the same hashed value on the same thread (e.g., grouping by ProductID for aggregation).
-
Round Robin: Distributes rows sequentially to each thread in a rotating fashion, often used outside Nested Loops where each row represents independent work.
-
Broadcast: Sends all rows to all threads, used for small row counts when all threads need the complete dataset (e.g., building a hash table).
-
Demand: Producer-side threads receive rows on request, currently used only with aligned partitioned tables.
-
Range: Assigns unique, non-overlapping key ranges to each thread, used only for index building.
4.2. Data Retrieval Strategies
SQL Server query optimizer uses various strategies to determine how the storage engine physically retrieves data from tables and indexes. Understanding these strategies, such as table scans, index seeks, and lookups, is crucial for diagnosing query performance and optimizing data access paths.
4.2.1. Unordered Clustered Index Scan or Table Scan
A table scan or an unordered clustered index scan involves a scan of all data pages that belong to the table.
-
Full table scans occur primarily in two cases: when all rows are required or when need only a subset of the rows but don’t have a good index to support the filter.
-
When the underlying table is a heap, the plan will show an operator called Table Scan.
SELECT * INTO dbo.Orders2 FROM dbo.Orders; ALTER TABLE dbo.Orders2 ADD CONSTRAINT PK_Orders2 PRIMARY KEY NONCLUSTERED (orderid); GO -- table scan SELECT orderid, custid, empid, shipperid, orderdate, filler FROM dbo.Orderss; -
When the underlying table is a B- tree, the plan will show an operator called Clustered Index Scan with an Ordered: False property.
-
The fact that the
Orderedproperty of the Clustered Index Scan operator indicatesFalsemeans that as far as the relational engine is concerned, the data does not need to be returned from the operator in key order. -
It is up to the storage engine to determine to employ allocation order scan or index order scan.
-- clustered index scan SELECT orderid, custid, empid, shipperid, orderdate, filler FROM dbo.Orders;
-
4.2.2. Unordered Covering Nonclustered Index Scan
An unordered covering nonclustered index scan is a query access method to retrieve all necessary data for a query solely from the leaf level of a nonclustered index, without accessing the base table’s data rows.
-
An unordered covering nonclustered index scan is similar to an unordered clustered index scan.
-- unordered covering nonclustered index scan SELECT orderid -- PRIMARY KEY NONCLUSTERED (orderid) FROM dbo.Orders;
4.2.3. Ordered Clustered Index Scan
An ordered clustered index scan is a full scan of the leaf level of the clustered index that guarantees that the data will be returned to the next operator in index order.
-- ordered clustered index scan
SELECT orderid, custid, empid, shipperid, orderdate, filler
FROM dbo.Orders
ORDER BY orderdate; -- CLUSTERED INDEX (orderdate)4.2.4. Ordered Covering Nonclustered Index Scan
An ordered covering nonclustered index scan is similar to an unordered covering nonclustered index scan, but retrieves data in the order of the index keys.
-- ordered covering nonclustered index scan
SELECT orderid, orderdate
FROM dbo.Orders
ORDER BY orderid; -- PRIMARY KEY NONCLUSTERED (orderid)4.2.5. Nonclustered Index Seek + Range Scan + Lookups
A nonclustered index seek + range scan + lookups access method is typically used for small-range queries or point queries using a nonclustered index that doesn’t cover the query.
-
A point query uses equality conditions (
=) to target specific values, potentially retrieving zero, one, or multiple rows, while a range query uses range operators (<,>,<=,>=,BETWEEN) to retrieve rows within a specified interval. -
While the index is capable of supporting the filter, lookups will be required to obtain the remaining columns from the respective data rows due to the index’s non-covering nature.
-
If the target table is a heap, the lookups will be RID Lookups, each costing one page read.
-- nonclustered index seek + range scan + lookups against a heap SELECT orderid, custid, empid, shipperid, orderdate, filler FROM dbo.Orders2 -- heap WHERE orderid <= 25; -- PRIMARY KEY NONCLUSTERED (orderid) -
If the underlying table is a B-tree, the lookups will be Key Lookups, each costing as many reads as the number of levels in the clustered index.
-- nonclustered index seek + range scan + lookups against a B-tree SELECT orderid, custid, empid, shipperid, orderdate, filler FROM dbo.Orders -- B-tree WHERE orderid <= 25; -- PRIMARY KEY NONCLUSTERED (orderid)
-
4.2.6. Unordered Nonclustered Index Scan + Lookups
An unordered nonclustered index scan + lookups access method is typically used by the optimizer when the following conditions are in place:
-
The query has a selective filter.
-
There’s a nonclustered index that contains the filtered column (or columns), but the index isn’t a covering one.
-
The filtered columns are not leading columns in the index key list.
-- unordered nonclustered index scan + lookups -- missing index SELECT orderid, custid, empid, shipperid, orderdate, filler FROM dbo.Orders WHERE custid = 'C0000000001'; -- NONCLUSTERED INDEX (shipperid, orderdate, custid); -
It performs a full unordered scan of the leaf level of the index, followed by lookups for qualifying keys, a strategy that becomes less efficient than a full table scan for less selective queries due to the lookup overhead.
4.2.7. Clustered Index Seek + Range Scan
A clustered index seek + range scan access method is typically used by the optimizer for range queries where the filter based on the first key column (or columns) of the clustered index.
-- clustered index seek + range scan
SELECT orderid, custid, empid, shipperid, orderdate
FROM dbo.Orders
WHERE orderdate = '20140212'; -- CLUSTERED INDEX (orderdate);4.2.8. Covering Nonclustered Index Seek + Range Scan
A covering nonclustered index seek + range scan access method is similar to the access method clustered index seek + range scan, only it uses a nonclustered covering index.
-- nonclustered index seek + range scan
SELECT orderid, shipperid, orderdate, custid
FROM dbo.Orders
WHERE shipperid = 'C'
AND orderdate >= '20140101'
AND orderdate < '20150101'; -- NONCLUSTERED INDEX (shipperid, orderdate, custid);4.3. Cardinality Estimates
In graphical execution plans, cardinality estimates are visible on arrows between operators where estimated plans display predictions only while actual plans show both estimated and actual row counts side-by-side, enabling identification of underestimation or overestimation that causes suboptimal operator choices.
Cost percentages indicate each operator’s relative expense within the query based on estimated costs where high percentages identify predicted bottlenecks, but severe underestimation can cause actual execution costs to vastly exceed estimated total query cost (such as Sort 43597 of 16 showing 272481% cost due to 2,725x underestimation causing tempdb spills), making actual row counts and execution time more reliable indicators than estimated cost percentages.
Arrow thickness is proportional to actual row count where thicker arrows indicate more rows flowing (e.g., millions) and thinner arrows indicate fewer rows (e.g., hundreds or thousands), providing a visual indicator to quickly identify high-volume data flows and validate estimated versus actual row counts.
Estimation errors exceeding 10x ratio (actual ÷ estimated) indicate critical cardinality problems requiring investigation, with underestimation causing insufficient memory grants and poor join algorithm choices (e.g., Nested Loops instead of Hash Match for large datasets), while overestimation wastes resources through excessive parallelism and oversized memory allocations.
For Nested Loops operators, estimated rows represent one execution while actual rows sum all executions, meaning Est=10 rows with Executions=100 and Actual=1000 rows indicates accuracy (10×100=1000).
4.3.1. Statistics Architecture
SQL Server relies on statistics to estimate cardinality and generate optimal execution plans, creating statistics automatically when indexes are built (via full scan) or when additional statistics are needed (via sampling), with each statistics object containing three components: header, density vector, and histogram.
The header stores metadata including total row count, sampled row count, last update timestamp, and histogram steps, providing the optimizer with high-level information about data volume and statistics freshness.
CREATE INDEX idx_nc_cid_eid ON dbo.Orders(custid, empid);
DBCC SHOW_STATISTICS(N'dbo.Orders', N'idx_nc_cid_eid');-- Header
Name Updated Rows Rows Sampled Steps Density Average key length
-------------- ------------------- -------- ------------ ----- ----------- ------------------
idx_nc_cid_eid Oct 21 2014 7:17PM 1000000 1000000 187 0.02002646 18
-- Filter Information
String Index Filter Expression Unfiltered Rows
------------ ----------------- ---------------
YES NULL 1000000
-- Density Vector
All density Average Length Columns
------------ -------------- ---------------------------
5E-05 11 custid
1.050216E-06 15 custid, empid
1.000042E-06 18 custid, empid, orderdate
-- Histogram (187 steps total, showing first 5 and last 5)
RANGE_HI_KEY RANGE_ROWS EQ_ROWS DISTINCT_RANGE_ROWS AVG_RANGE_ROWS
-------------- ---------- ------- ------------------- --------------
C0000000001 0 46 0 1
C0000000130 6437 37 128 50.28906
C0000000252 6089 37 121 50.32232
C0000000310 2918 67 57 51.19298
C0000000539 11538 62 228 50.60526
...
C0000019486 6307 66 126 50.05556
C0000019704 10934 30 217 50.3871
C0000019783 4045 66 78 51.85897
C0000019904 5906 68 120 49.21667
C0000020000 4733 46 95 49.82106The density vector provides selectivity estimates for column prefixes where each entry represents the average uniqueness (inverse of distinct count) for left-based column combinations, with lower density indicating higher selectivity and better filtering capability.
In the example above, custid has density 5E-05 (0.00005), indicating approximately 20,000 distinct customer IDs (1/0.00005), while the compound key (custid, empid) has density 1.050216E-06, indicating approximately 952,584 distinct combinations, demonstrating increasing selectivity with additional columns.
The histogram contains up to 200 steps (187 in this example) representing the distribution of values in the leading index column only, with each step defining a range boundary where RANGE_HI_KEY is the upper bound value, EQ_ROWS is the count of rows equal to that value, RANGE_ROWS is the count of rows between the previous boundary and current boundary (exclusive), DISTINCT_RANGE_ROWS is the count of distinct values in that range, and AVG_RANGE_ROWS equals RANGE_ROWS/DISTINCT_RANGE_ROWS.
The optimizer uses histogram data to estimate cardinality for predicates on the leading column where equality predicates like custid = 'C0000000539' directly use EQ_ROWS (62 rows), range predicates like custid > 'C0000000310' sum RANGE_ROWS and EQ_ROWS from qualifying steps, and predicates on non-leading columns fall back to density vector estimates, often resulting in less accurate estimations.
4.3.2. Common Estimation Problems
-
Statistics staleness occurs when modifications exceed the auto-update threshold (typically 20% of rows), causing the histogram to become outdated and produce estimates based on obsolete data distributions.
-- Table has 1,000,000 rows, auto-update threshold = 200,000 modifications -- Statistics show: ProductID 100 has 1,000 rows (0.1%) -- After 150,000 deletions of ProductID 100 (below threshold, no auto-update) SELECT * FROM Orders WHERE ProductID = 100; -- Optimizer estimates: 1,000 rows (based on stale statistics) -- Actual: 0 rows (all deleted, but statistics not updated) -
Ascending or descending key patterns introduce estimation errors when new values fall outside the histogram’s range boundaries, as the optimizer cannot accurately predict row counts for values it has never observed.
-- Statistics were last updated on 2024-12-31 -- Histogram's maximum value (last RANGE_HI_KEY) is '2024-12-31' -- Now it's 2025-01-15, and you've inserted 10,000 new orders INSERT INTO Orders (OrderDate, ...) VALUES ('2025-01-01', ...), ('2025-01-02', ...), ... ('2025-01-15', ...) -- Query for recent data SELECT * FROM Orders WHERE OrderDate >= '2025-01-10'; -- Result: Optimizer guesses ~30% of total rows (300,000 estimated) -- Actual: 5,000 rows (60x estimation error) -
Multi-column predicates without corresponding multi-column statistics force the optimizer to assume column independence, producing inaccurate estimates when columns are correlated (e.g.,
WHERE City = 'Seattle' AND State = 'WA'assumes independence when cities strongly correlate with states).-- Statistics exist only on City and State separately, not as a pair -- Reality: All Seattle rows have State='WA' (1,000 rows) SELECT * FROM Customers WHERE City = 'Seattle' AND State = 'WA'; -- Optimizer assumes independence: selectivity(City) × selectivity(State) -- Estimates: 0.01 × 0.02 × 1M = 200 rows | Actual: 1,000 rows (5x error) -
Parameter sniffing causes plan reuse problems where the first execution’s parameters produce a cached plan that performs poorly for subsequent executions with different parameter distributions, particularly when different parameter values have drastically different selectivity.
CREATE PROC GetOrders @Status VARCHAR(20) AS SELECT * FROM Orders WHERE Status = @Status; -- First execution: @Status = 'Pending' (100 rows) → generates Index Seek plan EXEC GetOrders 'Pending'; -- Fast (uses cached seek plan) -- Later execution: @Status = 'Shipped' (900,000 rows) → reuses same seek plan EXEC GetOrders 'Shipped'; -- Slow (seek+lookups instead of scan for 90% of table) -
Complex predicates involving
ORconditions, functions applied to columns (WHERE YEAR(OrderDate) = 2024), or non-SARGable expressions prevent histogram usage, forcing the optimizer to rely on less accurate density-based estimates.-- Non-SARGable: function applied to column prevents histogram lookup SELECT * FROM Orders WHERE YEAR(OrderDate) = 2024; -- Optimizer cannot use histogram on OrderDate, uses density estimate (~30%) -- SARGable alternative: uses histogram effectively SELECT * FROM Orders WHERE OrderDate >= '2024-01-01' AND OrderDate < '2025-01-01';
4.3.3. Troubleshooting and Resolution
Statistics maintenance requires proactive monitoring, timely updates with FULLSCAN, multi-column statistics for correlated columns, and dynamic thresholds via trace flag 2371.
-
Monitor statistics staleness using tiered thresholds (10%, 15%, 20%) to prioritize updates proactively, catching problems before they impact production rather than reacting after SQL Server’s 20% auto-update threshold is crossed.
-- Find statistics with tiered priority based on modification thresholds SELECT OBJECT_NAME(s.object_id) AS TableName, s.name AS StatsName, sp.last_updated, sp.rows, sp.rows_sampled, CAST(100.0 * sp.rows_sampled / NULLIF(sp.rows, 0) AS DECIMAL(10,2)) AS SamplePct, sp.modification_counter, CAST(100.0 * sp.modification_counter / NULLIF(sp.rows, 0) AS DECIMAL(10,2)) AS ModPct, CASE WHEN sp.modification_counter > sp.rows * 0.20 THEN 'Critical' WHEN sp.modification_counter > sp.rows * 0.15 THEN 'High' WHEN sp.modification_counter > sp.rows * 0.10 THEN 'Medium' ELSE 'Low' END AS Priority FROM sys.stats s CROSS APPLY sys.dm_db_stats_properties(s.object_id, s.stats_id) sp WHERE sp.modification_counter > sp.rows * 0.10 -- Proactive 10% threshold ORDER BY CASE WHEN sp.modification_counter > sp.rows * 0.20 THEN 1 WHEN sp.modification_counter > sp.rows * 0.15 THEN 2 WHEN sp.modification_counter > sp.rows * 0.10 THEN 3 ELSE 4 END, sp.modification_counter DESC;SQL Server triggers statistics updates at 20% modifications (default), but proactive monitoring at 10% provides early warning:
-
Critical (>20%) requires immediate attention as auto-update hasn’t triggered yet
-
High (15-20%) should be updated during next maintenance window
-
Medium (10-15%) can be scheduled for routine maintenance
-
Trace flag 2371 makes thresholds dynamic using
SQRT(1000 * row_count)(~5% at 1M rows, ~2% at 100M+ rows)
Auto-updates are query-triggered and synchronous by default (AUTO_UPDATE_STATISTICS_ASYNC OFF):
-
When a query hits stale statistics, SQL Server updates them before query execution, potentially blocking for seconds to minutes
-
With AUTO_UPDATE_STATISTICS_ASYNC ON, the first query uses stale statistics and returns immediately while updates run in background, avoiding blocking but risking suboptimal plans
-
Schedule manual updates during maintenance windows to avoid both blocking (sync mode) and stale-plan issues (async mode)
-- Check database-level statistics settings SELECT name AS DatabaseName, is_auto_create_stats_on AS AutoCreateStats, is_auto_update_stats_on AS AutoUpdateStats, is_auto_update_stats_async_on AS AutoUpdateStatsAsync FROM sys.databases WHERE name = DB_NAME(); -- Check if trace flag 2371 is enabled DBCC TRACESTATUS(2371);
-
-
Update statistics with
FULLSCANfor accurate distribution sampling and usePERSIST_SAMPLE_PERCENT = ONto preserve the sampling rate for future auto-updates, preventing SQL Server from downgrading to lower sampling percentages (typically 20-30%) on subsequent automatic updates.-- Full scan update with persistent sample rate UPDATE STATISTICS dbo.Orders idx_OrderDate WITH FULLSCAN, PERSIST_SAMPLE_PERCENT = ON; -- Update all statistics on a table UPDATE STATISTICS dbo.Orders WITH FULLSCAN; -
Create multi-column statistics for correlated predicates where the optimizer’s independence assumption produces inaccurate estimates, particularly for columns with strong correlations like City and State.
-- Create multi-column statistics for correlated columns CREATE STATISTICS Stats_City_State ON dbo.Customers(City, State) WITH FULLSCAN; -
Enable trace flag 2371 to use dynamic auto-update thresholds that scale with table size, replacing the fixed 20% threshold with a percentage that decreases as table size increases (e.g., 2% for tables with 100M+ rows).
-- Enable at instance level (requires restart or DBCC command) DBCC TRACEON(2371, -1); -- Add to startup parameters for persistence: -T2371
Query hints and plan guides provide tactical solutions for cardinality estimation problems.
-
Force recompilation to address parameter sniffing where cached plans become suboptimal for different parameter values.
-- Recompile on every execution SELECT * FROM Orders WHERE Status = @Status OPTION (RECOMPILE); -- Or at procedure level CREATE PROC GetOrders @Status VARCHAR(20) WITH RECOMPILE AS SELECT * FROM Orders WHERE Status = @Status; -
Optimize for specific parameter values when typical values are known and differ from the first execution’s parameters.
-- Optimize assuming 'Pending' is the most common value SELECT * FROM Orders WHERE Status = @Status OPTION (OPTIMIZE FOR (@Status = 'Pending')); -- Optimize for worst-case scenario (all possible values) OPTION (OPTIMIZE FOR (@Status UNKNOWN)); -
Switch cardinality estimation models when one produces consistently poor estimates for specific query patterns.
-- Force legacy CE (pre-SQL Server 2014) SELECT * FROM Orders WHERE ComplexFilter = @Value OPTION (USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION')); -- Alternative using trace flag OPTION (QUERYTRACEON 9481); -
Override memory grants and parallelism when CE causes insufficient memory grants (tempdb spills) or excessive parallelism.
-- Prevent tempdb spills from underestimated memory grants SELECT * FROM LargeTable WHERE ComplexFilter = @Value OPTION (MIN_GRANT_PERCENT = 15); -- Limit parallelism when CE causes excessive core usage OPTION (MAXDOP 4); -- Combine multiple hints OPTION (RECOMPILE, MIN_GRANT_PERCENT = 10, MAXDOP 4); -
Apply hints via plan guides to avoid modifying application code in production scenarios where source code changes require lengthy deployment processes.
Query hints are tactical workarounds, not long-term solutions:
-
Use for production emergencies when immediate relief is needed without code deployment
-
Apply as temporary fixes while investigating root causes like stale statistics, missing indexes, or non-SARGable predicates
-
Consider plan guides for applying hints to unchanged application code
Trade-offs and cautions to consider:
-
Hints mask root causes rather than fixing underlying CE problems
-
OPTION (RECOMPILE)adds CPU overhead for recompilation on every execution -
Hints can become obsolete as data patterns change, requiring ongoing maintenance
-
Overrides optimizer decisions that may actually be better as data volume grows
-
Makes queries harder to maintain and understand for other developers
Best practice is using hints as temporary workarounds while fixing the underlying problems (update statistics, create proper indexes, rewrite non-SARGable predicates).
-
4.3.4. Cardinality Estimation Models
SQL Server’s CE evolved across versions with different optimization strategies:
-
Legacy CE (compatibility level 70-110) uses simpler assumptions
-
Modern CE (120+) employs improved correlation detection and exponential backoff for multiple predicates
-
CE 130 adds further refinements
The choice between models depends on workload characteristics where legacy CE may perform better for some queries while modern CE generally handles complex predicates more accurately.
4.3.5. Intelligent Query Processing
IQP features (SQL Server 2017+, compatibility level 140+) address CE limitations through runtime adaptation:
-
Adaptive joins switch join algorithms based on actual row counts during execution
-
Memory grant feedback adjusts grants between executions to prevent tempdb spills or memory waste
-
Table variable deferred compilation fixes the notorious 1-row estimate problem by deferring compilation until actual row counts are known
-
Scalar UDF inlining eliminates row-by-row function execution overhead
-
Parameter sensitivity plan optimization (SQL 2022, compatibility level 160) creates multiple cached plans for different parameter value ranges to eliminate parameter sniffing issues without requiring
OPTION (RECOMPILE)hints
4.4. Join Algorithms
The SQL Server query optimizer employs several physical join algorithms to combine rows from two input tables. The choice of algorithm is cost-based, meaning the optimizer selects the one with the lowest estimated execution cost, factoring in input size, index availability, and data sortedness.
4.4.1. Nested Loops Join
A Nested Loops join is a physical join operator that reads one row from the first (outer) input and, for that row, finds all matching rows in the second (inner) input. This process is repeated for every row in the outer input.
It is the most efficient algorithm under the following conditions:
-
The outer input table is small.
-
The inner input table is large but has a covering index on the join column.
This combination allows the optimizer to perform an efficient index seek on the inner table for each row from the outer table. While its low overhead makes it ideal for joining small data sets and for queries with highly selective predicates, its performance degrades rapidly as the number of rows in the outer input increases.
4.4.2. Hash Match Join (Hash Join)
A Hash Match join (or hash join) is highly effective for joining large, unsorted datasets and is primarily used for equi-joins. It processes data in two distinct phases:
-
Build Phase: The optimizer designates the smaller of the two inputs as the
build input. It reads these rows and constructs an in-memory hash table based on the join key. -
Probe Phase: It then reads the larger input, known as the
probe input, one row at a time. For each probe row, it computes a hash on the join key and looks for matches in the hash table created during the build phase.
The optimizer typically chooses a hash join when the inputs are large and not sorted, and when no useful indexes are available. The algorithm’s performance is heavily dependent on memory; if the build input is too large to fit in the available memory, the hash table will spill to tempdb, causing significant performance degradation.
4.4.3. Merge Join
A Merge join provides a highly efficient method for joining two inputs, provided both are already sorted on the join key. The algorithm simultaneously reads from both sorted inputs and merges the matching rows, similar to merging two sorted lists.
A merge join is optimal under these circumstances:
-
Both inputs are large.
-
Both inputs are sorted on the join column, often the result of a clustered index scan or a prior sort operation in the execution plan.
If one or both inputs are not sorted, the optimizer can add an explicit Sort operator, but this adds to the overall query cost. Consequently, a merge join is most effective when existing indexes or data structures provide pre-sorted data, making it a low-cost alternative to a hash join for large datasets. It is primarily used for equi-joins but can handle some non-equi-join scenarios.
4.4.4. Algorithm Selection
The query optimizer selects a join algorithm by estimating the I/O, CPU, and memory costs of each available strategy. This cost-based decision is influenced by several key factors, which combine to produce predictable performance patterns.
Selection Criteria:
-
The estimated number of rows (cardinality) in each input is the primary driver, with small outer inputs favoring Nested Loops while large inputs make Hash and Merge joins more attractive.
-
A useful index on the join key of the inner table makes Nested Loops highly efficient through index seeks, while clustered indexes that provide sorted data make Merge joins a strong candidate.
-
Pre-sorted data on the join key makes Merge joins the cheapest option by avoiding explicit sort operations.
-
Hash and Merge joins are designed for equi-joins (
=), whereas Nested Loops are more versatile and can handle non-equi-joins (e.g.,>,<,BETWEEN). -
Hash joins require sufficient memory for the build phase, as insufficient memory causes spills to
tempdbthat severely degrade performance.
Common Performance Patterns:
-
When the outer table is small and the inner table has a useful index, Nested Loops performs fast index seeks with minimal overhead.
-
For large, unsorted datasets, Hash joins are typically most efficient, assuming adequate memory is available to avoid spills.
-
When both inputs are large and already sorted, Merge joins provide optimal performance by avoiding both hashing overhead and repeated seeks.
-
When the optimizer’s cardinality estimates are inaccurate, it may choose a suboptimal plan (e.g., Nested Loops for large inputs), but modern SQL Server versions use Adaptive Joins to dynamically switch between Nested Loops and Hash joins during execution, mitigating this risk.
4.5. Tied Rows and Sorting
When an ORDER BY clause is used, SQL Server guarantees the result set is sorted according to the specified columns. However, this guarantee does not extend to rows with the same value in the ordering columns—known as tied rows. The order in which tied rows are returned is not guaranteed and can vary between query executions, leading to an unstable sort.
This instability occurs because the execution plan only guarantees the explicitly requested order. For tied rows, the database returns them in whatever order is most convenient for that specific execution, which can lead to unexpected behavior, particularly in pagination scenarios.
For instance, if a user is paging through a customer’s order history, an unstable sort could cause the same order to appear on multiple pages or for some orders to be skipped entirely, because the order of that customer’s orders shifted between page loads.
To ensure a consistent and predictable sort, the ORDER BY clause must uniquely identify every row, which can be achieved by adding a tie-breaker—a column or set of columns guaranteed to be unique, such as the table’s primary key.
For example, consider sorting orders by customer. A single customer can have multiple orders, creating tied rows.
-- Unstable sort: Order of rows for the same `custid` is not guaranteed.
SELECT custid, orderid, orderdate
FROM Sales.Orders
ORDER BY custid;By adding the unique orderid column as a tie-breaker, the sort becomes deterministic. A secondary sort by orderdate is also a good practice.
-- Stable sort: orderdate and orderid act as tie-breakers.
SELECT custid, orderid, orderdate
FROM Sales.Orders
ORDER BY custid, orderdate DESC, orderid DESC;This forces the optimizer to perform a secondary sort on orderdate and then orderid for any tied rows, resulting in a deterministic, or stable, sort that is consistent with every execution.
4.6. Execution Plans Analysis
In practice, the actual plan is preferred when the issue can be reproduced, Live Query Statistics are preferred for long-running queries, and estimated plans are preferred when execution is risky or not possible.
-
Actual execution plans show what happened during execution, including actual row counts, warnings, and runtime behavior.
-
Estimated plans show what the optimizer intended without running the query, and they can be misleading when estimates are wrong.
-
Live Query Statistics show operator progress and row flow while the query is still running, which helps identify where time is being spent.
Show Plan XML
<?xml version="1.0" encoding="utf-16"?> <!-- ROOT: ShowPlanXML - The complete execution plan --> <ShowPlanXML Version="1.518" Build="13.0.5865.1"> <BatchSequence> <Batch> <Statements> <!-- STATEMENT: Your SQL query's execution plan --> <StmtSimple StatementEstRows="102367" <!-- Estimated: 102K rows --> StatementOptmEarlyAbortReason="TimeOut" <!-- ⚠️ Optimizer gave up! --> StatementSubTreeCost="15.46" <!-- Total cost --> StatementType="SELECT"> <QueryPlan DegreeOfParallelism="1" <!-- Single-threaded --> MemoryGrant="52296" <!-- 51 MB granted --> CompileTime="1335"> <!-- 1.3s compile time --> <!-- MISSING INDEXES: 24% improvement possible --> <MissingIndexes> <MissingIndexGroup Impact="24.024"> <MissingIndex Table="[Orders]"> <ColumnGroup Usage="EQUALITY"> <Column Name="[orderId]" /> <!-- Add to WHERE --> </ColumnGroup> <ColumnGroup Usage="INCLUDE"> <Column Name="[status]" /> <!-- Add as INCLUDE --> </ColumnGroup> </MissingIndex> </MissingIndexGroup> </MissingIndexes> <!-- WARNINGS: Critical issues --> <Warnings> <!-- ⚠️ Implicit conversion prevents index seek --> <PlanAffectingConvert ConvertIssue="Seek Plan" Expression="CONVERT_IMPLICIT(bigint,[PricingRules].[customer_id],0)" /> </Warnings> <!-- MEMORY: Over-granted (51 MB granted, only 5 MB used) --> <MemoryGrantInfo GrantedMemory="52296" MaxUsedMemory="4680" /> <!-- WAIT STATS: Where time was spent --> <WaitStats> <Wait WaitType="ASYNC_NETWORK_IO" WaitTimeMs="4722" /> <!-- Client slow --> <Wait WaitType="IO_COMPLETION" WaitTimeMs="3002" /> <!-- Disk I/O --> <Wait WaitType="SOS_SCHEDULER_YIELD" WaitTimeMs="1610" /> <!-- CPU --> </WaitStats> <!-- TIMING: CPU 0.76s, Total 10s (9.2s waits!) --> <QueryTimeStats CpuTime="761" ElapsedTime="10042" /> <!-- ================================ --> <!-- OPERATOR TREE (data flows UP) --> <!-- ================================ --> <!-- NODE 0: Compute Scalar - Calculate final metrics --> <RelOp NodeId="0" PhysicalOp="Compute Scalar" EstimateRows="102367"> <!-- NODE 1: Nested Loops - LEFT OUTER JOIN --> <RelOp NodeId="1" PhysicalOp="Nested Loops" LogicalOp="Left Outer Join"> <!-- ⚠️ Est: 102K rows, Actual: 172 rows (bad estimate!) --> <RunTimeInformation> <RunTimeCountersPerThread ActualRows="172" ActualElapsedms="5282" /> </RunTimeInformation> <NestedLoops> <!-- OUTER: Filter on country --> <RelOp NodeId="2" PhysicalOp="Filter"> <!-- NODE 4: Hash Match - JOIN Customers + CurrencyExchange --> <RelOp NodeId="4" PhysicalOp="Hash Match" LogicalOp="Right Outer Join"> <Hash> <!-- BUILD: Scan CurrencyExchange (625 rows) --> <RelOp NodeId="5" PhysicalOp="Clustered Index Scan"> <Object Table="[CurrencyExchange]" /> </RelOp> <!-- PROBE: Main data pipeline --> <RelOp NodeId="6" PhysicalOp="Hash Match"> <!-- Seek 3 customer records --> <RelOp NodeId="8" PhysicalOp="Clustered Index Seek"> <RunTimeInformation> <RunTimeCountersPerThread ActualRows="3" ActualLogicalReads="6" /> </RunTimeInformation> <IndexScan> <Object Table="[Customers]" /> <SeekPredicates> <!-- Seeks: customerId IN (12362, 20322, 243137) --> </SeekPredicates> </IndexScan> </RelOp> <!-- Stream Aggregate: Group sales data --> <RelOp NodeId="10" PhysicalOp="Stream Aggregate"> <StreamAggregate> <GroupBy> <ColumnReference Column="customerId" /> <ColumnReference Column="orderId" /> <ColumnReference Column="categoryId" /> <ColumnReference Column="productId" /> </GroupBy> <!-- Sort: Required for Stream Aggregate --> <RelOp NodeId="11" PhysicalOp="Sort"> <!-- UNION ALL: Combine 2 data sources --> <RelOp NodeId="60" PhysicalOp="Concatenation"> <!-- Branch 1: Regular products (1746 rows) --> <RelOp NodeId="66" PhysicalOp="Clustered Index Seek"> <RunTimeInformation> <RunTimeCountersPerThread ActualRows="1816" ActualLogicalReads="383" /> </RunTimeInformation> <Object Table="[Products]" /> </RelOp> <!-- Branch 2: Featured products (0 rows) --> <RelOp NodeId="73" PhysicalOp="Index Seek"> <RunTimeInformation> <RunTimeCountersPerThread ActualRows="0" /> </RunTimeInformation> <Object Table="[SalesFactTable]" /> </RelOp> </RelOp> </RelOp> </StreamAggregate> </RelOp> </RelOp> </Hash> </RelOp> </RelOp> <!-- INNER: Lazy Spool for comparison data --> <RelOp NodeId="83" PhysicalOp="Table Spool"> <Spool> <!-- Aggregate previous period data --> <RelOp NodeId="86" PhysicalOp="Stream Aggregate"> <!-- NODE 87: SORT WITH DISK SPILL! --> <RelOp NodeId="87" PhysicalOp="Sort"> <!-- ⚠️ WORST ISSUE: Sort spilled to tempdb --> <Warnings> <SpillToTempDb SpillLevel="2" /> <SortSpillDetails WritesToTempDb="32100" <!-- 32K writes! --> ReadsFromTempDb="32100" /> <!-- 32K reads! --> </Warnings> <RunTimeInformation> <RunTimeCountersPerThread ActualRows="43597" ActualElapsedms="4589" <!-- 4.6s just for sorting! --> InputMemoryGrant="544" /> <!-- Only 544 KB (too small!) --> </RunTimeInformation> <!-- NODE 90: Index Seek - Source data --> <RelOp NodeId="90" PhysicalOp="Index Seek"> <RunTimeInformation> <RunTimeCountersPerThread ActualRows="43597" ActualRowsRead="116348" <!-- Read 117K, filtered to 44K --> ActualExecutions="71" <!-- Executed 71 times --> ActualLogicalReads="819" /> </RunTimeInformation> <IndexScan> <Object Table="[SalesFactTable]" Index="[idx_customer_date]" /> <SeekPredicates> <!-- Seek: customerId = @param --> <!-- Date range: '2021-12-31' to '2023-12-31' --> </SeekPredicates> </IndexScan> </RelOp> <!-- NODE 92: Key Lookup (Expensive!) --> <RelOp NodeId="92" PhysicalOp="Clustered Index Seek"> <RunTimeInformation> <RunTimeCountersPerThread ActualExecutions="43597" <!-- ⚠️ One per row! --> ActualLogicalReads="174388" /> <!-- 174K reads! --> </RunTimeInformation> <IndexScan Lookup="true"> <Object Table="[SalesFactTable]" IndexKind="Clustered" /> <!-- KEY LOOKUP: Gets columns missing from non-clustered index --> </IndexScan> </RelOp> </RelOp> </RelOp> </Spool> </RelOp> </NestedLoops> </RelOp> </ComputeScalar> </RelOp> </QueryPlan> </StmtSimple> </Statements> </Batch> </BatchSequence> </ShowPlanXML>
4.6.1. Reading Fundamentals
When reading a plan, keep two flows in mind: the logical flow is the direction of the query request while the physical flow is the movement of data back to the results.
-
The leftmost operator starts the process by requesting rows from its children until it reaches the base tables.
-
The rightmost operators find rows in the database files to push back toward the left where thick connecting arrows indicate a large volume of data movement.
-
The top-right input serves as the outer table while the engine executes the bottom-right inner table once for every row that it receives from the top.
4.6.2. Operator Properties
Operator properties provide the primary checklist for plan analysis because they expose estimates, runtime row counts, executions, predicates, ordering, memory usage, and warnings.
-
Logical Readsshow how many 8KB pages were read from the buffer cache, whilePhysical Readsshow how many 8KB pages were read from disk.-
High logical reads mean the query touched many pages, which can indicate low selectivity, missing indexes, or an intentionally large OLAP-style scan.
-
High physical reads mean many pages were not already in memory, which can indicate cold cache, memory pressure, or a working set larger than available memory.
-
-
Actual Number of Rowsshows how many rows were produced by the operator, whileEstimated Number of Rowsshows what the optimizer expected during compilation, and large gaps often indicate cardinality estimation issues that can drive suboptimal join, access, or memory-grant decisions-
A suboptimal join choice can happen when estimates suggest a small input and the optimizer chooses
Nested Loops, while actual rows are large and aHash MatchorMerge Joinwould be more appropriate. -
A suboptimal index access method can happen when estimates suggest high selectivity and the optimizer chooses a
Seek, while actual rows are high and theSeekplusKey Lookupsbecomes slower than aScanor a different covering index. -
A suboptimal memory grant can be too small due to underestimation and cause
tempdbspills, while it can be too large due to overestimation and waste memory that reduces concurrency. -
Estimates are based on statistics and assumptions, so stale statistics, parameter sensitivity (i.e., parameter sniffing), and skewed data distributions are common causes of big mismatches.
-
-
Estimated Operator Costindicates the optimizer cost for a single operator, whileEstimated Subtree Costindicates the cost for the operator plus its inputs. -
Number of Executionsshows how many times the operator ran, while a high value often indicates an inner operator being repeatedly invoked by aNested Loopsjoin.For
Nested Loops, inner operators are often executed once per outer row, soNumber of Executionsusually tracks the outer input’s row count. It may not match exactly when the plan stops early (for example,TOP/EXISTS) or when the inner side is reused via rewinds/spools. -
Seek Predicatesshow what was used to navigate the index, whilePredicateoften shows residual filtering applied after rows were read.-
A predicate under
Seek Predicatesdrives index navigation, while a predicate underPredicateis residual filtering applied after rows are read and is often non-SARGable. -
A SARGable predicate (Search ARGument-able) is a predicate that SQL Server can translate into index navigation, such as
WHERE OrderDate >= '20240101' AND OrderDate < '20250101',WHERE CustomerId = 123, andWHERE LastName LIKE 'Smi%'. -
A non-SARGable predicate usually forces SQL Server to read many rows before filtering, which commonly happens when functions, expressions, or type mismatches affect an indexed column, such as
WHERE YEAR(OrderDate) = 2024,WHERE UPPER(LastName) = 'SMITH',WHERE LastName LIKE '%son', and predicates that triggerCONVERT_IMPLICIT.
-
-
Orderedindicates whether the operator output preserves a useful sort order, whileOrdered = Falseoften implies an extraSortmay be required. -
Memory Grantshows how much memory the operator requested, whileUsed Memoryshows how much it actually consumed. -
Warningsindicate runtime problems such as spills or implicit conversions, while the warning tooltip or plan XML provides the specific details when available.-
Spills indicate the operator wrote work data to
tempdb(disk-based workspace) due to an insufficient memory grant (often caused by underestimated row counts). -
Implicit conversions indicate SQL Server is converting values during comparisons, which can disable index usage and lead to bad estimates.
-
4.6.3. Data Access Operators
-
Index Seeksnavigate the index B-tree to reach a specific key range, whileIndex Scanstraverse the index leaf level and apply filtering as rows are read. -
Table Scansread the entire table, which is common for heaps and can be reasonable when the query needs most rows.-
A scan is acceptable for small tables or low-selectivity predicates, since the overhead of seeking can outweigh the benefit.
-
A scan on a large table with a selective predicate often indicates a missing or unusable index, so the filter may be applied after many rows are read.
-
A heap can make
RID Lookupsmore expensive due to forwarded records, so adding an appropriate clustered index stores the table as a B-tree and makes lookups more stable.
-
-
Lookups fetch missing columns from the base table when the chosen index does not contain all required columns.
-
Key Lookupsfetch missing columns from the clustered index, whileRID Lookupsfetch missing columns from a heap. -
A covering index can eliminate lookups by adding required output columns using
INCLUDE, while missing filter or join columns may need to be added to the index key.
-
4.6.4. Join Operators
-
Nested Loopsjoin two inputs by using the outer rows to drive repeated execution of the inner input.-
The inner side runs once per outer row, so the join is most effective when the outer input is small and the inner side can use a selective index seek on the join keys.
-
Number of Executionson the inner branch and high logical reads on the inner access are common signals of an inefficientNested Loopsjoin.
-
-
Hash Matchjoins large and unsorted datasets by building a hash table for the join keys, and its behavior depends on the build and probe sides.-
The build side should be smaller, since it is used to build the hash table, while the probe side is streamed to find matches.
-
Spills allow the join to continue when the build hash table does not fit in memory, while very wide rows can still fail if a required worktable row exceeds SQL Server’s 8060-byte in-row limit (error 8618).
-
-
Merge Joinmatches rows by walking two inputs in sorted order, so its behavior depends on whether both inputs are already ordered on the join keys.-
Ordered = Trueon both sides indicates the inputs arrive sorted, while extraSortoperators indicate the join keys are not supported by an index order. -
A
Merge Joinis order-preserving for the join keys, so it can reduce or remove a separateSortwhen the query also needs ordered output. -
A
Merge Joinis often preferred when both inputs are already ordered, whileNested LoopsorHash Matchmay still be chosen when they are estimated to be cheaper. -
An
Adaptive Joinis a runtime choice betweenNested LoopsandHash Matchbased on an actual row threshold on SQL Server 2017+, rather than a new join algorithm.
-
4.6.5. Parallelism and Exchange
-
Exchangeoperators move data between multiple CPU threads to balance the workload.-
Distribute Streamssplits a single data stream into multiple threads for parallel processing. -
Gather Streamsmerges results from multiple threads into a single output for the next operator. -
Repartition Streamsmoves data between threads to ensure that the workload remains balanced. -
Thread skew occurs when one thread performs significantly more work than others, which is visible in per-thread actual row counts in the operator properties.
-
CXPACKET wait types often indicate parallel threads waiting on each other, and skewed exchange distribution is a common cause.
-
4.6.6. Aggregation and Sorting
-
Sortoperators arrange data into a required order for downstream operators or final output.-
Sorts are memory-intensive and can spill to
tempdbwhen the memory grant is insufficient. -
A
Sortindicates the plan needed a specific order forORDER BY,Merge Join, orStream Aggregate, and an index whose key order matches that requirement can sometimes eliminate theSort.
-
-
Stream Aggregatesusually implementGROUP BYorDISTINCTby aggregating rows in grouping-key order with a low-memory streaming pass.-
The input must already be ordered on the grouping keys, otherwise the plan adds a
Sortor uses aHash Aggregateinstead. -
An index that provides the grouping-key order can keep the aggregation streaming and avoid an extra Sort.
-
-
Hash Aggregatesusually implementGROUP BYorDISTINCTby building a hash table of groups without requiring ordered input.-
A large number of distinct groups increases hash table size, which can cause spills to
tempdbwhen the memory grant is insufficient. -
When the input is already ordered on the grouping keys, a
Stream Aggregatecan sometimes be more efficient.
-
5. Joins
T-SQL supports four table operators: JOIN, APPLY, PIVOT, and UNPIVOT. The JOIN operator is standard, while APPLY, PIVOT, and UNPIVOT are T-SQL extensions. Each table operator acts on input tables, applies a set of logical query processing phases, and returns a table result.
-
A
JOINtable operator operates on two input tables and has three fundamental types:-
A
CROSS JOINapplies only one phase, the Cartesian Product. -
An
INNER JOINapplies two phases, the Cartesian Product and the Filter. -
An
OUTER JOINapplies three phases, the Cartesian Product, the Filter, and the Add Outer Rows.
-
-
These phases describe the logical processing steps involved in different types of SQL joins:
-
The
Cartesian Productis the initial step where every row from the first table is combined with every row from the second table, resulting in a new table containing all possible combinations. -
A
Filteris applied after the Cartesian Product, based on theONclause of the join. Only the rows that satisfy the join condition are kept. -
Add Outer Rowsis a specific phase for outer joins (LEFT,RIGHT, orFULL) that, after filtering, includes in the result set any rows from the outer table(s) that did not find a match in the other table.-
For a
LEFT OUTER JOIN, the outer table is the left table. -
For a
RIGHT OUTER JOIN, the outer table is the right table. -
For a
FULL OUTER JOIN, both tables are considered outer tables.For these non-matching rows, columns from the table where no match was found will contain
NULLvalues.The OUTERkeyword is optional forLEFT,RIGHT, andFULLjoins (e.g.,LEFT JOINis equivalent toLEFT OUTER JOIN).
-
-
5.1. CROSS
The cross join is the simplest type of join that implements only one logical query processing phase—a Cartesian Product.
-
It operates on the two tables provided as inputs and produces a Cartesian product of the two, that is, each row from one input is matched with all rows from the other.
-- SQL-92 syntax SELECT C.custid, E.empid FROM Sales.Customers AS C CROSS JOIN HR.Employees AS E; -- SQL-89 syntax (not recommended) SELECT C.custid, E.empid FROM Sales.Customers AS C, HR.Employees AS E; -- Self cross joins SELECT E1.empid, E1.firstname, E1.lastname, E2.empid, E2.firstname, E2.lastname FROM HR.Employees AS E1 CROSS JOIN HR.Employees AS E2;DROP TABLE IF EXISTS dbo.Digits; CREATE TABLE dbo.Digits (digit INT NOT NULL PRIMARY KEY); INSERT INTO dbo.Digits(digit) VALUES (0), (1), (2), (3), (4), (5), (6), (7), (8), (9); -- Producing tables of numbers SELECT D3.digit * 100 + D2.digit * 10 + D1.digit + 1 AS n FROM dbo.Digits AS D1 CROSS JOIN dbo.Digits AS D2 CROSS JOIN dbo.Digits AS D3 ORDER BY n;1 2 3 . . . 998 999 1000
5.2. INNER
An inner join applies two logical query processing phases—it applies a Cartesian product between the two input tables like in a cross join, and then it filters rows based on a specified predicate in a designated clause called ON.
-- SQL-92 syntax
SELECT E.empid, E.firstname, E.lastname, O.orderid
FROM HR.Employees AS E
INNER JOIN Sales.Orders AS O
ON E.empid = O.empid;
-- Note that the SQL-89 syntax has no ON clause.
SELECT E.empid, E.firstname, E.lastname, O.orderid
FROM HR.Employees AS E, Sales.Orders AS O
WHERE E.empid = O.empid;
As with the WHERE and HAVING clauses, the ON clause also returns only rows for which the predicate evaluates to TRUE, and it does not return rows for which the predicate evaluates to FALSE or UNKNOWN.
|
-
When a join condition involves only an equality operator, the join is said to be an equi join.
-
When a join condition involves any operator besides equality, the join is said to be a non-equi join.
SELECT E1.empid, E1.firstname, E1.lastname, E2.empid, E2.firstname, E2.lastname FROM HR.Employees AS E1 INNER JOIN HR.Employees AS E2 ON E1.empid < E2.empid;
|
Standard SQL supports a concept called natural join, which represents an inner join based on a match between columns with the same name in both sides. T-SQL doesn’t have an implementation of a natural join. For example, A join that has an explicit join predicate like equi join and non-equi join that is based on a binary operator (equality or inequality) is known as a theta join. |
5.3. OUTER
Outer joins were introduced in SQL-92 and, unlike inner joins and cross joins, have only one standard syntax—the one in which the JOIN keyword is specified between the table names and the join condition is specified in the ON clause.
Outer joins apply the two logical processing phases that inner joins apply (Cartesian Product and the ON filter), plus a third phase called Adding Outer Rows that is unique to this type of join.
In an outer join, a table is marked as a preserved table by using the keywords LEFT OUTER JOIN, RIGHT OUTER JOIN, or FULL OUTER JOIN between the table names.
-
The
OUTERkeyword is optional. -
The
LEFTkeyword means that the rows of the left table (the one to the left of theJOINkeyword) are preserved; theRIGHTkeyword means that the rows in the right table are preserved; and theFULLkeyword means that the rows in both the left and right tables are preserved. -
The third logical query processing phase of an outer join identifies the rows from the preserved table that did not find matches in the other table based on the
ONpredicate, which adds those rows to the result table produced by the first two phases of the join, and it uses NULLs as placeholders for the attributes from the nonpreserved side of the join in those outer rows.SELECT C.custid, C.companyname, O.orderid FROM Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid = O.custid;
A FULL OUTER JOIN with the condition ON 1=1 is functionally equivalent to a CROSS JOIN.
|
|
If the predicate in the |
|
If the predicate in the inner join’s Remember that outer rows have NULLs in the attributes from the nonpreserved side of the join, and comparing a NULL with anything yields |
5.4. APPLY
The nonstandard APPLY operator, like a correlated join, instead of treaing its two inputs as a set, applies the right table (typically a derived table or a TVF) to each row from the left table (evaluated first) and produces a result table with the unified result sets.
-
A
CROSS APPLYoperator is equavelent to aCROSS JOIN.SELECT S.shipperid, E.empid FROM Sales.Shippers AS S CROSS JOIN HR.Employees AS E; -- => SELECT S.shipperid, E.empid FROM Sales.Shippers AS S CROSS APPLY HR.Employees AS E; -
With
APPLY, the left side is evaluated first, and the right side is evaluated per row from the left iteratively, and can have references to elements from the left.SELECT C.custid, A.orderid, A.orderdate FROM Sales.Customers AS C CROSS APPLY (SELECT TOP (3) orderid, empid, orderdate, requireddate FROM Sales.Orders AS O WHERE O.custid = C.custid ORDER BY orderdate DESC, orderid DESC) AS A; -- A is a correlated derived tableBecause the derived table is applied to each left row, the CROSS APPLY operator returns the three most recent orders for each customer.1 11011 2022-04-09 1 10952 2022-03-16 1 10835 2022-01-15 2 10926 2022-03-04 2 10759 2021-11-28 2 10625 2021-08-08 3 10856 2022-01-28 3 10682 2021-09-25 3 10677 2021-09-22 . . . -
If the right table expression returns an empty set, the
CROSS APPLYoperator does not return the corresponding left row. To return rows from the left side even if there are no matches on the right side, useOUTER APPLY.SELECT C.custid, A.orderid, A.orderdate FROM Sales.Customers AS C OUTER APPLY (SELECT orderid, empid, orderdate, requireddate FROM Sales.Orders AS O WHERE O.custid = C.custid AND O.custid in (22, 57) ORDER BY orderdate DESC, orderid DESC OFFSET 0 ROWS FETCH FIRST 3 ROWS ONLY) AS A;1 NULL NULL 2 NULL NULL 3 NULL NULL -
It’s more conventional to work with inline TVFs instead of derived tables.
CREATE OR ALTER FUNCTION dbo.TopOrders (@custid AS INT, @n AS INT) RETURNS TABLE AS RETURN SELECT orderid, empid, orderdate, requireddate FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, requireddate DESC OFFSET 0 ROWS FETCH NEXT @N ROWS ONLY; GO SELECT C.custid, C.companyname, A.orderid, A.empid, A.orderdate, A.requireddate FROM Sales.Customers AS C CROSS APPLY dbo.TopOrders(C.custid, 3) AS A; GO -- cleanup DROP FUNCTION if EXISTS dbo.TopOrders
6. Subqueries
SQL supports writing queries within queries, or nesting queries.
-
The outermost query is a query whose result set is returned to the caller and is known as the outer query.
-
The inner query is a query whose result set is used by the outer query and is known as a subquery.
-
A subquery can be either self-contained or correlated.
-
A self-contained subquery has no dependency on tables from the outer query, whereas a correlated subquery does.
-
A subquery can be single-valued, multivalued, or table-valued, that is, a subquery can return a single value, multiple values, or a whole table result.
-
In queries that include a correlated subquery (a.k.a., a repeating subquery), the subquery depends on the outer query for its values, which means that the subquery is executed repeatedly, once for each row that might be selected by the outer query.
SELECT custid, orderid, orderdate, empid FROM Sales.Orders AS O1 WHERE orderid = (SELECT MAX(O2.orderid) FROM Sales.Orders AS O2 WHERE O2.custid = O1.custid);
-
-
A scalar subquery is a subquery that return a single value or
NULLand can be anywhere in the outer query where a single-valued expression expected, such asWHEREorSELECT.DECLARE @maxid AS INT = (SELECT MAX(orderid) FROM Sales.Orders); SELECT orderid, orderdate, empid, custid FROM Sales.Orders WHERE orderid = @maxid; -- substitute the above variable with a scalar self-contained subquery SELECT orderid, orderdate, empid, custid FROM Sales.Orders WHERE orderid = (SELECT MAX(O.orderid) FROM Sales.Orders AS O); -
A multi-valued subquery is a subquery that returns multiple values as a single column, and such as the
INpredicate, operate on a multi-valued subquery.SELECT orderid FROM Sales.Orders WHERE empid IN (SELECT E.empid FROM HR.Employees AS E WHERE E.lastname LIKE N'D%');In some cases the database engine optimizes both the subquery and the the join the same way, sometimes joins perform better, and sometimes subqueries perform better.
6.1. Subqueries with IN or NOT IN
-
A subquery introduced with
INorNOT INprovides a set of zero or more values for the outer query’s filtering. -
An empty set will cause the
INcondition to always beFALSE, and theNOT INcondition to always beTRUE.
6.2. Subqueries with comparison operators
-
Subqueries can be introduced with one of the comparison operators (
=,< >,>,> =,<,! >,! <, or< =). -
A subquery introduced with an unmodified comparison operator (a comparison operator not followed by
ANY,SOMEorALL) must return a single value rather than a list of values, like subqueries introduced withIN, otherwise SQL Server displays an error message.
6.3. Subqueries with EXISTS or NOT EXISTS
-
A subquery introduced with
EXISTSorNOT EXISTSfunctions as an existence test, returningTRUEorFALSEto the outer query’sWHEREclause based on the presence or absence of rows, without actually producing data.SELECT custid, companyname FROM Sales.Customers AS C WHERE country = N'Spain' AND EXISTS (SELECT * FROM Sales.Orders AS O WHERE O.custid = C.custid);
7. Table Expressions
A table expression is an expression—typically a query—that conceptually returns a table result and as such can be nested as an operand of another table expression.
-
Recall that a table in SQL is the counterpart to a relation in relational theory.
-
A table expression is therefore SQL’s counterpart to a relational expression.
-
A relational expression in relational theory is an expression that returns a relation and as such can be nested as an operand of another relational expression.
-
A named table expression is then a table expression assigned with a name, and interacted with like doing with a base table.
T-SQL supports four types of named table expressions: derived tables, common table expressions (CTEs), views, and inline table-valued functions (inline TVFs).
7.1. Derived Tables
Derived tables are defined in the FROM clause of an outer query, which treated as if it were a regular table for the outer query, and also sometimes referred to as an inline view.
SELECT *
FROM (SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA') AS USACusts;SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM (SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders) AS D
GROUP BY orderyear;7.2. CTEs
A Common Table Expression (CTE) is a temporary, named result set created from a query, which can then be used within the scope of a single statement such as SELECT, INSERT, UPDATE, or DELETE. A CTE can also refer to itself in what is known as a recursive CTE.
WITH <CTE_Name>[(<target_column_list>)]
AS
(
<inner_query_defining_CTE>
)
<outer_query_against_CTE>;-
CTEs support two forms of column aliasing: inline, which uses the
ASkeyword to rename columns individually within theSELECTstatement, and external, which defines all column names at once in a parenthesized list immediately following the CTE’s name.-
Inline aliasing is the most common and recommended method, where each new column name is defined individually inside the
SELECTlist, directly following the column or expression it refers to.WITH UserCTE AS ( SELECT user_id AS ID, user_name AS Name FROM users ) SELECT ID, Name FROM UserCTE; -
External aliasing is an alternative method where a complete list of new column names is provided in parentheses immediately after the CTE’s name, before the query definition begins.
While less common, this method is required in certain scenarios, such as defining the column structure for recursive CTEs. WITH UserCTE (ID, Name) AS ( SELECT user_id, user_name FROM users ) SELECT ID, Name FROM UserCTE;
-
-
A CTE must be immediately consumed by a single
SELECT,INSERT,UPDATE,MERGE, orDELETEstatement. It can also be used to define the query within aCREATE VIEWstatement.CREATE VIEW RecentSalesHires AS -- 1. The CTE is defined first to simplify the logic. WITH SalesEmployees AS ( SELECT employee_id, employee_name, hire_date FROM employees WHERE department = 'Sales' AND status = 'Active' ) -- 2. The view's main SELECT statement then uses the CTE. SELECT employee_id, employee_name FROM SalesEmployees WHERE hire_date >= DATE('now', '-1 year'); -
A single, nonrecursive CTE can be defined by the combined results of multiple
SELECTqueries that are connected by a set operator likeUNION ALL,UNION,INTERSECT, orEXCEPT.-- This single CTE is defined by two SELECT statements -- combined with a set operator (UNION). WITH AllContacts AS ( -- The first SELECT query SELECT email_address FROM ActiveCustomers UNION -- The set operator that combines them -- The second SELECT query SELECT email FROM ProspectiveCustomers ) -- Now you can use the CTE, which contains the combined results. SELECT * FROM AllContacts; -
Each CTE can refer to all previously defined CTEs, and the outer query can refer to all CTEs.
WITH -- CTE 1: Finds all employees in the 'North America' region. RegionalEmployees AS ( SELECT employee_id, employee_name FROM employees WHERE region = 'North America' ), -- CTE 2: Calculates sales totals by joining with the first CTE. -- Note it only passes on the ID and the aggregated total. EmployeeSales AS ( SELECT re.employee_id, SUM(s.sale_amount) AS total_sales FROM sales AS s JOIN RegionalEmployees AS re ON s.employee_id = re.employee_id GROUP BY re.employee_id ) -- The outer query now joins BOTH CTEs to get the required columns. SELECT re.employee_name, -- This column comes from the first CTE. es.total_sales -- This column comes from the second CTE. FROM RegionalEmployees AS re JOIN EmployeeSales AS es ON re.employee_id = es.employee_id WHERE es.total_sales > 500000 ORDER BY es.total_sales DESC; -
Multiple references in CTEs in table operators like joins
WITH YearlyCount AS ( SELECT YEAR(orderdate) AS orderyear, COUNT(DISTINCT custid) AS numcusts FROM Sales.Orders GROUP BY YEAR(orderdate) ) SELECT Cur.orderyear, Cur.numcusts AS curnumcusts, Prv.numcusts AS prvnumcusts, Cur.numcusts - Prv.numcusts AS growth FROM YearlyCount AS Cur LEFT OUTER JOIN YearlyCount AS Prv ON Cur.orderyear = Prv.orderyear + 1; -
CTEs are unique among table expressions in the sense that they support recursion.
Recursive CTEs, like nonrecursive ones, are defined by the SQL standard. WITH <CTE_Name>[(<target_column_list>)] AS ( <anchor_member> UNION ALL <recursive_member> ) <outer_query_against_CTE>;-
A recursive CTE is defined by at least two queries (more are possible)—at least one query known as the anchor member and at least one query known as the recursive member.
-
The anchor member is a query that returns a valid relational result table —like a query that is used to define a nonrecursive table expression. The anchor member query is invoked only once.
-
The recursive member is a query that has a reference to the CTE name and is invoked repeatedly until it returns an empty set. The reference to the CTE name represents the previous result set.
-
The first time that the recursive member is invoked, the previous result set represents whatever the anchor member returned.
-
In each subsequent invocation of the recursive member, the reference to the CTE name represents the result set returned by the previous invocation of the recursive member.
-
Both queries must be compatible in terms of the number of columns they return and the data types of the corresponding columns.
-
The reference to the CTE name in the outer query represents the unified result sets of the invocation of the anchor member and all invocations of the recursive member.
WITH EmpsCTE AS ( SELECT empid, mgrid, firstname, lastname FROM HR.Employees WHERE empid = 2 UNION ALL SELECT C.empid, C.mgrid, C.firstname, C.lastname FROM EmpsCTE AS P INNER JOIN HR.Employees AS C ON C.mgrid = P.empid ) SELECT empid, mgrid, firstname, lastname FROM EmpsCTE;2 1 Don Funk 3 2 Judy Lew 5 2 Sven Mortensen 6 5 Paul Suurs 7 5 Russell King 9 5 Patricia Doyle 4 3 Yael Peled 8 3 Maria Cameron
-
-
CTEs are not permitted to nest in SQL, but they can be chained sequentially in a single
WITHclause, allowing each CTE to reference any of the ones defined before it to create a step-by-step logical flow.WITH -- 1. The first CTE identifies customers from a specific region. US_Customers AS ( SELECT customer_id, customer_name FROM customers WHERE country = 'USA' ), -- 2. The second CTE is "chained" by using the first CTE as its source -- to find the recent orders for only those customers. Recent_US_Orders AS ( SELECT usc.customer_name, o.order_id, o.order_total FROM orders AS o JOIN US_Customers AS usc ON o.customer_id = usc.customer_id WHERE o.order_date >= '2025-01-01' ) -- 3. The final query uses the last CTE in the chain to get the result. SELECT * FROM Recent_US_Orders;
7.3. Views and TVFs
Derived tables and CTEs have a single-statement scope, which means they are not reusable. Views and inline table-valued functions (inline TVFs) are two types of table expressions whose definitions are stored as permanent objects in the database, making them reusable.
CREATE OR ALTER VIEW Sales.USACusts
AS
SELECT
custid, companyname, contactname, contacttitle, address,
city, region, postalcode, country, phone, fax
FROM Sales.Customers
WHERE country = N'USA';
GO -- The GO command is used here to terminate what’s called a batch in T-SQL.
SELECT custid, companyname
FROM Sales.USACusts;-
Remember that a presentation
ORDER BYclause is not allowed in the query defining a table expression because a relation isn’t ordered.CREATE OR ALTER VIEW Sales.USACusts AS SELECT custid, companyname, contactname, contacttitle, address, city, region, postalcode, country, phone, fax FROM Sales.Customers WHERE country = N'USA' ORDER BY region; GOMsg 1033, Level 15, State 1, Procedure USACusts, Line 8 The ORDER BY clause is invalid in views, inline functions, derived tables, subqueries, and common table expressions, unless TOP, OFFSET or FOR XML is also specified. -
Inline TVFs are reusable table expressions that support input parameters.
-
In most respects, except for the support for input parameters, inline TVFs are similar to views, or parameterized views.
-
T-SQL supports another type of table function called multi-statement TVF, which populates and returns a table variable.
CREATE OR ALTER FUNCTION dbo.GetCustOrders (@cid AS INT) RETURNS TABLE AS RETURN SELECT orderid, custid, empid, orderdate, requireddate, shippeddate, shipperid, freight, shipname, shipaddress, shipcity, shipregion, shippostalcode, shipcountry FROM Sales.Orders WHERE custid = @cid; GO SELECT orderid, custid FROM dbo.GetCustOrders(1) AS O; GO SELECT O.orderid, O.custid, OD.productid, OD.qty FROM dbo.GetCustOrders(1) AS O INNER JOIN Sales.OrderDetails AS OD ON O.orderid = OD.orderid; GO DROP FUNCTION IF EXISTS dbo.GetCustOrders;
-
8. UNION, UNION ALL, INTERSECT, and EXCEPT
Set operators combine rows from two query result sets (or multisets), with some operators removing duplicates to return a set, while others preserve duplicates to return a multiset.
-
T-SQL supports the following operators:
UNION,UNION ALL,INTERSECT, andEXCEPT. -
A set operator compares complete rows between the results of the two input queries involved.
Input Query1 <set_operator> Input Query2 [ORDER BY ...];-
Because a set operator expects multisets as inputs, the two queries involved cannot have
ORDER BYclauses.Remember that a query with an ORDER BY clause does not return a multiset—it returns an ordered result. -
In terms of logical-query processing, each of the individual queries can have all logical-query processing phases except for a presentation
ORDER BY. -
The operator is applied to the results of the two queries, and the outer
ORDER BYclause (if one exists) is applied to the result of the operator. -
The two input queries must produce results with the same number of columns, and corresponding columns must have compatible data types.
-
The names of the columns in the result are determined by the first query. Still, it’s considered a best practice to make sure that all columns have names in both queries, and that the names of the corresponding columns are the same.
-
When a set operator compares rows between the two inputs, it doesn’t use an equality-based comparison; rather, it uses a distinctness-based comparison.
The semantics of distinctness-based comparisons are the same as the ones used by a standard predicate called the distinct predicate that treats NULLs just like non-NULL values for comparison purposes to ensure that two rows with NULL values in the same columns are treated as duplicates, which is often the desired behavior.
-
-
The SQL standard supports two "flavors" of each operator—
DISTINCT(the default) andALL.-
The
DISTINCTflavor eliminates duplicates and returns a set. -
ALLdoesn’t attempt to remove duplicates and therefore returns a multiset. -
All three operators in T-SQL support an implicit distinct version, but only the
UNIONoperator supports theALLversion. -
In terms of syntax, T-SQL implicitly applies the
DISTINCTclause unless theALLkeyword is explicitly used.
-
-
SQL defines precedence among set operators:
INTERSECToperator precedesUNIONandEXCEPT, andUNIONandEXCEPTare evaluated in order of appearance.
-- the result is a multiset and not a set
SELECT country, region, city FROM HR.Employees
UNION ALL
SELECT country, region, city FROM Sales.Customers;-- returns distinct locations
SELECT country, region, city FROM HR.Employees
UNION
SELECT country, region, city FROM Sales.Customers;-- returns only distinct rows that appear in both input query results
SELECT country, region, city FROM HR.Employees
INTERSECT
SELECT country, region, city FROM Sales.Customers;-- returns only distinct rows that appear in the first set but not the second
SELECT country, region, city FROM HR.Employees
EXCEPT
SELECT country, region, city FROM Sales.Customers;SELECT country, region, city FROM Production.Suppliers
EXCEPT
SELECT country, region, city FROM HR.Employees
INTERSECT -- evaluated first
SELECT country, region, city FROM Sales.Customers;9. Data Analysis
T-SQL in SQL Server offers robust features for data analysis, including window Functions, pivoting, unpivoting, grouping sets, and time series data handling.
9.1. Window Functions
A window function is a function that, for each row, computes a scalar result value based on a calculation against a subset as a window of the rows from the underlying query set.
-
Window functions perform calculations on a per-row basis within a defined window of rows, preserving detail, whereas grouped queries lose detail by aggregation.
-
Window functions operate directly on the underlying query result set, while subqueries often start with a fresh view of the data, potentially requiring duplication of query logic.
-
Window functions can define the order of rows for calculations separately from the presentation order of the result set.
-
Window functions are allowed only in the
SELECTandORDER BYclauses of a query.
A window function is defined by using the OVER clause with up to three parts: window-partition, window-order, and window-frame.
<function>( <expression> ) [ IGNORE NULLS | RESPECT NULLS ] OVER(...)-
An empty
OVER()clause represents the entire underlying query’s result set. -
The window-partition clause (
PARTITION BY) restricts the window to the subset of rows that have the same values in the partitioning columns as in the current row. -
The window-order clause (
ORDER BY) defines ordering, but don’t confuse this with presentation ordering.-
In a window aggregate function, window ordering supports a frame specification.
-
In a window ranking function, window ordering gives meaning to the rank.
-
-
The window-frame filters a frame, or a subset, of rows from the window partition between the two specified delimiters, which is defined using the
ROWSorRANGEclause.-
ROWS: Defines the frame based on the number of rows before and after the current row.ROWS BETWEEN <top delimiter> AND <bottom delimiter>-
UNBOUNDED PRECEDING: Includes all rows from the beginning of the partition up to the current row. -
n PRECEDING: Includes the current row and thenpreceding rows. -
CURRENT ROW: Includes only the current row. -
n FOLLOWING: Includes the current row and thenfollowing rows. -
UNBOUNDED FOLLOWING: Includes all rows from the current row to the end of the partition.
-
-
RANGE: Defines the frame based on the values of theORDER BYcolumn.RANGE BETWEEN <top delimiter> AND <bottom delimiter>-
UNBOUNDED PRECEDING: Includes all rows from the beginning of the partition up to the current row. -
n PRECEDING: Includes rows where theORDER BYcolumn’s value is withinnunits of the current row’s value. -
CURRENT ROW: Includes only the current row. -
n FOLLOWING: Includes rows where theORDER BYcolumn’s value is withinnunits of the current row’s value. -
UNBOUNDED FOLLOWING: Includes all rows from the current row to the end of the partition.
-
-- compute the running-total for each employee and month SELECT empid, ordermonth, val, SUM(val) OVER( PARTITION BY empid -- For an underlying row with employee ID `1`, the window exposed to the function filters only the rows where the employee ID is `1`. ORDER BY ordermonth ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ) AS runval FROM Sales.EmpOrders;1 2020-07-01 1614.88 1614.88 1 2020-08-01 5555.90 7170.78 1 2020-09-01 6651.00 13821.78 . . . -
9.1.1. Ranking
T-SQL supports four ranking functions: ROW_NUMBER, RANK, DENSE_RANK, and NTILE to rank each row with respect to others in the window.
SELECT orderid, custid, val,
ROW_NUMBER() OVER(ORDER BY val) AS rownum,
RANK() OVER(ORDER BY val) AS rank,
DENSE_RANK() OVER(ORDER BY val) AS dense_rank,
NTILE(10) OVER(ORDER BY val) AS ntile
FROM Sales.OrderValues
ORDER BY val;orderid custid val rownum rank dense_rank ntile
10782 12 12.50 1 1 1 1
10807 27 18.40 2 2 2 1
10586 66 23.80 3 3 3 1
10767 76 28.00 4 4 4 1
10898 54 30.00 5 5 5 1
10900 88 33.75 6 6 6 1
10883 48 36.00 7 7 7 1
11051 41 36.00 8 7 7 1
10815 71 40.00 9 9 8 1
10674 38 45.00 10 10 9 1
11057 53 45.00 11 10 9 1
10271 75 48.00 12 12 10 1
. . .
10496 81 190.00 83 83 78 1
10793 4 191.10 84 84 79 2
10428 66 192.00 85 85 80 2
. . .-
The
ROW_NUMBERfunction assigns incremental sequential integers to the rows in the query result based on the mandatory window ordering. -
The
RANKorDENSE_RANKfunction will produce same value when there are ties in the ordering values, and the difference between the two is thatRANKreflects the count of rows that have a lower ordering value than the current row (plus 1), whereasDENSE_RANKreflects the count of distinct ordering values that are lower than the current row (plus 1). -
The
NTILEfunction assigns a tile number to each row associated the rows in the result with tiles (equally sized groups of rows).If the number of rows can’t be evenly divided by the number of tiles, an extra row is added to each of the first tiles from the remainder. For example, if 102 rows and five tiles were requested, the first two tiles would have 21 rows instead of 20.
-
Window functions are logically evaluated as part of the
SELECTlist, before theDISTINCTclause is evaluated.-- DISTINCT clause has no effect here, no duplicate rows to remove SELECT DISTINCT val, ROW_NUMBER() OVER(ORDER BY val) AS rownum FROM Sales.OrderValues;-- an alternative solution: GROUP BY phase is processed before the SELECT phase SELECT val, ROW_NUMBER() OVER(ORDER BY val) AS rownum FROM Sales.OrderValues GROUP BY val;
9.1.2. Offset
T-SQL supports two pairs of offset functions: LAG and LEAD, and FIRST_VALUE and LAST_VALUE, to return an element from a row that is at a certain offset from the current row or at the beginning or end of a window frame.
-
The
LAGandLEADfunctions look before and ahead respectively to obtain an element from a row that is at a certain offset from the current row within the partition, based on the indicated ordering.-- the LAG and LEAD functions support window partitions and window-order clauses. LAG(column_name, offset, default_value) OVER(...) LEAD(column_name, offset, default_value) OVER(...)-
column_name: the functions (which is mandatory) is the element to return. -
offset: (Optional) An integer specifying the number (1if not specified) of rows to offset from the current row. -
default_value: (Optional) A value to be returned if there is no row at the requested offset (which isNULLif not specified otherwise).
SELECT custid, orderid, val, LAG(val) OVER(PARTITION BY custid -- same as: LAG(val, 1, NULL) ORDER BY orderdate, orderid) AS prevval, LEAD(val) OVER(PARTITION BY custid -- same as: LEAD(val, 1, NULL) ORDER BY orderdate, orderid) AS nextval FROM Sales.OrderValues ORDER BY custid, orderdate, orderid;custid orderid val prevval nextval . . . 1 10952 471.20 845.80 933.50 1 11011 933.50 471.20 NULL 2 10308 88.80 NULL 479.75 2 10625 479.75 88.80 320.00 . . . -
-
The
FIRST_VALUEandLAST_VALUEfunctions return an element from the first and last rows in the window frame, respectively.-
To obtain the element from the first row in the window partition, use
FIRST_VALUEwith the window-frame extentROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. -
To obtain the element from the last row in the window partition, use
LAST_VALUEwith the window-frame extentROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING.
SELECT custid, orderid, val, FIRST_VALUE(val) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS firstval, LAST_VALUE(val) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS lastval FROM Sales.OrderValues ORDER BY custid, orderdate, orderidcustid orderid val firstval lastval 1 10643 814.50 814.50 933.50 . . . 1 11011 933.50 814.50 933.50 2 10308 88.80 88.80 514.40 . . . -
9.1.3. Aggregate
The aggregate window functions aggregate the rows in the defined window, and support window-partition, window-order, and window-frame clauses.
SELECT orderid, custid, val,
100. * val / SUM(val) OVER() AS pctall, -- percentage out of the grand total
100. * val / SUM(val) OVER(PARTITION BY custid) AS pctcust -- percentage out of the customer total
FROM Sales.OrderValues;SELECT empid, ordermonth, val,
SUM(val) OVER(PARTITION BY empid
ORDER BY ordermonth
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) AS runval
FROM Sales.EmpOrders;9.1.4. WINDOW
The WINDOW clause defines and names reusable entire window specifications or part of them, improving code readability and maintainability by reducing redundancy in complex queries with multiple window functions. It is available in SQL Server 2022 and higher, as well as in Azure SQL Database, provided that the database compatibility level is set to 160 or higher.
SELECT DATABASEPROPERTYEX(N'TSQLV6', N'CompatibilityLevel'); -- 160When considering all major query clauses (SELECT, FROM, WHERE, GROUP BY, HAVING, ORDER BY), place the WINDOW clause between the HAVING and ORDER BY clauses of the query.
SELECT empid, ordermonth, val,
SUM(val) OVER W AS runsum,
MIN(val) OVER W AS runmin,
MAX(val) OVER W AS runmax,
AVG(val) OVER W AS runavg
FROM Sales.EmpOrders
WINDOW W AS (PARTITION BY empid -- name an entire window specification
ORDER BY ordermonth
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW);SELECT custid, orderid, val,
FIRST_VALUE(val) OVER(PO
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) AS firstval,
LAST_VALUE(val) OVER(PO
ROWS BETWEEN CURRENT ROW
AND UNBOUNDED FOLLOWING) AS last
FROM Sales.OrderValues
WINDOW PO AS (PARTITION BY custid -- name part of a window specification
ORDER BY orderdate, orderid)
ORDER BY custid, orderdate, orderid;SELECT orderid, custid, orderdate, qty, val,
ROW_NUMBER() OVER PO AS ordernum,
MAX(orderdate) OVER P AS maxorderdate,
SUM(qty) OVER POF AS runsumqty,
SUM(val) OVER POF AS runsumval
FROM Sales.OrderValues
WINDOW P AS ( PARTITION BY custid ), -- recursively reuse one window name within another
PO AS ( P ORDER BY orderdate, orderid ),
POF AS ( PO ROWS UNBOUNDED PRECEDING )
ORDER BY custid, orderdate, orderid;9.2. Pivoting
Pivoting data involves rotating data from a state of rows to a state of columns, possibly aggregating values along the way, in many cases which is generally handled by the presentation layer for purposes such as reporting.
-- create and populate the sample table dbo.Orders
USE TSQLV6;
DROP TABLE IF EXISTS dbo.Orders;
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL
CONSTRAINT PK_Orders PRIMARY KEY,
orderdate DATE NOT NULL,
empid INT NOT NULL,
custid VARCHAR(5) NOT NULL,
qty INT NOT NULL
);
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid, qty)
VALUES
(30001, '20200802', 3, 'A', 10),
(10001, '20201224', 2, 'A', 12),
(10005, '20201224', 1, 'B', 20),
(40001, '20210109', 2, 'A', 40),
(10006, '20210118', 1, 'C', 14),
(20001, '20210212', 2, 'B', 12),
(40005, '20220212', 3, 'A', 10),
(20002, '20220216', 1, 'C', 20),
(30003, '20220418', 2, 'B', 15),
(30004, '20200418', 3, 'C', 22),
(30007, '20220907', 3, 'D', 30);-- query and return the total order quantity for each employee and customer
SELECT empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY empid, custid;empid custid sumqty
2 A 52
3 A 20
1 B 20
2 B 27
1 C 34
3 C 22
3 D 30empid A B C D
1 NULL 20 34 NULL
2 52 27 NULL NULL
3 20 NULL 22 30Every pivoting request involves three logical processing phases, each with associated elements:
-
A grouping phase with an associated grouping or on rows element
-
A spreading phase with an associated spreading or on cols element
-
An aggregation phase with an associated aggregation element and aggregate function
9.2.1. Grouped Query
SELECT empid,
SUM( (3)
CASE WHEN custid = 'A' THEN qty END (2)
) AS A,
SUM(CASE WHEN custid = 'B' THEN qty END) AS B,
SUM(CASE WHEN custid = 'C' THEN qty END) AS C,
SUM(CASE WHEN custid = 'D' THEN qty END) AS D
FROM dbo.Orders
GROUP BY empid; (1)| 1 | The grouping phase is achieved with a GROUP BY clause—in this case, GROUP BY empid. |
| 2 | The spreading phase is achieved in the SELECT clause with a CASE expression for each target column.
|
| 3 | Finally, the aggregation phase is achieved by applying the relevant aggregate function to the result of each CASE expression.
|
9.2.2. PIVOT Operator
T- SQL also supports a proprietary table operator called PIVOT on a source table or table expression provided to it as its left input, pivots the data, and returns a result table.
SELECT ...
FROM <input_table>
PIVOT(<agg_function>(<aggregation_element>)
FOR <spreading_element> IN (<list_of_target_columns>))
WHERE ...;-
The
PIVOToperator figures out the grouping elements implicitly by elimination, that are all attributes from the source table that were not specified as either the spreading element or the aggregation element.-- custid is the spreading element -- qty is the aggregation element -- the left empid is the implied grouping element SELECT empid, A, B, C, D FROM (SELECT empid, custid, qty FROM dbo.Orders) AS D PIVOT(SUM(qty) FOR custid IN(A, B, C, D)) AS P; -
As a best practice with the
PIVOToperator, always work with a table expression and not query the underlying table directly.-- the dbo.Orders table contains the attributes orderid, orderdate, empid, custid, and qty. -- the remaining attributes (orderid, orderdate, and empid) are all considered the grouping elements SELECT empid, A, B, C, D FROM dbo.Orders PIVOT(SUM(qty) FOR custid IN(A, B, C, D)) AS P; -
The items in the list of the target columns must be referred to as identifiers in the
INclause, and be delimited using square brackets when they are irregular (contain spaces, special characters, or are reserved keywords).SELECT custid, [1], [2], [3], [4] FROM (SELECT empid, custid, qty FROM dbo.Orders) AS D PIVOT(SUM(qty) FOR empid IN ([1], [2], [3], [4])) AS P;
9.3. Unpivoting
Unpivoting is a technique that rotates data from a state of columns to a state of rows.
-- create and populate the sample table dbo.EmpCustOrders
USE TSQLV6;
DROP TABLE IF EXISTS dbo.EmpCustOrders;
CREATE TABLE dbo.EmpCustOrders
(
empid INT NOT NULL
CONSTRAINT PK_EmpCustOrders PRIMARY KEY,
A VARCHAR(5) NULL,
B VARCHAR(5) NULL,
C VARCHAR(5) NULL,
D VARCHAR(5) NULL
);
INSERT INTO dbo.EmpCustOrders(empid, A, B, C, D)
SELECT empid, A, B, C, D
FROM (SELECT empid, custid, qty
FROM dbo.Orders) AS D
PIVOT(SUM(qty) FOR custid IN(A, B, C, D)) AS P;SELECT * FROM dbo.EmpCustOrders;empid A B C D
1 NULL 20 34 NULL
2 52 27 NULL NULL
3 20 NULL 22 30empid custid qty
1 B 20
1 C 34
2 A 52
2 B 27
3 A 20
3 C 22
3 D 309.3.1. APPLY Operator
-- 1. Producing copies
SELECT *
FROM dbo.EmpCustOrders
CROSS JOIN (VALUES('A'),('B'),('C'),('D')) AS C(custid);
-- empid A B C D custid
-- 1 NULL 20 34 NULL A
-- 1 NULL 20 34 NULL B
-- 1 NULL 20 34 NULL C
-- . . .
-- 2. Extracting values
SELECT empid, custid, qty
FROM dbo.EmpCustOrders
-- a join treats its two inputs as a set;
-- use the CROSS APPLY operator instead of the CROSS JOIN operator
-- to refer to the columns A, B, C, and D from the left side of the join (EmpCustOrders)
CROSS APPLY (VALUES('A', A),('B', B),('C', C),('D', D)) AS C(custid, qty)
-- empid custid qty
-- 1 A NULL
-- 1 B 20
-- 1 C 34
-- . . .
-- 3. Eliminating irrelevant rows
SELECT empid, custid, qty
FROM dbo.EmpCustOrders
CROSS APPLY (VALUES('A', A),('B', B),('C', C),('D', D)) AS C(custid, qty)
WHERE qty IS NOT NULL; -- discard rows with a NULL in the qty column
-- empid custid qty
-- 1 B 20
-- 1 C 34
-- 2 A 52
-- . . .9.3.2. UNPIVOT Operator
T- SQL, like the PIVOT operator, also supports the UNPIVOT operator to unpivot data involved producing two result columns from any number of source columns—one to hold the source column names as strings and another to hold the source column values.
SELECT ...
FROM <input_table>
UNPIVOT(<values_column> FOR <names_column> IN(<source_columns>)
WHERE ...;SELECT empid, custid, qty
FROM dbo.EmpCustOrders
UNPIVOT(qty FOR custid IN(A, B, C, D)) AS U;9.4. Grouping Sets
A grouping set is a set of expressions to group the data by in a grouped query (a query with a GROUP BY clause).
-
Traditionally in SQL, a single grouped query defines a single grouping set.
-- set(empid, custid) SELECT empid, custid, SUM(qty) AS sumqty FROM dbo.Orders GROUP BY empid, custid; -- set(empid) SELECT empid, SUM(qty) AS sumqty FROM dbo.Orders GROUP BY empid; -- set(custid) SELECT custid, SUM(qty) AS sumqty FROM dbo.Orders GROUP BY custid; -- set() SELECT SUM(qty) AS sumqty FROM dbo.Orders; -
Use
UNION ALLwithNULLplaceholders to combine multiple queries into a single result set for reporting, but potentially lead to two main problems—the length of the code and performance due to multiple scans for separated query.SELECT empid, custid, SUM(qty) AS sumqty FROM dbo.Orders GROUP BY empid, custid UNION ALL SELECT empid, NULL, SUM(qty) AS sumqty FROM dbo.Orders GROUP BY empid UNION ALL SELECT NULL, custid, SUM(qty) AS sumqty FROM dbo.Orders GROUP BY custid UNION ALL SELECT NULL, NULL, SUM(qty) AS sumqty FROM dbo.Orders; -
T-SQL supports the standard
GROUPING SETS,CUBE, andROLLUPsubclauses of theGROUP BYclause, and theGROUPINGandGROUPING_IDfunctions to define multiple grouping sets in the same query for reporting and data analysis.-
The
GROUPING SETSsubclause is a powerful enhancement to theGROUP BYclause to define multiple grouping sets in the same query.-
The grouping sets are listed, separated by commas within the parentheses of the
GROUPING SETSsubclause, and for each grouping set list the members, separated by commas, within parentheses. -
SQL Server typically needs fewer scans of the data than the number of grouping sets because it can roll up aggregates internally.
SELECT empid, custid, SUM(qty) AS sumqty FROM dbo.Orders GROUP BY GROUPING SETS ( (empid, custid), (empid), (custid), () );
-
-
-
The
CUBEsubclause of theGROUP BYclause provides an abbreviated way to define multiple grouping sets.-
In the parentheses of the
CUBEsubclause, provide a set of members separated by commas, and get all possible grouping sets that can be defined based on the input members. -
In set theory, the set of all subsets of elements that can be produced from a particular set is called the power set.
For example,
CUBE(a, b, c)is equivalent toGROUPING SETS( (a, b, c), (a, b), (a, c), (b, c), (a), (b), (c), () ).SELECT empid, custid, SUM(qty) AS sumqty FROM dbo.Orders GROUP BY CUBE(empid, custid);
-
-
The
ROLLUPsubclause of theGROUP BYclause also provides an abbreviated way to define multiple grouping sets.-
Unlike
CUBE, which produces all possible grouping sets,ROLLUPassumes a hierarchy among input members and produces only grouping sets that form leading combinations of those members.For example, whereas
CUBE(a, b, c)produces all eight possible grouping sets,ROLLUP(a, b, c)produces only four based on the hierarchya>b>cthat is the equivalent of specifyingGROUPING SETS( (a, b, c), (a, b), (a), () )rolling up the aggregations from the most granular level(a, b, c)to higher levels like(a, b)and finally to the total().-- ROLLUP(YEAR(orderdate), MONTH(orderdate), DAY(orderdate)) -- => -- GROUPING SETS( -- (YEAR(orderdate), MONTH(orderdate), DAY(orderdate)), -- (YEAR(orderdate), MONTH(orderdate)), -- (YEAR(orderdate)), -- () ) SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth, DAY(orderdate) AS orderday, SUM(qty) AS sumqty FROM dbo.Orders GROUP BY ROLLUP(YEAR(orderdate), MONTH(orderdate), DAY(orderdate))
-
-
The
GROUPINGandGROUPING_IDfunctions are used to identify which columns in aGROUP BYclause are included in a group set or or are represented by aNULLplaceholder in the aggregated result set.-
GROUPING: returns1when the element isn’t part of the grouping set and0otherwise.SELECT GROUPING(empid) AS grpemp, GROUPING(custid) AS grpcust, empid, custid, SUM(qty) AS sumqty FROM dbo.Orders GROUP BY CUBE(empid, custid);grpemp grpcust empid custid sumqty 0 0 2 A 52 0 0 3 A 20 1 0 NULL A 72 . . . -
GROUPING_ID: returns an integer bitmap in which each bit represents a different input element—the rightmost element represented by the rightmost bit.SELECT GROUPING_ID(empid, custid) AS groupingset, empid, custid, SUM(qty) AS sumqty FROM dbo.Orders GROUP BY CUBE(empid, custid);groupingset empid custid sumqty 0 2 A 52 -- 00 0 3 A 20 -- 00 2 NULL A 72 -- 10 . . .
-
9.5. Time Series
Time series data is data representing a series of events, or measurements, typically taken at regular time intervals. Time series data analysis usually involves organizing the data in groups, also known as buckets, and then aggregating some measures per bucket.
10. INSERT, DELETE, TRUNCATE, UPDATE, and MERGE
SQL has a set of statements known as Data Manipulation Language (DML) that includes the statements SELECT, INSERT, UPDATE, DELETE, TRUNCATE, and MERGE.
10.1. INSERT
T-SQL provides several statements for inserting data into tables: INSERT VALUES, INSERT SELECT, INSERT EXEC, SELECT INTO, and BULK INSERT.
10.1.1. INSERT VALUES
The standard INSERT VALUES statement is used to insert rows into a table based on specified values.
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid)
VALUES(10001, '20220212', 3, 'A');-
Specifying the target column names right after the table name is optional, but by doing so, it can control the value-column associations instead of relying on the order of the columns in the
CREATE TABLEstatement. -
In T-SQL, specifying the
INTOclause is optional. -
If a value for a column is NOT specified, Microsoft SQL Server will use a default value if one was defined for the column.
-
If a default value isn’t defined and the column allows NULLs, a
NULLwill be used. -
If no default is defined and the column does not allow NULLs and does not somehow get its value automatically, the
INSERTstatement will fail.
T-SQL supports an enhanced standard VALUES clause that can be used to specify multiple rows separated by commas.
-
The enhanced standard
VALUESstatement is processed as a transaction, meaning that if any row fails to enter the table, none of the rows in the statement enters the table.INSERT INTO dbo.Orders (orderid, orderdate, empid, custid) VALUES (10003, '20220213', 4, 'B'), (10004, '20220214', 1, 'A'), (10005, '20220213', 1, 'C'), (10006, '20220215', 3, 'C'); -
The enhanced
VALUESclause can be used as a table-value constructor to construct a derived table.SELECT * FROM ( VALUES (10003, '20220213', 4, 'B'), (10004, '20220214', 1, 'A'), (10005, '20220213', 1, 'C'), (10006, '20220215', 3, 'C') ) AS O(orderid, orderdate, empid, custid); -- alias(es) to the table, and the target columns
10.1.2. INSERT SELECT
The standard INSERT SELECT statement inserts a set of rows returned by a SELECT query into a target table.
-
The
INSERT SELECTstatement is performed as a transaction, so if any row fails to enter the target table, none of the rows enters the table.INSERT INTO dbo.Orders(orderid, orderdate, empid, custid) SELECT orderid, orderdate, empid, custid FROM Sales.Orders WHERE shipcountry = N'UK';If a system function such as SYSDATETIMEis included in the inserted query, the function gets invoked only once for the entire query and not once per row. The exception to this rule is if globally unique identifiers (GUIDs) is generated using theNEWIDfunction, which gets invoked per row.
10.1.3. INSERT EXEC
The INSERT EXEC statement is used to insert a result set returned from a stored procedure or a dynamic SQL batch into a target table.
CREATE OR ALTER PROC Sales.GetOrders
@country AS NVARCHAR(40)
AS
SELECT orderid, orderdate, empid, custid
FROM Sales.Orders
WHERE shipcountry = @country;
GO
INSERT INTO dbo.Orders (orderid, orderdate, empid, custid)
EXEC Sales.GetOrders @country = N'France';10.1.4. SELECT INTO
The SELECT INTO statement is a nonstandard (not part of the ISO and ANSI SQL) T-SQL statement that CREATEs a target table and populates it with the result set of a query.
DROP TABLE IF EXISTS dbo.Orders;
SELECT orderid, orderdate, empid, custid
INTO dbo.Orders
FROM Sales.Orders;-- SELECT INTO statement with set operations
DROP TABLE IF EXISTS dbo.Locations;
SELECT country, region, city
INTO dbo.Locations
FROM Sales.Customers
EXCEPT
SELECT country, region, city
FROM HR.Employees;-
The target table’s structure and data are based on the source table.
-
The
SELECT INTOstatement copies from the source the base structure (such as column names, types, nullability, and identity property) and the data, but does not copy from the source constraints, indexes, triggers, column properties, and permissions.
10.1.5. BULK INSERT
The BULK INSERT statement is a server-side T-SQL command for high-speed data loading that requires the data file to reside on a local or network path accessible to the SQL Server service account, as the path is resolved by the server, not the client.
BULK INSERT dbo.Orders
FROM '\ServerName\Share\orders.txt' -- Path must be accessible by the SQL Server service
WITH (
DATAFILETYPE = 'char',
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n',
BATCHSIZE = 10000,
TABLOCK
);|
While |
bcp and SqlBulkCopy
|
10.2. DELETE and TRUNCATE
T-SQL provides two statements for deleting rows from a table: DELETE and TRUNCATE.
-
The
DELETEstatement is a standard statement used to delete data from a table based on an optional filter predicate.DELETE FROM dbo.Orders WHERE orderdate < '20210101';-
The
DELETEstatement tends to be expensive when deleting a large number of rows, mainly because it’s a fully logged operation.
-
-
The standard
TRUNCATEstatement deletes all rows from a table without filter.TRUNCATE TABLE dbo.T1;-
The advantage that
TRUNCATEhas overDELETEis that the former is minimally logged, whereas the latter is fully logged, resulting in significant performance differences. -
TRUNCATEresets the identity value back to the original seed, butDELETEdoesn’t—even when used without a filter. -
The
TRUNCATEstatement is not allowed when the target table is referenced by a foreign-key constraint, even if the referencing table is empty and even if the foreign key is disabled. -
The
TRUNCATEstatement can be used to truncate individual partitions in a partitioned table.TRUNCATE TABLE dbo.T1 WITH ( PARTITIONS(1, 3, 5, 7 TO 10) );
-
-
T-SQL supports a nonstandard
DELETEsyntax based on joins to delete rows from one table based on a filter against attributes in related rows from another table.DELETE FROM O FROM dbo.Orders AS O INNER JOIN dbo.Customers AS C ON O.custid = C.custid WHERE C.country = N'USA';
10.3. UPDATE
T-SQL supports a standard UPDATE statement to update rows in a table, and also supports nonstandard forms of the UPDATE statement with joins and with variables.
-
The
UPDATEstatement is a standard statement to update a subset of rows in a table.-
To identify the subset of rows to update, specify a predicate in a
WHEREclause. -
Specify the assignment of values to columns in a
SETclause, separated by commas.UPDATE dbo.OrderDetails SET discount = discount + 0.05 WHERE productid = 51; -
T-SQL supports compound assignment operators:
+=(plus equal),−=(minus equal),*=(multiplication equal),/=(division equal),%=(modulo equal), and others.UPDATE dbo.OrderDetails SET discount += 0.05 WHERE productid = 51; -
All-at-once operations: all expressions that appear in the same logical phase are evaluated as a set, logically at the same point in time.
-- the assignments take place all at once, meaning that both assignments use the same value of col1—the value before the update. UPDATE dbo.T1 SET col1 = col1 + 10, col2 = col1 + 10;-- swap the values in the columns col1 and col2 UPDATE dbo.T1 SET col1 = col2, col2 = col1;
-
-
The
UPDATEstatement also supports a nonstandard form based on joins that serves a filtering purpose.UPDATE OD SET discount += 0.05 FROM dbo.OrderDetails AS OD INNER JOIN dbo.Orders AS O ON OD.orderid = O.orderid WHERE O.custid = 1;-- same task by using standard code (recommended) UPDATE dbo.OrderDetails SET discount += 0.05 WHERE EXISTS (SELECT * FROM dbo.Orders AS O WHERE O.orderid = OrderDetails.orderid AND O.custid = 1); -
T-SQL supports a proprietary
UPDATEsyntax that both updates data in a table and assigns values to variables at the same time.DECLARE @nextval AS INT; UPDATE dbo.MySequences SET @nextval = val += 1 WHERE id = 'SEQ1'; SELECT @nextval;
10.4. MERGE
T-SQL supports a statement called MERGE to merge data from a source into a target, applying different actions (INSERT, UPDATE, and DELETE) based on conditional logic.
A task achieved by a single MERGE statement typically translates to a combination of several other DML statements (INSERT, UPDATE, and DELETE) without MERGE.
MERGE INTO dbo.Customers AS TGT
USING dbo.CustomersStage AS SRC
ON TGT.custid = SRC.custid
WHEN MATCHED THEN
UPDATE SET
TGT.companyname = SRC.companyname,
TGT.phone = SRC.phone,
TGT.address = SRC.address
WHEN NOT MATCHED THEN
INSERT (custid, companyname, phone, address)
VALUES (SRC.custid, SRC.companyname, SRC.phone, SRC.address);11. System-Versioned Temporal Tables
Temporal tables provide a powerful mechanism for tracking changes to data over time to easily capture and query historical versions of data, which is crucial for various scenarios such as auditing, data analysis, and data recovery.
-
Track Data Changes: Capture all modifications (insertions, updates, deletions) to the data over time.
-
Audit Data Modifications: Track who made changes, when they were made, and the previous state of the data for auditing and compliance purposes.
-
Perform Point-in-Time Analysis: Analyze data as it existed at any point in the past.
-
Data Recovery: Easily restore previous versions of data in case of accidental deletions or updates.
-
Support Slowly Changing Dimensions: Efficiently manage slowly changing dimensions (SCDs) in data warehousing.
The SQL standard supports three types of temporal tables:
-
System-versioned temporal tables rely on the system transaction time to define the validity period of a row.
-
Application-time period tables rely on the application’s definition of the validity period of a row.
-
Bitemporal combines the two types just mentioned (transaction and valid time).
SQL Server 2022 supports only system-versioned temporal tables.
A system-versioned temporal table has two columns representing the validity period of the row, plus a linked history table with a mirrored schema holding older states of modified rows.
-
To create a system-versioned temporal table, make sure the table definition has all the following elements:
CREATE TABLE dbo.Employees ( empid INT NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, (1) empname VARCHAR(25) NOT NULL, department VARCHAR(50) NOT NULL, salary NUMERIC(10, 2) NOT NULL, validfrom DATETIME2(0) GENERATED ALWAYS AS ROW START HIDDEN NOT NULL, (2) validto DATETIME2(0) GENERATED ALWAYS AS ROW END HIDDEN NOT NULL, (2) PERIOD FOR SYSTEM_TIME (validfrom, validto) (3) ) WITH ( SYSTEM_VERSIONING = ON (4) ( HISTORY_TABLE = dbo.EmployeesHistory, (5) HISTORY_RETENTION_PERIOD = 5 YEARS (6) ) );1 A primary key 2 Two columns defined as DATETIME2with any precision, which are non-nullable and represent the start and end of the row’s validity period in the UTC time zone-
A start column that should be marked with the option
GENERATED ALWAYS AS ROW START -
An end column that should be marked with the option
GENERATED ALWAYS AS ROW END -
Optionally, the period columns can be marked as hidden so that when querying the table with
SELECT *they won’t be returned and when inserting data they’ll be ignored. -
The modification times that SQL Server records in the period columns reflect the transaction start time.
If a long-running transaction that started at point in time T1 and ended at T2, SQL Server will record T1 as the modification time for all statements.
3 A designation of the period columns with the option PERIOD FOR SYSTEM_TIME (<startcol>, <endcol>)4 The table option SYSTEM_VERSIONING, which should be set toON5 A linked history table (which SQL Server can create automatically) to hold the past states of modified rows If do not specify a name for the table, SQL Server assigns one using the form
MSSQL_TemporalHistoryFor_<object_id>, whereobject_idis the object ID of the current table.6 Optionally, define a history retention policy using the HISTORY_RETENTION_PERIOD subclause of the SYSTEM_VERSIONING clause. -
-
To drop a system-versioned table, first disable system versioning with an ALTER TABLE command, and then manually drop the current and history tables.
IF OBJECT_ID(N'dbo.Employees', N'U') IS NOT NULL BEGIN ALTER TABLE dbo.Employees SET ( SYSTEM_VERSIONING = OFF ); DROP TABLE IF EXISTS dbo.EmployeesHistory; DROP TABLE IF EXISTS dbo.Employees; END; -
When modifying data, interact with the current table, issuing normal data-modification statements.
SQL Server automatically updates the period columns and moves older versions of rows to the history table.
INSERT INTO dbo.Employees (empid, empname, department, salary) VALUES(1, 'Sara', 'IT' , 50000.00), (2, 'Don' , 'HR' , 45000.00), (3, 'Judy', 'Sales' , 55000.00), (4, 'Yael', 'Marketing', 55000.00), (5, 'Sven', 'IT' , 45000.00), (6, 'Paul', 'Sales' , 40000.00);-- current table has the six new rows SELECT empid, empname, department, salary, validfrom, validto FROM dbo.Employees; -- history table is empty at this point SELECT empid, empname, department, salary, validfrom, validto FROM dbo.EmployeesHistory;-- SQL Server moves the deleted row to the history table, setting its validto value to the deletion time. DELETE FROM dbo.Employees WHERE empid = 6; SELECT empid, empname, department, salary, validfrom, validto FROM dbo.EmployeesHistory; -- 6 Paul Sales 40000.00 2025-01-15 03:42:15 2025-01-15 03:44:53-- An update of a row is treated as a delete plus an insert. UPDATE dbo.Employees SET salary *= 1.05 WHERE department = 'IT'; SELECT empid, empname, department, salary, validfrom, validto FROM dbo.Employees WHERE department = 'IT'; -- 1 Sara IT 52500.00 2025-01-15 03:47:42 9999-12-31 23:59:59 -- 5 Sven IT 47250.00 2025-01-15 03:47:42 9999-12-31 23:59:59 SELECT empid, empname, department, salary, validfrom, validto FROM dbo.EmployeesHistory WHERE department = 'IT'; -- 1 Sara IT 50000.00 2025-01-15 03:42:15 2025-01-15 03:47:42 -- 5 Sven IT 45000.00 2025-01-15 03:42:15 2025-01-15 03:47:42 -
When querying data, for the current state, simply query the current table as usual, and to see a past state, correct to a certain point or period of time, query the current table followed by the
FOR SYSTEM_TIMEclause, plus a subclause that indicates more specifics.SQL Server will retrieve the data from both the current and history tables as needed.
Table 1. Qualifying rows for FOR SYSTEM_TIME subclauses [<datetime2 value>] Subclause
Qualifying rows
AS OF @datetimevalidfrom <= @datetime AND validto > @datetimeFROM @start TO @endvalidfrom < @end AND validto > @startBETWEEN @start AND @endvalidfrom <= @end AND validto > @startCONTAINED IN(@start, @end)validfrom >= @start AND validto <= @endALLAll rows from both tables (T-SQL*)
DECLARE @datetime AS DATETIME2 = '2025-01-15 03:45:00'; SELECT empid, empname, department, salary, validfrom, validto FROM dbo.Employees FOR SYSTEM_TIME AS OF @datetime; -- same as DECLARE @datetime AS DATETIME2 = '2025-01-15 03:45:00'; SELECT empid, empname, department, salary, validfrom, validto FROM dbo.Employees WHERE validfrom <= @datetime AND validto > @datetime UNION ALL SELECT empid, empname, department, salary, validfrom, validto FROM dbo.EmployeesHistory WHERE validfrom <= @datetime AND validto > @datetime
12. Transactions and Concurrency
A transaction is a unit of work that might include multiple activities that query and modify data and that can also change the data definition.
-
Transaction boundaries can be defined either explicitly or implicitly.
-
A transaction explicitly is defined beginning with a
BEGIN TRAN(orBEGIN TRANSACTION) statement, and end explicitly with aCOMMIT TRANstatement to commit it and with aROLLBACK TRAN(orROLLBACK TRANSACTION) statement to undo its changes.BEGIN TRAN; INSERT INTO dbo.T1(keycol, col1, col2) VALUES(4, 101, 'C'); INSERT INTO dbo.T2(keycol, col1, col2) VALUES(4, 201, 'X'); COMMIT TRAN;
-
-
If the boundaries of a transaction isn’t marked explicitly, by default, SQL Server treats each individual statement as a transaction, which is known as an auto-commit mode.
-
Transactions have four properties—atomicity, consistency, isolation, and durability— abbreviated with the acronym ACID:
-
Atomicity: A transaction is an atomic unit of work. Either all changes in the transaction take place or none do.
-
If the system fails before a transaction is completed (before the commit instruction is recorded in the transaction log), upon restart, SQL Server undoes the changes that took place.
-
Also, if errors are encountered during the transaction and the error is considered severe enough, such as the target filegroup being full when trying to insert data, SQL Server automatically rolls back the transaction.
-
-
Consistency: The term consistency refers to the state of the data that the relational database management system (RDBMS) as concurrent transactions modify and query it, which is a subjective term, and depends on an application’s needs.
-
Isolation: Isolation ensures that transactions access only consistent data through a mechanism called isolation levels.
-
With disk-based tables, SQL Server supports two different models to handle isolation: one based purely on locking, and another based on a combination of locking and row versioning.
-
The model based on locking is the default in a box product.
In this model, readers require shared locks. If the current state of the data is inconsistent, readers are blocked until the state of the data becomes consistent.
-
The model based on locking and row versioning is the default in Azure SQL Database.
In this model, readers don’t take shared locks and don’t need to wait. If the current state of the data is inconsistent, the reader gets an older consistent state.
-
-
-
Durability: The durability property means that once a commit instruction is acknowledged by the database engine, the transaction’s changes are guaranteed to be durable—or in other words, persist—in the database.
-
A commit is acknowledged by getting control back to the application and running the next line of code.
-
Data changes are always written to the database’s transaction log on disk before they are written to the data portion of the database on disk.
-
After the commit instruction is recorded in the transaction log on disk, the transaction is considered durable even if the change hasn’t yet made it to the data portion on disk.
-
When the system starts, either normally or after a system failure, SQL Server runs a recovery process in each database that involves analyzing the log, then applying a redo phase, and then applying an undo phase.
-
The redo phase involves rolling forward (replaying) all the changes from any transaction whose commit instruction is written to the log but whose changes haven’t yet made it to the data portion.
-
The undo phase involves rolling back (undoing) the changes from any transaction whose commit instruction was not recorded in the log.
-
-
-
-- Start a new transaction
BEGIN TRAN;
-- Declare a variable
DECLARE @neworderid AS INT;
-- Insert a new order into the Sales.Orders table
INSERT INTO Sales.Orders
(custid, empid, orderdate, requireddate, shippeddate,
shipperid, freight, shipname, shipaddress, shipcity,
shippostalcode, shipcountry)
VALUES
(85, 5, '20220212', '20220301', '20220216',
3, 32.38, N'Ship to 85-B', N'6789 rue de l''Abbaye', N'Reims',
N'10345', N'France');
-- Save the new order ID in a variable
SET @neworderid = SCOPE_IDENTITY();
-- Return the new order ID
SELECT @neworderid AS neworderid;
-- Insert order lines for the new order into Sales.OrderDetails
INSERT INTO Sales.OrderDetails
(orderid, productid, unitprice, qty, discount)
VALUES(@neworderid, 11, 14.00, 12, 0.000),
(@neworderid, 42, 9.80, 10, 0.000),
(@neworderid, 72, 34.80, 5, 0.000);
-- Commit the transaction
COMMIT TRAN;12.1. Locks and Blocking
By default, a SQL Server box product uses a pure locking model to enforce the isolation property of transactions, whereas Azure SQL Database uses the row-versioning model by default.
-- turn off the database property READ_COMMITTED_SNAPSHOT to switch to the locking model as the default
ALTER DATABASE TSQLV6 SET READ_COMMITTED_SNAPSHOT OFF;12.1.1. Locks
Locks are control resources obtained by a transaction to guard data resources, preventing conflicting or incompatible access by other transactions.
12.1.1.1. Lock Modes and Compatibility
When trying to modify data, a transaction requests an exclusive lock on the data resource, regardless of the isolation level. If granted, the exclusive lock is held until the end of the transaction.
-
For single- statement transactions, this means that the lock is held until the statement completes.
-
For multistatement transactions, this means that the lock is held until all statements complete and the transaction is ended by a
COMMIT TRANorROLLBACK TRANcommand.
As for reading data, the defaults are different for a SQL Server box product and Azure SQL Database.
-
In SQL Server, the default isolation level is called
READ COMMITTED.In this isolation, when trying to read data, by default a transaction requests a shared lock on the data resource and releases the lock as soon as the read statement is done with that resource.
-
In Azure SQL Database, the default isolation level is called
READ COMMITTED SNAPSHOT.Instead of relying only on locking, this isolation level relies on a combination of locking and row versioning.
-
Under this isolation level, readers do not require shared locks, and therefore they never wait; they rely on the row-versioning technology to provide the expected isolation.
-
-
Under the
READ COMMITTEDisolation level, if a transaction modifies rows, until the transaction completes, another transaction can’t read the same rows.This approach to concurrency control is known as the pessimistic concurrency approach.
-
Under the
READ COMMITTED SNAPSHOTisolation level, if a transaction modifies rows, another transaction trying to read the data will get the last committed state of the rows that was available when the statement started.This approach to concurrency control is known as the optimistic concurrency approach.
READ COMMITTED SNAPSHOT is an MVCC-based implementation of the READ COMMITTED isolation level in SQL Server.
| Requested mode | Granted Exclusive (X) | Granted Shared (S) |
|---|---|---|
Exclusive |
No |
No |
Shared |
No |
Yes |
| A “No” in the intersection means that the locks are incompatible and the requested mode is denied; the requester must wait. A “Yes” in the intersection means that the locks are compatible and the requested mode is accepted. |
12.1.1.2. Lockable Resource Types
SQL Server can lock different types of resources that include rows (RID in a heap, key in an index), pages, objects (for example, tables), databases, and others. Rows reside within pages, and pages are the physical data blocks that contain table or index data.
To obtain a lock on a certain resource type, a transaction must first obtain intent locks of the same mode on higher levels of granularity to efficiently detect incompatible lock requests on higher levels of granularity and prevent the granting of those.
SQL Server determines dynamically which resource types to lock.
-
Naturally, for ideal concurrency, it’s best to lock only what needs to be locked—namely, only the affected rows.
-
However, locks require memory resources and internal management overhead. So SQL Server considers both concurrency and system resources when it’s choosing which resource types to lock.
-
When SQL Server estimates that a transaction will interact with a small number of rows, it tends to use row locks.
-
With larger numbers of rows, SQL Server tends to use page locks.
-
-
SQL Server might first acquire fine-grained locks (such as row or page locks) and, in certain circumstances, try to escalate the fine-grained locks to a table lock to preserve memory.
12.1.2. Blocking
When one transaction holds a lock on a data resource and another transaction requests an incompatible lock on the same resource, the request is blocked and the requester enters a wait state.
-
By default, the blocked request keeps waiting until the blocker releases the interfering lock.
-
To restrict the amount of time the session waits for a lock, set a session option called
LOCK_TIMEOUT. -
Specify a value in milliseconds—such as 5000 for 5 seconds, 0 for an immediate timeout, and –1 for no timeout (which is the default).
SET LOCK_TIMEOUT 5000; SELECT productid, unitprice FROM Production.Products WHERE productid = 2;Msg 1222, Level 16, State 51, Line 3 Lock request time out period exceeded. -
To remove the lock timeout value, set it back to the default (no timeout), and issue the query again.
SET LOCK_TIMEOUT -1; SELECT productid, unitprice FROM Production.Products WHERE productid = 2;
-
-
The dynamic management view (DMV)
sys.dm_tran_lockscan be used to get lock information, including both locks granted to sessions and locks sessions waiting for.-- Connection 1: hold exclusive lock to write BEGIN TRAN; UPDATE Production.Products SET unitprice += 1.00 WHERE productid = 2; -- no COMMIT TRAN or ROLLBACK TRAN, the transaction remains open, and the lock is still held-- Connection 2: needs a shared lock to read, but be blocked and has to wait SELECT productid, unitprice FROM Production.Products WHERE productid = 2;-- Connection 3 SELECT -- use * to explore other available attributes request_session_id AS sid, resource_type AS restype, resource_database_id AS dbid, DB_NAME(resource_database_id) AS dbname, resource_description AS res, resource_associated_entity_id AS resid, request_mode AS mode, request_status AS status FROM sys.dm_tran_locks;sid restype dbid dbname res resid mode status 52 DATABASE 6 TSQLV6 0 S GRANT 56 DATABASE 6 TSQLV6 0 S GRANT 59 DATABASE 6 TSQLV6 0 S GRANT 52 PAGE 6 TSQLV6 1:456 72057594046251008 IS GRANT 56 PAGE 6 TSQLV6 1:456 72057594046251008 IX GRANT 52 OBJECT 6 TSQLV6 1029578706 IS GRANT 56 OBJECT 6 TSQLV6 1029578706 IX GRANT 56 KEY 6 TSQLV6 (61a06abd401c) 72057594046251008 X GRANT 52 KEY 6 TSQLV6 (61a06abd401c) 72057594046251008 S WAIT-
Each session is identified by a unique session ID.
-
A session’s ID can be determined by querying the function
@@SPID. -
If working with SQL Server Management Studio, the session ID could be found in parentheses to the right of the login name in the status bar at the bottom of the query window that has the focus, and also in the caption of the connected query window.
-
-
By observing that both sessions lock a row with the same res and resid values, session 52 is waiting for a shared lock on a row in the sample database
TSQLV6that is being held as an exclusive lock by session 56. -
The involved table can be figured out by moving upward in the lock hierarchy for either session 52 or 56 and inspecting the intent locks on the object (table) where the row resides.
-
The
OBJECT_NAMEfunction can be used to translate the object ID (1029578706, in this example) that appears under the resid attribute in the object lock, that isProduction.Products.SELECT OBJECT_NAME(1029578706); -- Products -
The
sys.dm_tran_locksview gives the information about the IDs of the sessions involved in the blocking chain, that is, two or more sessions that are involved in the blocking situation, such as sessionxblocking sessiony, sessionyblocking sessionz, and so on—hence the use of the term chain.
-
-
The DMV
sys.dm_exec_connectionscan be used to get information about the connections associated with those session IDs and filter only the session IDs that are involved:SELECT -- use * to explore session_id AS sid, connect_time, last_read, last_write, most_recent_sql_handle FROM sys.dm_exec_connections WHERE session_id IN(52, 56);52 2025-01-13 14:50:57.367 2025-01-13 14:54:07.930 2025-01-13 14:54:07.923 0x0200000063FC7D052E09844778CDD615CFE7A2D1FB4118020000000000000000000000000000000000000000 56 2025-01-13 14:53:33.587 2025-01-13 14:53:52.560 2025-01-13 14:53:52.560 0x020000008FAC322CF2FC73472F8E93B0DF1994A69639ED090000000000000000000000000000000000000000-
A binary value holding a handle to the most recent SQL batch run by the connection.
-
The handle can be provided as an input parameter to a table function called
sys.dm_exec_sql_text, and the function returns the batch of code represented by the handle.SELECT session_id, text FROM sys.dm_exec_connections CROSS APPLY sys.dm_exec_sql_text(most_recent_sql_handle) AS ST WHERE session_id IN(52, 56);52 (@1 tinyint)SELECT [productid],[unitprice] FROM [Production].[Products] WHERE [productid]=@1 56 BEGIN TRAN; UPDATE Production.Products SET unitprice += 1.00 WHERE productid = 2; -
Starting with SQL Server 2016, the function
sys.dm_exec_input_bufferinstead ofsys.dm_exec_sql_textcan be used to get the code that the sessions of interest submitted last.SELECT session_id, event_info FROM sys.dm_exec_connections CROSS APPLY sys.dm_exec_input_buffer(session_id, NULL) AS IB WHERE session_id IN(52, 56);
-
-
-
The DMV
sys.dm_exec_sessionscan be used to find a lot of useful information about the sessions involved in a blocking situation.SELECT -- use * to explore session_id AS sid, login_time, host_name, program_name, login_name, nt_user_name, last_request_start_time, last_request_end_time FROM sys.dm_exec_sessions WHERE session_id IN(52, 56); -
Another DMV
sys.dm_exec_requestscan probably be used to find useful for troubleshooting blocking situations.SELECT -- use * to explore session_id AS sid, blocking_session_id, command, sql_handle, database_id, wait_type, wait_time, wait_resource FROM sys.dm_exec_requests WHERE blocking_session_id > 0; -
To terminate the blocker—for example, if realizing that as a result of a bug in the application the transaction remained open and nothing in the application can close it—do so by using the
KILL <session_id>command.KILL 56;
12.2. Isolation Levels
Isolation levels determine the level of consistency when interacting with data. In the default isolation level in a box product, a reader uses shared locks on the target resources and a writer uses exclusive locks.
-
SQL Server supports four isolation levels that are based on the pure locking model: READ UNCOMMITTED, READ COMMITTED (the default in a SQL Server box product), REPEATABLE READ, and SERIALIZABLE.
-
SQL Server also supports two isolation levels that are based on a combination of locking and row versioning: SNAPSHOT and READ COMMITTED SNAPSHOT (the default in Azure SQL Database).
SNAPSHOT and READ COMMITTED SNAPSHOT are in a sense the row-versioning counterparts of READ COMMITTED and SERIALIZABLE, respectively.
-
The isolation level of the whole session can be set by using the following command:
SET TRANSACTION ISOLATION LEVEL <isolationname>; -
The isolation level of a query can be set by using a table hint:
SELECT ... FROM <table> WITH (<isolationname>); -
With the first four isolation levels, the higher the isolation level, the stricter the locks are that readers request and the longer their duration is; therefore, the higher the isolation level is, the higher the consistency is and the lower the concurrency is.
-
With the two row-versioning-based isolation levels, SQL Server is able to store previous committed versions of rows in a version store. Readers do not request shared locks; instead, if the current version of the rows is not what they are supposed to see, SQL Server provides them with an older version.
Table 3. Isolation level properties Isolation level
Allows uncommitted reads?
Allows nonrepeatable reads?
Allows lost updates?
Allows phantom reads?
Detects update conflicts?
Uses row versioning?
READ UNCOMMITTED
Yes
Yes
Yes
Yes
No
No
READ COMMITTED
No
Yes
Yes
Yes
No
No
REPEATABLE READ
No
No
No
Yes
No
No
SERIALIZABLE
No
No
No
No
No
No
SNAPSHOT
No
No
No
No
Yes
Yes
READ COMMITTED SNAPSHOT
No
Yes
Yes
Yes
No
Yes
12.2.1. READ UNCOMMITTED
READ UNCOMMITTED is the lowest available isolation level, that is, a reader doesn’t ask for a shared lock.
-
A reader that doesn’t ask for a shared lock can never be in conflict with a writer that is holding an exclusive lock, so that the reader can read uncommitted changes (also known as dirty reads).
-
It also means the reader won’t interfere with a writer that asks for an exclusive lock, that is, a writer can change data while a reader that is running under the READ UNCOMMITTED isolation level reads data.
-
Open a transaction, update the unit price of product 2 by adding 1.00 to its current price (19.00), and then query the product’s row
-- Connection 1 BEGIN TRAN; UPDATE Production.Products SET unitprice += 1.00 WHERE productid = 2; SELECT productid, unitprice FROM Production.Products WHERE productid = 2;2 20.00 -
Set the isolation level to READ UNCOMMITTED and query the row for product 2.
The query returned the state of the row after the change, even though the change was not committed -- Connection 2 SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; SELECT productid, unitprice FROM Production.Products WHERE productid = 2;2 20.00 -
Keep in mind that Connection 1 might apply further changes to the row later in the transaction or even roll back at some point.
-- Connection 1 ROLLBACK TRAN; -
The above rollback undoes the update of product 2, changing its price back to 19.00. The value 20.00 that the reader got was never committed which is called dirty read.
-
12.2.2. READ COMMITTED
The lowest isolation level that prevents dirty reads is READ COMMITTED, which is also the default isolation level in SQL Server (the box product), to prevent uncommitted reads by requiring a reader to obtain a shared lock.
-- Connection 1
-- open a transaction, update the price of product 2, and query the row to show the new price
BEGIN TRAN;
UPDATE Production.Products
SET unitprice += 1.00
WHERE productid = 2;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;-- Connection 2
-- Keep in mind that this isolation level is the default, so unless previously changed the session’s isolation level, it isn't needed to set it explicitly.
-- The SELECT statement is currently blocked because it needs a shared lock to be able to read the row, and this shared lock request is in conflict with the exclusive lock held by the writer in Connection 1
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;-- Connection 1
-- commit the transaction
COMMIT TRAN;-- Connection 2
2 20.00-- restore the unitprice of the product 2
UPDATE Production.Products
SET unitprice -= 1.00 -- 19.00
WHERE productid = 2;In terms of the duration of locks, in the READ COMMITTED isolation level, a reader holds the shared lock only until it’s done with the resource.
-
It doesn’t keep the lock until the end of the transaction; in fact, it doesn’t even keep the lock until the end of the statement, that means that in between two reads of the same data resource in the same transaction, no lock is held on the resource.
-
Therefore, another transaction can modify the resource in between those two reads, and the reader might get different values in each read, which is called nonrepeatable reads or inconsistent analysis.
12.2.3. REPEATABLE READ
The isolation level REPEATABLE READ can be used to get repeatable reads, or consistent analysis to ensure that no one can change values in between reads that take place in the same transaction, that is, not only does a reader need a shared lock to be able to read, but it also holds the lock until the end of the transaction.
The REPEATABLE READ but not by lower isolation levels can also prevent another phenomenon called a lost update that happens when two transactions read a value, make calculations based on what they read, and then update the value.
-
In isolation levels lower than REPEATABLE READ no lock is held on the resource after the read, both transactions can update the value, and whichever transaction updates the value last “wins,” overwriting the other transaction’s update.
-
In REPEATABLE READ, both sides keep their shared locks after the first read, so neither can acquire an exclusive lock later in order to update, which results in a deadlock, and the update conflict is prevented.
-- Connection 1
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- keep holding a shared lock on the row for product 2
BEGIN TRAN;
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;2 19.00-- Connection 2
-- blocked the modifier’s request for an exclusive lock in conflict with the reader’s granted shared lock.
UPDATE Production.Products
SET unitprice += 1.00
WHERE productid = 2;-- Connection 1
-- the second read got the same unit price for product 2 as the first read
SELECT productid, unitprice
FROM Production.Products
WHERE productid = 2;
COMMIT TRAN; -- commit the transaction and release the shared lock-- Connection 2
-- obtain the exclusive lock it was waiting for and update the row12.2.4. SERIALIZABLE
Under the REPEATABLE READ isolation level, readers keep shared locks until the end of the transaction that locks only resources (e.g., rows) that the query found the first time it ran, not rows that weren’t there when the query ran, so that a second read in the same transaction might return new rows as well, which happens if, in between the reads, another transaction inserts new rows that satisfy the reader’s query filter, which are called phantoms, and such reads are called phantom reads.
The SERIALIZABLE isolation level can be used to prevent phantom reads, that requires a reader to obtain a shared lock on the whole range of keys that qualify for the query’s filter to be able to read, and it keeps the lock until the end of the transaction.
-- Connection 1
-- set the transaction isolation level to SERIALIZABLE, open a transaction, and query all products with category 1
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRAN
SELECT productid, productname, categoryid, unitprice
FROM Production.Products
WHERE categoryid = 1;-- Connection 2
-- In all isolation levels that are lower than SERIALIZABLE, such an attempt would be successful.
-- In the SERIALIZABLE isolation level, the attempt is blocked.
INSERT INTO Production.Products
(productname, supplierid, categoryid, unitprice, discontinued)
VALUES('Product ABCDE', 1, 1, 20.00, 0);sid restype dbid dbname res resid mode status
55 (Connection 1) KEY 6 TSQLV6 (61a06abd401c) 72057594046251008 RangeS-S GRANT
64 (Connection 2) KEY 6 TSQLV6 (61a06abd401c) 72057594046251008 X WAIT-- Connection 1
-- get the same output as before, with no phantoms
SELECT productid, productname, categoryid, unitprice
FROM Production.Products
WHERE categoryid = 1;
COMMIT TRAN; -- transaction is committed and the shared key-range lock is released12.2.5. Multi-Version Concurrency Control
With the row-versioning technology, SQL Server can store previous versions of committed rows in a version store.
-
If the Accelerated Database Recovery (ADR) feature is not enabled in the database, the version store resides in the tempdb database.
-
If ADR is enabled, the version store resides in the user database in question.
SQL Server supports two isolation levels, called SNAPSHOT and READ COMMITTED SNAPSHOT, that are based on this row-versioning technology.
-
The SNAPSHOT isolation level is logically similar to the SERIALIZABLE isolation level in terms of the types of consistency problems that can or cannot happen.
-
The READ COMMITTED SNAPSHOT isolation level is similar to the READ COMMITTED isolation level.
-
Readers using isolation levels based on row versioning do not acquire shared locks, so they don’t wait when the requested data is exclusively locked.
-
In other words, readers don’t block writers and writers don’t block readers.
-
Readers still get levels of consistency similar to SERIALIZABLE and READ COMMITTED.
-
SQL Server provides readers with an older version of the row if the current version is not the one they are supposed to see.
-
|
Note that if enabling any of the row-versioning-based isolation levels (which are enabled in Azure SQL Database by default), the DELETE and UPDATE statements need to copy the version of the row before the change to the version store (Copy-on-Write); INSERT statements don’t need to write anything to the version store, because no earlier version of the row exists. But it’s important to be aware that enabling any of the isolation levels that are based on row versioning might have a negative impact on the performance of updates and deletes. The performance of readers usually improves, sometimes dramatically, because they do not acquire shared locks and don’t need to wait when data is exclusively locked or its version is not the expected one. |
12.2.5.1. SNAPSHOT
The SNAPSHOT isolation level, relies on row versioning instead of using shared locks, guarantees the reader to get the last committed version of the row that was available when the transaction started to get committed reads and repeatable reads, and not phantom reads.
To work with the SNAPSHOT isolation level in a SQL Server box product instance (enabled by default in Azure SQL Database), first enable the option at the database level by running the following code in any open query window:
ALTER DATABASE TSQLV6 SET ALLOW_SNAPSHOT_ISOLATION ON;-
Open a transaction, update the price of product
2by adding1.00to its current price of19.00, and show the new price.-- Connection 1 BEGIN TRAN; UPDATE Production.Products SET unitprice += 1.00 WHERE productid = 2; SELECT productid, unitprice FROM Production.Products WHERE productid = 2;2 20.00 -
If someone begins a transaction using the SNAPSHOT isolation level, that session can request the version before the update.
-- Connection 2 SET TRANSACTION ISOLATION LEVEL SNAPSHOT; BEGIN TRAN; SELECT productid, unitprice FROM Production.Products WHERE productid = 2;2 19.00 -
If a transaction were under the SERIALIZABLE isolation level, the query would be blocked.
-- Connection 3 SET TRANSACTION ISOLATION LEVEL READ COMMITTED; -- by default in SQL Server SET LOCK_TIMEOUT 5000; SELECT productid, unitprice FROM Production.Products WHERE productid = 2;Msg 1222, Level 16, State 51, Line 5 Lock request time out period exceeded. -
Go back to Connection 1, and commit the transaction.
-- at this point, the current version of the row with the price of 20.00 is a committed version. COMMIT TRAN; -
Go back to Connection 2, and run the following code.
-- still get the last committed version of the row that was available when the transaction started (with a price of 19.00). SELECT productid, unitprice FROM Production.Products WHERE productid = 2; COMMIT TRAN;2 19.00
12.2.5.2. Conflict Detection
The SNAPSHOT isolation level prevents update conflicts, but unlike the REPEATABLE READ and SERIALIZABLE isolation levels that do so by generating a deadlock, the SNAPSHOT isolation level generates a more specific error, indicating that an update conflict was detected by examining the version store to figure out whether another transaction modified the data between a read and a write that took place in a transaction.
-
Set the transaction isolation level to SNAPSHOT, open a transaction, and read the row for product
2.-- Connection 1 SET TRANSACTION ISOLATION LEVEL SNAPSHOT; BEGIN TRAN; SELECT productid, unitprice FROM Production.Products WHERE productid = 2;2 19.00 -
Update the price of the product queried previously to
20.00, and commit the transaction.-- Connection 1 UPDATE Production.Products SET unitprice = 20.00 WHERE productid = 2; COMMIT TRAN;No other transaction modified the row between the read, calculation, and write; therefore, there was no update conflict and SQL Server allowed the update to take place.
-
Restore the price of product
2back to19.00:UPDATE Production.Products SET unitprice = 19.00 WHERE productid = 2; -
Next, run the following code in Connection 1, again, to open a transaction, and read the row for product
2:-- Connection 1 BEGIN TRAN; SELECT productid, unitprice FROM Production.Products WHERE productid = 2; -
Next, run the following code in Connection 2 to update the price of product
2to25.00:-- Connection 2 UPDATE Production.Products SET unitprice = 25.00 WHERE productid = 2; -
Go back to Connection 1, and try to update the price of the product to
20.00:UPDATE Production.Products SET unitprice = 20.00 WHERE productid = 2;SQL Server detected that this time another transaction modified the data between the read and write; therefore, it fails the transaction with the following error:
Msg 3960, Level 16, State 2, Line 1 Snapshot isolation transaction aborted due to update conflict. You cannot use snapshot isolation to access table 'Production.Products' directly or indirectly in database 'TSQLV6' to update, delete, or insert the row that has been modified or deleted by another transaction. Retry the transaction or change the isolation level for the update/delete statement.
12.2.5.3. READ COMMITTED SNAPSHOT
The READ COMMITTED SNAPSHOT isolation level is also based on row versioning, but differs from the SNAPSHOT isolation level in that instead of providing a reader with a transaction-level consistent view of the data, it provides the reader with a statement-level consistent view of the data, and also does not detect update conflicts.
To make a reader to acquire a shared lock under READ COMMITTED SNAPSHOT, add a table hint called READCOMMITTEDLOCK to the SELECT statements, as in SELECT * FROM dbo.T1 WITH (READCOMMITTEDLOCK).
To enable the use of the READ COMMITTED SNAPSHOT isolation level in a SQL Server box product (enabled by default in Azure SQL Database), turn on a database option called READ_COMMITTED_SNAPSHOT.
ALTER DATABASE TSQLV6 SET READ_COMMITTED_SNAPSHOT ON;| Unlike the SNAPSHOT isolation level, this flag changes the meaning, or semantics, of the READ COMMITTED isolation level to READ COMMITTED SNAPSHOT, which means that when this database flag is turned on, unless explicitly changing the session’s isolation level, READ COMMITTED SNAPSHOT is the default. |
-
Run the following code in Connection 1 to open a transaction, update the row for product
2, and read the row, leaving the transaction open:-- Connection 1 BEGIN TRAN; UPDATE Production.Products SET unitprice += 1.00 WHERE productid = 2; SELECT productid, unitprice FROM Production.Products WHERE productid = 2;2 20.00 -
In Connection 2, open a transaction and read the row for product 2, leaving the transaction open:
-- Connection 2 BEGIN TRAN; SELECT productid, unitprice FROM Production.Products WHERE productid = 2;2 19.00 -
Run the following code in Connection 1 to commit the transaction:
-- Connection 1 COMMIT TRAN; -
Now run the code in Connection 2 to read the row for product
2again, and commit the transaction:-- Connection 2 -- get the last committed version of the row that was available when the statement started (20.00) and not when the transaction started (19.00) SELECT productid, unitprice FROM Production.Products WHERE productid = 2; COMMIT TRAN;2 19.00 -
Close all connections. Open a new connection, and run the following code to disable the isolation levels that are based on row versioning in the
TSQLV6database:ALTER DATABASE TSQLV6 SET ALLOW_SNAPSHOT_ISOLATION OFF; ALTER DATABASE TSQLV6 SET READ_COMMITTED_SNAPSHOT OFF;
12.3. Deadlocks
A deadlock is a situation in which two or more sessions block each other.
-
An example of a two- session deadlock is when session A blocks session B and session B blocks session A.
-
An example of a deadlock involving more than two sessions is when session A blocks session B, session B blocks session C, and session C blocks session A.
-
In any of these cases, SQL Server detects the deadlock and intervenes by terminating one of the transactions.
-
If SQL Server did not intervene, the sessions involved would remain deadlocked forever.
Unless otherwise specified (DEADLOCK_PRIORITY), SQL Server chooses to terminate the transaction that did the least work (based on the activity written to the transaction log), because rolling that transaction’s work back is the cheapest option.
-
Run the following code in Connection 1 to open a new transaction, update a row in the
Production.Productstable for product2, and leave the transaction open:-- Connection 1 BEGIN TRAN; UPDATE Production.Products SET unitprice += 1.00 WHERE productid = 2; -
Run the following code in Connection 2 to open a new transaction, update a row in the
Sales.OrderDetailstable for product2, and leave the transaction open:-- Connection 2 BEGIN TRAN; UPDATE Sales.OrderDetails SET unitprice += 1.00 WHERE productid = 2; -
Run the following code in Connection 1 to attempt to query the rows for product
2in theSales.OrderDetailstable, and commit the transaction:-- Connection 1 -- needs a shared lock to be able to perform its read, but blocked by Connection 2 SELECT orderid, productid, unitprice FROM Sales.OrderDetails WHERE productid = 2; COMMIT TRAN; -
Next, run the following code in Connection 2 to attempt to query the row for product
2in theProduction.Productstable and commit the transaction:-- Connection 2 -- needs a shared lock to be able to perform its read, but blocked by Connection 1 SELECT productid, unitprice FROM Production.Products WHERE productid = 2; COMMIT TRAN; -
At this point, each of the sessions blocks the other —results a deadlock. SQL Server identifies the deadlock (typically within a few seconds), chooses one of the sessions involved as the deadlock victim, and terminates its transaction with the following error:
Msg 1205, Level 13, State 51, Line 3 Transaction (Process ID 57) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
Deadlocks are expensive because they involve undoing work that has already been done and then, usually with some error-handling logic, redoing the work.
-
Obviously, the longer the transactions are, the longer locks are kept, increasing the probability of deadlocks.
-
Keep transactions as short as possible, taking activities out of the transaction that aren’t logically supposed to be part of the same unit of work. For example, don’t use transactions that require user input to finish!
-
-
One typical deadlock, also called a deadly embrace deadlock (e.g., the above example), happens when transactions access resources in inverse order.
-
By swapping the order in one of the transactions, you can prevent this type of deadlock from happening—assuming that it makes no logical difference to your application.
-
-
Deadlocks often also happen when there is no real logical conflict (for example, trying to access the same rows), because of a lack of good indexing to support query filters.
For example, suppose both statements in the transaction in Connection 2 filtered product 5.
-
Now that the statements in Connection 1 handle product 2 and the statements in Connection 2 handle product 5, there shouldn’t be any conflict.
-
However, if indexes aren’t defined on the
productidcolumn in the tables to support the filter, SQL Server has to scan (and lock) all rows in the table, that is, of course, can lead to a deadlock.While scanning the entire table, both connections might attempt to acquire locks on the same or overlapping table pages, leading to a deadlock situation even though they are working with different product data.
-
In short, good index design can help mitigate the occurrences of deadlocks that have no real logical conflict.
-
-
Another option to consider to mitigate deadlock occurrences is the choice of isolation level.
-
The SELECT statements in the example needed shared locks because they ran under the READ COMMITTED isolation level.
-
If using the READ COMMITTED SNAPSHOT isolation level, readers will not need shared locks, and deadlocks that evolve because of the involvement of shared locks can be eliminated.
-
13. Programmable Objects
Programmable objects in SQL Server are reusable code blocks that extend the capabilities of the database beyond basic data storage and retrieval.
13.1. Variables
A variable is used to temporarily store data values for later use in the same batch in which they were declared, and a batch is one or more T-SQL statements sent to Microsoft SQL Server for execution as a single unit.
-
Use a
DECLAREstatement to declare one or more variables, and use aSETstatement to assign a value to a single variable.-- declares two variables called @i and @j of INT data type and assigns it the value 10 and 20 DECLARE @i AS INT, @j AS INT; -- SET statement can operate on only one variable at a time SET @i = 10; SEt @j = 20; -
Alternatively, a variable can be declared and initialized in the same statement, like this:
DECLARE @i AS INT = 10, @j AS INT = 20; -
When assign a value to a scalar variable, the value must be the result of a scalar expression.
DECLARE @empname AS NVARCHAR(61); -- a scalar subquery SET @empname = (SELECT firstname + N' ' + lastname FROM HR.Employees WHERE empid = 3);-- a scalar subquery fails at run time if it returns more than one value DECLARE @empname AS NVARCHAR(61); SET @empname = (SELECT firstname + N' ' + lastname FROM HR.Employees WHERE mgrid = 2);Msg 512, Level 16, State 1, Line 2 Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression. -
T-SQL also supports a nonstandard assignment
SELECTstatement to query data and assign multiple values obtained from the same row to multiple variables by using a single statement.DECLARE @firstname AS NVARCHAR(20), @lastname AS NVARCHAR(40); -- if the query has more than one qualifying row, the values in the variables are those from the last row that SQL Server happened to access. SELECT @firstname = firstname, @lastname = lastname FROM HR.Employees WHERE empid = 3; SELECT @firstname AS firstname, @lastname AS lastname;
13.2. Batchs
A batch is one or more T-SQL statements sent by a client application to SQL Server for execution as a single unit.
| A transaction is an atomic unit of work. A batch can have multiple transactions, and a transaction can be submitted in parts as multiple batches. |
-
Client application programming interfaces (APIs) such as ADO.NET provide methods for submitting a batch of code to SQL Server for execution.
-
SQL Server utilities such as SQL Server Management Studio (SSMS), Azure Data Studio (ADS), SQLCMD, and OSQL provide a client tool command called
GOthat signals the end of a batch.
Note that the GO command is a client tool command and not a T-SQL server command, and do not terminate the GO command with a semicolon.
|
-
A batch is a set of commands that are parsed and executed as a unit.
-
If the parsing is successful, SQL Server then attempts to execute the batch.
-
In the event of a syntax error in the batch, the whole batch is not submitted to SQL Server for execution.
-- Valid batch PRINT 'First batch'; USE TSQLV6; GO -- Invalid batch PRINT 'Second batch'; SELECT custid FROM Sales.Customers; SELECT orderid FOM Sales.Orders; GO -- Valid batch PRINT 'Third batch'; SELECT empid FROM HR.Employees;First batch Msg 102, Level 15, State 1, Line 8 Incorrect syntax near 'Sales'. Third batch
-
-
A variable is local to the batch in which it’s defined, that is, it can’t be referred to in another batch.
DECLARE @i AS INT = 10; -- Succeeds PRINT @i; GO -- Fails PRINT @i;10 Msg 137, Level 15, State 2, Line 6 Must declare the scalar variable "@i". -
The CREATE statements cannot be combined with other statements in the same batch.
-- CREATE DEFAULT, CREATE FUNCTION, CREATE PROCEDURE, CREATE RULE, CREATE SCHEMA, CREATE TRIGGER, and CREATE VIEW DROP VIEW IF EXISTS Sales.MyView; -- GO -- To get around the problem, add a GO command here CREATE VIEW Sales.MyView AS SELECT YEAR(orderdate) AS orderyear, COUNT (*) AS numorders FROM Sales.Orders GROUP BY YEAR(orderdate); GOMsg 111, Level 15, State 1, Line 3 'CREATE VIEW' must be the first statement in a query batch. -
A batch is a unit of resolution (also known as binding), that means that checking the existence of objects and columns happens at the batch level.
When applying schema changes to an object and try to manipulate the object data in the same batch, SQL Server might not be aware of the schema changes yet and fail the data-manipulation statement with a resolution error.
DROP TABLE IF EXISTS dbo.T1; CREATE TABLE dbo.T1(col1 INT); GO ALTER TABLE dbo.T1 ADD col2 INT; -- GO -- To get around the problem, add a GO command here SELECT col1, col2 FROM dbo.T1; -- Invalid column name 'col2'. GO DROP TABLE IF EXISTS dbo.T1; -
The
GOcommand is not really a T-SQL command; it’s actually a command used by SQL Server’s client tools, such as SSMS, to denote the end of a batch. It also supports an argument indicating how many times you want to execute the batch.DROP TABLE IF EXISTS dbo.T1; CREATE TABLE dbo.T1(col1 INT IDENTITY); GO SET NOCOUNT ON; INSERT INTO dbo.T1 DEFAULT VALUES; GO 100 SELECT SUM(col1) FROM dbo.T1; -- (1 + 100) * 100 / 2 = 5050 GO DROP TABLE IF EXISTS dbo.T1;
13.3. Flow Elements: IF and WHILE
T-SQL provides basic forms of control with flow elements to control the flow of the code, including the IF . . . ELSE element and the WHILE element.
-
The
IF . . . ELSEelement is used to control the flow of a code based on the result of a predicate.IF YEAR(SYSDATETIME()) <> YEAR(DATEADD(day, 1, SYSDATETIME())) -- a statement or statement block that is executed if the predicate is TRUE PRINT 'Today is the last day of the year.'; -- optionally a statement or statement block that is executed if the predicate is FALSE or UNKNOWN. ELSE BEGIN -- mark the boundaries of a statement block with the BEGIN and END keywords IF MONTH(SYSDATETIME()) <> MONTH(DATEADD(day, 1, SYSDATETIME())) PRINT 'Today is the last day of the month but not the last day of the year.'; ELSE PRINT 'Today is not the last day of the month.'; ENDDECLARE @score AS INT = CAST(RAND() * 100 AS INT); IF @score > 90 PRINT 'A'; ELSE IF @score > 80 PRINT 'B'; ELSE IF @score > 70 PRINT 'C'; ELSE IF @score > 60 PRINT 'D'; ELSE PRINT 'F';-- CASE is expression, instead of statement DECLARE @score AS INT = CAST(RAND() * 100 AS INT); SELECT CASE WHEN @score >= 90 THEN 'A' WHEN @score >= 80 THEN 'B' WHEN @score >= 70 THEN 'C' WHEN @score >= 60 THEN 'D' ELSE 'F' END AS Grade; -
The
WHILEelement executes a statement or statement block repeatedly while the predicate specified after theWHILEkeyword isTRUE, otherwise, the loop terminates when the predicate isFALSEorUNKNOWN.DECLARE @i AS INT = 0; WHILE @i <= 10 BEGIN SET @i = @i + 1; IF @i = 3 CONTINUE; -- skip the rest of the activity in the current iteration and evaluate the loop’s predicate again PRINT @i; IF @i = 7 BREAK; -- break out of the current loop and proceed to execute the statement that appears after the loop’s body END;
13.4. Cursors
SQL and T-SQL also support an object called cursor to process rows from a result of a query one at a time and in a requested order.
-
Primarily, the use of cursors contradicts the fundamental principles of the relational model, which is grounded in set theory.
-
Cursors, due to their record-by-record processing, incur significant overhead compared to set-based operations, resulting in significantly slower execution times even for similar underlying physical processing.
-
Cursor solutions, being imperative, tend to be longer, less readable, and harder to maintain than the declarative set solutions.
Working with a cursor generally involves the following steps:
-
Declare the cursor based on a query.
-
Open the cursor.
-
Fetch attribute values from the first cursor record into variables.
-
While not reaching the end of the cursor (the value of a function called
@@FETCH_STATUSis0), loop through the cursor records.In each iteration of the loop, perform the processing needed for the current row, and then fetch the attribute values from the next row into the variables.
-
Close the cursor.
-
Deallocate the cursor.
DROP VIEW IF EXISTS Sales.CustOrders; GO CREATE VIEW Sales.CustOrders AS SELECT DISTINCT O.custid, O.orderdate AS ordermonth, SUM(OD.qty) AS qty FROM Sales.Orders AS O INNER JOIN Sales.OrderDetails AS OD ON O.orderid = OD.orderid GROUP BY o.custid, O.orderdate GO-- Suppress messages indicating how many rows were affected SET NOCOUNT ON; -- Declare table variable to hold the final result DECLARE @Result AS TABLE ( custid INT, ordermonth DATE, qty INT, runqty INT, PRIMARY KEY(custid, ordermonth) ); -- Declare local variables that are used to store intermediate variables DECLARE @custid AS INT, @prvcustid AS INT, @ordermonth AS DATE, @qty AS INT, @runqty AS INT; -- Step 1: Declare the cursor based on a query DECLARE C CURSOR FAST_FORWARD /* read only, forward only */ FOR SELECT custid, ordermonth, qty FROM Sales.CustOrders ORDER BY custid, ordermonth; -- Step 2: Open the cursor OPEN C; -- Step 3: Fetch attribute values from the first cursor record into variables FETCH NEXT FROM C INTO @custid, @ordermonth, @qty; -- Initialize variables SELECT @prvcustid = @custid, @runqty = 0; -- Step 4: Loop through the cursor records while last fetch was -- In each iteration: -- Reset variables if customer ID changes -- Compute current running total and insert into table -- Fetch next cursor record WHILE @@FETCH_STATUS = 0 BEGIN IF @custid <> @prvcustid SELECT @prvcustid = @custid, @runqty = 0; SET @runqty = @runqty + @qty; INSERT INTO @Result VALUES(@custid, @ordermonth, @qty, @runqty); FETCH NEXT FROM C INTO @custid, @ordermonth, @qty; END; -- Step 5: Close the cursor CLOSE C; -- Step 6: Deallocate the cursor DEALLOCATE C; -- Enable showing messages indicating how many rows were affected SET NOCOUNT OFF; -- Query the table variable to return the final result SELECT custid, CONVERT(VARCHAR(7), ordermonth, 121) AS ordermonth, qty, runqty FROM @Result ORDER BY custid, ordermonth;-- address the same task with a window function SELECT custid, ordermonth, qty, SUM(qty) OVER(PARTITION BY custid ORDER BY ordermonth ROWS UNBOUNDED PRECEDING) AS runqty FROM Sales.CustOrders ORDER BY custid, ordermonth;
13.5. Temporary Tables
Temporary tables are temporary storage structures within a SQL Server database. Unlike permanent tables, they are designed for short-term data storage and have limited lifespans.
SQL Server supports three kinds of temporary tables to be more conveniental to work with than permanent tables in such cases: local temporary tables, global temporary tables, and table variables. All three kinds of temporary tables are created in the tempdb database.
It’s crucial to distinguish temporary tables (local, global, table variables) from system-versioned temporal tables.
-
Temporary Tables: Primarily used for temporary storage within a specific session or batch, often for intermediate results or data manipulation.
-
System-Versioned Temporal Tables: Specifically designed to track the history of data changes over time.
13.5.1. Local Temporary Tables
A local temporary table is created by naming it with a single number sign (#) as a prefix, such as #T1.
-
A local temporary table is visible only to the session that created it, in the creating level and all inner levels in the call stack (inner procedures, triggers, and dynamic batches).
-
A local temporary table is destroyed automatically by SQL Server when the creating level in the call stack goes out of scope.
-
A suffix is added to the table name by SQL Server internally that makes it unique in tempdb.
DROP TABLE IF EXISTS #MyOrderTotalsByYear; GO CREATE TABLE #MyOrderTotalsByYear ( orderyear INT NOT NULL PRIMARY KEY, qty INT NOT NULL ); INSERT INTO #MyOrderTotalsByYear(orderyear, qty) SELECT YEAR(O.orderdate) AS orderyear, SUM(OD.qty) AS qty FROM Sales.Orders AS O INNER JOIN Sales.OrderDetails AS OD ON OD.orderid = O.orderid GROUP BY YEAR(orderdate); SELECT Cur.orderyear, Cur.qty AS curyearqty, Prv.qty AS prvyearq FROM #MyOrderTotalsByYear AS Cur LEFT OUTER JOIN #MyOrderTotalsByYear AS Prv ON Cur.orderyear = Prv.orderyear + 1;-- clean up resources as soon as possible DROP TABLE IF EXISTS #MyOrderTotalsByYear;
13.5.2. Global Temporary Tables
A global temporary table is created by naming it with a double number sign (##) as a prefix, such as ##T1.
-
A global temporary table is visible to all other sessions.
-
A global temporary table is destroyed automatically by SQL Server when the creating session disconnects and there are no active references to the table.
-- creates a global temporary table called ##Globals with columns called id and val CREATE TABLE ##Globals ( id sysname NOT NULL PRIMARY KEY, val SQL_VARIANT NOT NULL );-- anyone can insert rows into the table. INSERT INTO ##Globals(id, val) VALUES(N'I', CAST(10 AS INT));-- anyone can modify and retrieve data from the table. SELECT val FROM ##Globals WHERE id = N'I';-- explicitly destroy the global temporary table DROP TABLE IF EXISTS ##Globals;
13.5.3. Table Variables
A table variable is a local, temporary table-like data structure declared within a single batch.
-
As with local temporary tables, table variables have a physical presence as a table in the tempdb database.
-
Like local temporary tables, table variables are visible only to the creating session, but because they are variables they have a more limited scope: only the current batch.
-
If an explicit transaction is rolled back, changes made to temporary tables in that transaction are rolled back as well; however, changes made to table variables by statements that completed in the transaction aren’t rolled back.
-
In terms of performance, usually it makes more sense to use table variables with small volumes of data (only a few rows) and to use local temporary tables otherwise.
DECLARE @MyOrderTotalsByYear TABLE ( orderyear INT NOT NULL PRIMARY KEY, qty INT NOT NULL ); INSERT INTO @MyOrderTotalsByYear(orderyear, qty) SELECT YEAR(O.orderdate) AS orderyear, SUM(OD.qty) AS qty FROM Sales.Orders AS O INNER JOIN Sales.OrderDetails AS OD ON OD.orderid = O.orderid GROUP BY YEAR(orderdate); SELECT Cur.orderyear, Cur.qty AS curyearqty, Prv.qty AS prvyearqty FROM @MyOrderTotalsByYear AS Cur LEFT OUTER JOIN @MyOrderTotalsByYear AS Prv ON Cur.orderyear = Prv.orderyear + 1;
|
A table type is a user-defined data structure that defines the schema (columns, data types) of a table to be reused as the table definition of table variables and input parameters of stored procedures and user-defined functions. |
13.6. Dynamic SQL
A dynamic SQL in SQL Server is a batch of T-SQL code as a character string that can be executed by using the EXEC command and the sp_executesql stored procedure.
-
The
EXEC(short forEXECUTE) command accepts a regular or Unicode character string in parentheses as input and executes the batch of code within the character string.DECLARE @sql AS VARCHAR(100); SET @sql = 'PRINT ''This message was printed by a dynamic SQL batch''' EXEC(@sql); -
The
sp_executesqlstored procedure is an alternative tool to theEXECcommand for executing dynamic SQL code.-
It’s more secure and more flexible in the sense that it has an interface; that is, it supports input and output parameters.
In terms of security, parameters that appear in the code cannot be considered part of the code—they can only be considered operands in expressions.
-
Note that unlike EXEC,
sp_executesqlsupports only Unicode character strings as the input batch of code. -
The
sp_executesqlstored procedure can perform better thanEXECbecause its parameterization aids in reusing cached execution plans, which incur cost when SQL Server needs to create them anew.-
An execution plan is the physical processing plan SQL Server produces for a query, with the set of instructions describing which objects to access, in what order, which indexes to use, how to access them, which join algorithms to use, and so on.
-
One of the requirements for reusing a previously cached plan is that the query string be the same as the one for which the cached plan was created.
DECLARE @sql AS NVARCHAR(100); SET @sql = N'SELECT orderid, custid, empid, orderdate FROM Sales.Orders WHERE orderid = @orderid;'; EXEC sp_executesql @stmt = @sql, -- a Unicode character string holding the batch of code @params = N'@orderid AS INT', -- a Unicode character string holding the declarations of input and output parameters @orderid = 10248; -- an input parameter called @orderid -
-
13.7. Routines
Routines are programmable objects that encapsulate code to calculate a result or to execute activity. SQL Server supports three types of routines: user-defined functions, stored procedures, and triggers.
13.7.1. User-defined Functions
A user-defined function (UDF) is used to encapsulate logic that calculates something, possibly based on input parameters, and return a result. SQL Server supports scalar and table-valued UDFs.
-
Scalar UDFs return a single value; table-valued UDFs return a table.
-
Scalar UDFs can appear anywhere in the query where an expression that returns a single value can appear (for example, in the
SELECTlist). -
Table UDFs can appear in the
FROMclause of a query. -
UDFs are not allowed to have any side effects, that means UDFs are not allowed to apply any schema or data changes in the database.
CREATE OR ALTER FUNCTION dbo.GetNewID() RETURNS UNIQUEIDENTIFIER AS BEGIN RETURN NEWID(); -- Invalid use of a side-effecting operator 'newid' within a function. END;-- create a UDF called dbo.GetAge that returns the age of a person DROP FUNCTION IF EXISTS dbo.GetAge; GO CREATE OR ALTER FUNCTION dbo.GetAge ( @birthdate AS DATE, -- a specified birth date (@birthdate argument) @eventdate AS DATE -- a specified event date (@eventdate argument) ) RETURNS INT AS BEGIN RETURN -- a RETURN clause that returns a value DATEDIFF(year, @birthdate, @eventdate) - CASE WHEN 100 * MONTH(@eventdate) + DAY(@eventdate) < 100 * MONTH(@birthdate) + DAY(@birthdate) THEN 1 ELSE 0 END; END; GO -- use a UDF in a query SELECT empid, firstname, lastname, birthdate, dbo.GetAge(birthdate, SYSDATETIME()) AS age FROM HR.Employees;
13.7.2. Stored Procedures
Stored procedures are routines that encapsulate logic with input and output parameters, return result sets of queries, and can have side effects.
-
Stored procedures encapsulate logic, allowing for centralized modification and ensuring all users utilize the updated implementation.
-
Stored procedures give better control of security.
-
A user permissions can be granted to execute the procedure without granting the user direct permissions to perform the underlying activities to ensure that all the required validations and auditing always take place.
-
Stored procedures with parameters can help prevent SQL injection.
-
-
All error-handling code can be incorporated within a procedure, silently taking corrective action where relevant.
-
Stored procedures give performance benefits.
-
Parameterized queries within stored procedures enhance performance by leveraging cached execution plans.
-
Stored procedures reduce network traffic by minimizing data exchange between the client and server.
-- create a stored procedure called Sales.GetCustomerOrders CREATE OR ALTER PROC Sales.GetCustomerOrders -- a customer ID (@custid) and a date range (@fromdate and @todate) as inputs @custid AS INT, @fromdate AS DATETIME = '19000101', -- default 19000101 @todate AS DATETIME = '99991231', -- default 99991231 @numrows AS INT OUTPUT -- the number of affected rows (@numrows) as an output AS SET NOCOUNT ON; -- suppress messages indicating affected rows by DML SELECT orderid, custid, empid, orderdate FROM Sales.Orders WHERE custid = @custid AND orderdate >= @fromdate AND orderdate < @todate; SET @numrows = @@rowcount;-- execute the procedure, and absorb the value of the output parameter @numrows in the variable @rc DECLARE @rc AS INT; EXEC Sales.GetCustomerOrders @custid = 1, @fromdate = '20210101', @todate = '20220101', @numrows = @rc OUTPUT; SELECT @rc AS numrows;Built-in System Stored ProceduresSQL Server provides several built-in system stored procedures that are useful for database administration, monitoring, and troubleshooting:
-
sp_helptext- Displays the definition of a user-defined database object (stored procedure, function, view, trigger, etc.).-- View the definition of a stored procedure EXEC sp_helptext 'Sales.GetCustomerOrders'; -- View the definition of a view EXEC sp_helptext 'Sales.OrderDetails'; -
sp_who2- Displays detailed information about current users, sessions, and processes running on the SQL Server instance.-- View all active sessions and processes EXEC sp_who2; -- View processes for a specific database EXEC sp_who2 @loginame = 'sa'; -
sp_lock- Displays information about active locks in the database.-- View all locks in the current database EXEC sp_lock; -- View locks for a specific session EXEC sp_lock @spid1 = 52; -
sp_monitor- Displays statistics about SQL Server performance, including CPU usage, I/O statistics, and network activity since SQL Server was last started or the statistics were reset.-- Display SQL Server performance statistics EXEC sp_monitor; -
sp_columns- Returns detailed information about the columns in a specific table or view, including data types, length, and nullability.-- View all columns for a specific table EXEC sp_columns @table_name = 'YourTableName'; -- View a specific column within a table EXEC sp_columns @table_name = 'YourTableName', @column_name = 'YourColumnName';
-
13.7.3. Triggers
A trigger is a special kind of stored procedure attached to an event—one that cannot be executed explicitly.
-
SQL Server supports the association of triggers with two kinds of events: data manipulation events (DML triggers) such as INSERT, and data definition events (DDL triggers) such as CREATE TABLE.
-
A trigger is considered part of the transaction that includes the event that caused the trigger to fire.
-
Triggers in SQL Server fire per statement and not per modified row.
13.7.3.1. DML Triggers
SQL Server supports two kinds of DML triggers: after and instead of.
-
An after trigger fires after the event it’s associated with finishes and can be defined only on permanent tables.
-
An instead of trigger fires instead of the event it’s associated with and can be defined on permanent tables and views.
In the trigger’s code, pseudo tables called inserted and deleted that contain the rows that were affected by the modification that caused the trigger to fire can be accessed.
-
The inserted table holds the new image of the affected rows in the case of INSERT and UPDATE actions.
-
The deleted table holds the old image of the affected rows in the case of DELETE and UPDATE actions.
-
In the case of instead of triggers, the inserted and deleted tables contain the rows that were supposed to be affected by the modification that caused the trigger to fire.
-- create a table called dbo.T1, and a table called dbo.T1_Audit
DROP TABLE IF EXISTS dbo.T1_Audit, dbo.T1;
CREATE TABLE dbo.T1
(
keycol INT NOT NULL PRIMARY KEY,
datacol VARCHAR(10) NOT NULL
);
CREATE TABLE dbo.T1_Audit
(
audit_lsn INT NOT NULL IDENTITY PRIMARY KEY, -- audit log serial number
dt DATETIME2(3) NOT NULL DEFAULT(SYSDATETIME()),
login_name sysname NOT NULL DEFAULT(ORIGINAL_LOGIN()),
keycol INT NOT NULL,
datacol VARCHAR(10) NOT NULL
);
GO
-- create the AFTER INSERT trigger trg_T1_insert_audit on the T1 table to audit insertions
CREATE OR ALTER TRIGGER trg_T1_insert_audit ON dbo.T1 AFTER INSERT
AS
SET NOCOUNT ON;
INSERT INTO dbo.T1_Audit(keycol, datacol)
SELECT keycol, datacol FROM inserted;
GO
-- trigger fires after each statement
INSERT INTO dbo.T1(keycol, datacol) VALUES(10, 'a');
INSERT INTO dbo.T1(keycol, datacol) VALUES(30, 'x');
INSERT INTO dbo.T1(keycol, datacol) VALUES(20, 'g');
GO
SELECT audit_lsn, dt, login_name, keycol, datacol
FROM dbo.T1_Audit;
-- 1 2025-01-15 16:03:50.997 sa 10 a
-- 2 2025-01-15 16:03:51.004 sa 30 x
-- 3 2025-01-15 16:03:51.008 sa 20 g
GO
-- cleanup
DROP TABLE dbo.T1_Audit, dbo.T1;13.7.3.2. DDL Triggers
SQL Server supports DDL triggers, which can be used for purposes such as auditing, policy enforcement, and change management.
-
SQL Server box product supports the creation of DDL triggers at two scopes, the database scope and the server scope, depending on the scope of the event.
-
Azure SQL Database currently supports only database triggers.
-
SQL Server supports only after DDL triggers; it doesn’t support instead of DDL triggers.
-
Within the trigger, information about the event that caused the trigger to fire can be obtained by querying a function called
EVENTDATA, which returns the event information as an XML instance.
-- creates the dbo.AuditDDLEvents table to hold the audit information
DROP TABLE IF EXISTS dbo.AuditDDLEvents;
CREATE TABLE dbo.AuditDDLEvents
(
audit_lsn INT NOT NULL IDENTITY,
posttime DATETIME2(3) NOT NULL,
eventtype sysname NOT NULL,
loginname sysname NOT NULL,
schemaname sysname NOT NULL,
objectname sysname NOT NULL,
targetobjectname sysname NULL,
eventdata XML NOT NULL,
CONSTRAINT PK_AuditDDLEvents PRIMARY KEY(audit_lsn)
);
GO
-- create the trg_audit_ddl_events audit trigger on the database by using the event group DDL_DATABASE_LEVEL_EVENTS
CREATE OR ALTER TRIGGER trg_audit_ddl_events
ON DATABASE FOR DDL_DATABASE_LEVEL_EVENTS
AS
SET NOCOUNT ON;
DECLARE @eventdata AS XML = eventdata();
INSERT INTO dbo.AuditDDLEvents(
posttime, eventtype, loginname, schemaname,
objectname, targetobjectname, eventdata)
VALUES(
@eventdata.value('(/EVENT_INSTANCE/PostTime)[1]', 'VARCHAR(23)'), -- XQuery expressions
@eventdata.value('(/EVENT_INSTANCE/EventType)[1]', 'sysname'),
@eventdata.value('(/EVENT_INSTANCE/LoginName)[1]', 'sysname'),
@eventdata.value('(/EVENT_INSTANCE/SchemaName)[1]', 'sysname'),
@eventdata.value('(/EVENT_INSTANCE/ObjectName)[1]', 'sysname'),
@eventdata.value('(/EVENT_INSTANCE/TargetObjectName)[1]', 'sysname'),
@eventdata);
GO
-- test the trigger
CREATE TABLE dbo.T1(col1 INT NOT NULL PRIMARY KEY);
ALTER TABLE dbo.T1 ADD col2 INT NULL;
ALTER TABLE dbo.T1 ALTER COLUMN col2 INT NOT NULL;
CREATE NONCLUSTERED INDEX idx1 ON dbo.T1(col2);
GO
SELECT * FROM dbo.AuditDDLEvents;
GO
-- cleanup
DROP TRIGGER IF EXISTS trg_audit_ddl_events ON DATABASE;
DROP TABLE IF EXISTS dbo.AuditDDLEvents, dbo.T1;13.8. Error Handling: TRY-CATCH
The TRY. . .CATCH construct in SQL Server handles errors by placing the usual T-SQL code in a TRY block and placing all the error-handling code in the adjacent CATCH block.
-
If the
TRYblock has no error, theCATCHblock is simply skipped. -
If the
TRYblock has an error, control is passed to the correspondingCATCHblock.BEGIN TRY -- TRY block (between the BEGIN TRY and END TRY keywords) PRINT 10/0; PRINT 'No error'; END TRY BEGIN CATCH -- CATCH block (between the BEGIN CATCH and END CATCH keywords) PRINT ' Error Message : ' + ERROR_MESSAGE(); PRINT ' Error Line : ' + CAST(ERROR_LINE() AS VARCHAR(10)); END CATCH;
SQL Server also provides a set of functions to get information about the error.
-
The
ERROR_NUMBERfunction returns an integer with the number of the error. -
The
ERROR_MESSAGEfunction returns error-message text.To get the list of error numbers and messages, query the
sys.messagescatalog view. -
The
ERROR_SEVERITYandERROR_STATEfunctions return the error severity and state. -
The
ERROR_LINEfunction returns the line number in the code where the error happened. -
The
ERROR_PROCEDUREfunction returns the name of the procedure in which the error happened and returnsNULLif the error did not happen within a procedure.-- create a table called dbo.Employees DROP TABLE IF EXISTS dbo.Employees; CREATE TABLE dbo.Employees ( empid INT NOT NULL, empname VARCHAR(25) NOT NULL, mgrid INT NULL, CONSTRAINT PK_Employees PRIMARY KEY(empid), CONSTRAINT CHK_Employees_empid CHECK(empid > 0), CONSTRAINT FK_Employees_Employees FOREIGN KEY(mgrid) REFERENCES dbo.Employees(empid) );BEGIN TRY INSERT INTO dbo.Employees(empid, empname, mgrid) VALUES(1, 'Emp1', NULL); -- Also try with empid = 0, 'A', NULL END TRY BEGIN CATCH IF ERROR_NUMBER() = 2627 BEGIN PRINT ' Handling PK violation...'; END; ELSE IF ERROR_NUMBER() = 547 BEGIN PRINT ' Handling CHECK/FK constraint violation...'; END; ELSE IF ERROR_NUMBER() = 515 BEGIN PRINT ' Handling NULL violation...'; END; ELSE IF ERROR_NUMBER() = 245 BEGIN PRINT ' Handling conversion error...'; END; ELSE BEGIN PRINT 'Re-throwing error...'; THROW; -- re-throws the error END; PRINT ' Error Number : ' + CAST(ERROR_NUMBER() AS VARCHAR(10)); PRINT ' Error Message : ' + ERROR_MESSAGE(); PRINT ' Error Severity: ' + CAST(ERROR_SEVERITY() AS VARCHAR(10)); PRINT ' Error State : ' + CAST(ERROR_STATE() AS VARCHAR(10)); PRINT ' Error Line : ' + CAST(ERROR_LINE() AS VARCHAR(10)); PRINT ' Error Proc : ' + COALESCE(ERROR_PROCEDURE(), 'Not within a procedure'); END CATCH;-- a stored procedure that encapsulates reusable error-handling code CREATE OR ALTER PROC dbo.ErrInsertHandler AS SET NOCOUNT ON; IF ERROR_NUMBER() = 2627 BEGIN PRINT 'Handling PK violation...'; END; ELSE IF ERROR_NUMBER() = 547 BEGIN PRINT 'Handling CHECK/FK constraint violation...'; END; ELSE IF ERROR_NUMBER() = 515 BEGIN PRINT 'Handling NULL violation...'; END; ELSE IF ERROR_NUMBER() = 245 BEGIN PRINT 'Handling conversion error...'; END; PRINT 'Error Number : ' + CAST(ERROR_NUMBER() AS VARCHAR(10)); PRINT 'Error Number : ' + CAST(ERROR_NUMBER() AS VARCHAR(10)); PRINT 'Error Message : ' + ERROR_MESSAGE(); PRINT 'Error Severity: ' + CAST(ERROR_SEVERITY() AS VARCHAR(10)); PRINT 'Error State : ' + CAST(ERROR_STATE() AS VARCHAR(10)); PRINT 'Error Line : ' + CAST(ERROR_LINE() AS VARCHAR(10)); PRINT 'Error Proc : ' + COALESCE(ERROR_PROCEDURE(), 'Not within a procedure'); GO BEGIN TRY INSERT INTO dbo.Employees(empid, empname, mgrid) VALUES(1, 'Emp1', NULL); END TRY BEGIN CATCH IF ERROR_NUMBER() IN (2627, 547, 515, 245) EXEC dbo.ErrInsertHandler; ELSE THROW; END CATCH; GO-- clean up DROP TABLE IF EXISTS dbo.Employees; DROP PROC IF EXISTS dbo.ErrInsertHandler;
14. JSON
JSON is a widely-used text format for data exchange in modern applications and for storing unstructured data. SQL Server 2016 and later versions provide built-in functions that integrate JSON with relational data, enabling the storage and querying of JSON documents within the database and the formatting of relational query results as JSON text.
|
A native |
14.1. ISJSON, JSON_VALUE, JSON_QUERY, and JSON_MODIFY
-
ISJSON()checks if a string contains valid JSON. -
JSON_VALUE()extracts a single scalar value (like a string or number). -
JSON_QUERY()extracts a JSON object or an array. -
JSON_MODIFY()updates a property within a JSON string and returns the new string.
These functions use a JavaScript-like path syntax to reference nested elements, and the extracted values can be used in any part of a T-SQL query, such as WHERE or ORDER BY clauses.
|
The path expressions for |
If the input JSON expression is NULL, all JSON functions will return NULL. However, if the input is not NULL but is an invalid JSON text, the functions will raise an error. It is a best practice to use ISJSON() to validate the input before applying other JSON functions.
|
-- Declare a variable to hold JSON data
DECLARE @person NVARCHAR(MAX) = '{ "name": "Jane Doe", "status": "Active", "location": { "city": "Belgrade", "country": "Serbia" }, "skills": [ "T-SQL", "Power BI" ] }';
-- Check if the JSON is valid before querying
IF ISJSON(@person) > 0
BEGIN
-- Extract values and use them in a SELECT statement
-- This uses the default 'lax' mode. A non-existent path would return NULL.
SELECT
JSON_VALUE(@person, '$.name') AS Name,
JSON_VALUE(@person, '$.location.city') AS City,
JSON_QUERY(@person, '$.skills') AS Skills,
JSON_VALUE(@person, '$.info.age') AS Age; -- This path doesn't exist, will return NULL
-- Using 'strict' mode will cause an error if the path is not found.
-- SELECT JSON_VALUE(@person, 'strict $.info.age'); -- This would raise an error.
-- Modify the city from "Belgrade" to "London"
SET @person = JSON_MODIFY(@person, '$.location.city', 'London');
-- Display the updated JSON
SELECT @person AS UpdatedPersonJSON;
END|
The |
14.2. OPENJSON
The OPENJSON rowset function transforms JSON text into a structured rowset to enable standard T-SQL querying, requiring database compatibility level 130 or higher. By default, the function returns first-level key/value pairs from a JSON object or all elements with their indexes from a JSON array.
It operates in two primary modes:
-
Default Schema (without a
WITHclause) returns a key-value table withkey,value, andtypecolumns, which is useful for inspecting a document’s structure.DECLARE @json NVARCHAR(MAX) = '{ "name": "John Doe", "age": 45, "isStudent": false, "skills": [ "SQL", "C#" ] }'; -- Use the default schema to return a key-value table SELECT * FROM OPENJSON(@json);Result Setkey value type --- name John Doe 1 age 45 2 isStudent false 0 skills ["SQL","C#"] 4 -
Explicit Schema (with a
WITHclause) shreds a JSON array into a relational format by mapping user-defined columns, data types, and JSON paths in an explicit schema definition.DECLARE @json NVARCHAR(MAX) = N'[ { "OrderNumber": "SO43659", "OrderDate": "2024-05-31", "Customer": "AW29825", "Quantity": 1 }, { "OrderNumber": "SO43661", "OrderDate": "2024-06-01", "Customer": "AW73565", "Quantity": 3 } ]'; -- Use an explicit schema to define the output table structure SELECT * FROM OPENJSON(@json) WITH ( Number VARCHAR(200) '$.OrderNumber', [Date] DATETIME '$.OrderDate', CustomerAcct VARCHAR(200) '$.Customer', Qty INT '$.Quantity' );Result SetNumber Date CustomerAcct Qty --- SO43659 2024-05-31 00:00:00.000 AW29825 1 SO43661 2024-06-01 00:00:00.000 AW73565 3 -
JSON documents might have sub-elements and hierarchical data that can’t be directly mapped into the standard relational columns. To flatten hierarchical JSON, a primary
OPENJSONcall extracts a nested array as a JSON text fragment using theAS JSONoption, which is then unnested by a secondOPENJSONcall via anAPPLYoperator.DECLARE @json NVARCHAR(MAX) = N'[ {"id": 2, "info": {"name": "John", "surname": "Smith"}, "age": 25}, {"id": 5, "info": {"name": "Jane", "surname": "Smith", "skills": ["SQL", "C#", "Azure"]}, "dob": "2005-11-04T12:00:00"} ]'; SELECT id, firstName, lastName, age, dateOfBirth, skill FROM OPENJSON(@json) WITH ( id INT 'strict $.id', firstName NVARCHAR(50) '$.info.name', lastName NVARCHAR(50) '$.info.surname', age INT, dateOfBirth DATETIME2 '$.dob', skills NVARCHAR(MAX) '$.info.skills' AS JSON ) OUTER APPLY OPENJSON(skills) WITH (skill NVARCHAR(8) '$');Result Setid firstName lastName age dateOfBirth skill --- 2 John Smith 25 NULL NULL 5 Jane Smith NULL 2005-11-04 12:00:00.0000000 SQL 5 Jane Smith NULL 2005-11-04 12:00:00.0000000 C# 5 Jane Smith NULL 2005-11-04 12:00:00.0000000 Azure
14.3. FOR JSON
The FOR JSON clause in a SELECT statement formats query results into JSON text, delegating the formatting task from the client application to the database.
It operates in two primary modes:
-
FOR JSON AUTOautomatically creates a nested JSON structure based on the tables used in theSELECTstatement and their join relationships. -
FOR JSON PATHprovides explicit control over the output format, allowing for the creation of custom nested objects and arrays using dot notation (i.e.,'Order.Details.ProductID') in column aliases.
Further customization is available through options like ROOT to add a top-level element, INCLUDE_NULL_VALUES to retain properties with null values, and WITHOUT_ARRAY_WRAPPER to remove the default surrounding array brackets, which is useful for generating a single JSON object from a single-row result.
SELECT TOP 2
SalesOrderID AS 'Order.ID',
OrderDate AS 'Order.Date',
AccountNumber AS 'Customer.Account'
FROM Sales.SalesOrderHeader
FOR JSON PATH, ROOT('Orders');{
"Orders": [
{
"Order": {
"ID": 43659,
"Date": "2011-05-31T00:00:00",
"Customer": {
"Account": "10-4020-000676"
}
}
},
{
"Order": {
"ID": 43660,
"Date": "2011-05-31T00:00:00",
"Customer": {
"Account": "10-4020-000117"
}
}
}
]
}15. Vectors and embeddings
The SQL Database Engine supports storing and querying structured and unstructured data, including performing vector search, which is beneficial for unified data search without external services.
-
Vectors are ordered arrays of numbers (typically floats) representing data (e.g., pixel values, text ASCII values).
-
Vectorization is the process of converting data into vectors, which are efficiently stored using the SQL Server
VECTORdata type.
| Vector features are available in SQL Server 2025 (17.x) Preview, Azure SQL Database, and Azure SQL Managed Instance (configured with the Always-up-to-date update policy). |
15.1. Embeddings
Embeddings are a specialized type of vector that capture important features of data, often generated by deep learning models, with the ability of representing semantic similarity between various data entities, such as words or images.
-
Azure OpenAI provides models for creating text embeddings, which can be stored in SQL Server alongside their data to enable vector search for similar data points.
-
Storing generated embeddings in a SQL Server database allows for co-location with the represented data and facilitates vector search queries to find similar data points.
15.2. Vector search
Vector search refers to the process of finding vectors in a dataset that are similar to a specific query vector.
-
Similarity is measured using distance metrics like cosine distance; closer vectors indicate higher similarity.
-
SQL Server provides built-in support for vectors via the
VECTORdata type, storing data in an optimized binary format yet is exposed as JSON arrays for convenience. -
Vectors, typically managed as arrays of floats, can be created by casting JSON arrays to the
VECTORdata type. For example:SELECT CAST('[1.0, -0.2, 30]' AS VECTOR(3)) AS v1, CAST(JSON_ARRAY(1.0, -0.2, 30) AS VECTOR(3)) AS v2; DECLARE @v1 VECTOR(3) = '[1.0, -0.2, 30]'; DECLARE @v2 VECTOR(3) = JSON_ARRAY(1.0, -0.2, 30); SELECT @v1 as v1, @v2 as v2; DECLARE @v VECTOR(3) = '[1.0, -0.2, 30]'; SELECT CAST(@v AS NVARCHAR(MAX)) AS s, CAST(@v AS JSON) AS j
15.2.1. Exact nearest neighbor (k-NN) search and vector distance
Exact search, also known as k-nearest neighbor (k-NN) search, involves calculating the distance between a given vector and all other vectors in a dataset, sorting the results, and selecting the closest neighbors based on a specified distance metric.
-
k-nearest neighbor (k-NN) search guarantees precise nearest neighbor retrieval by performing an exhaustive distance calculation across all indexed vectors, making it computationally intensive but suitable for smaller datasets or when accuracy is paramount.
-
Vector distance functions, such as Euclidean distance, cosine similarity, and dot product, measure vector closeness and are essential for accurate k-NN searches.
-
In the SQL Database Engine, k-NN searches utilize the
VECTOR_DISTANCEfunction for efficient distance calculation and nearest neighbor retrieval.
| The terms "exact search," "k-nearest neighbor (k-NN) search," and "exact nearest neighbor (ENN) vector search" are used interchangeably to refer to this precise, exhaustive search method. |
The following example shows how to do k-NN to return the top 10 most similar vectors stored in the content_vector table to the given query vector @qv.
DECLARE @qv VECTOR(1536) = AI_GENERATE_EMBEDDINGS(N'Pink Floyd music style' USE MODEL Ada2Embeddings);
SELECT TOP (10) id, VECTOR_DISTANCE('cosine', @qv, [content_vector]) AS distance, title
FROM [dbo].[wikipedia_articles_embeddings]
ORDER BY distance| Exact search is recommended for datasets with fewer than 50,000 vectors. Larger tables can use exact search if search predicates effectively reduce the number of vectors for neighbor search to 50,000 or fewer. |
15.2.2. Approximate nearest neighbors (ANN) and vector index
| Approximate vector index and vector search are in preview and currently only available in SQL Server 2025 (17.x) Preview. |
Approximate Nearest Neighbors (ANN) offers a high-performance alternative to the slow and resource-intensive exact k-nearest neighbors (k-NN) search. While k-NN requires comparing a query vector against every vector in a database, ANN trades a small degree of accuracy (recall) for a massive gain in search speed, making it a practical solution for large-scale vector search.
Recall is a metric that measures the proportion of relevant items successfully retrieved out of all truly relevant items.
-
In vector search, recall specifically quantifies how many of the exact nearest neighbors found by an exhaustive search are successfully identified by an Approximate Nearest Neighbors (ANN) algorithm.
-
It serves as a crucial measure of the approximation’s quality, with a perfect recall of 1 indicating that the ANN algorithm found all the exact nearest neighbors.
For AI applications, the inherent approximation of vector embeddings makes ANN a highly advantageous trade-off over exact k-NN, offering significant performance and resource benefits well-suited for operational databases.
A vector index is a data structure optimized for efficiently finding approximate nearest neighbors in high-dimensional vector spaces, thereby returning approximate results for ANN searches, unlike traditional relational database indexes (e.g., B-trees, LSM-trees) designed for exact lookups and range queries on scalar values.
In the SQL Database engine, vector indexes are based on the DiskANN algorithm.
-
DiskANN is a graph-based system that indexes and searches large vector datasets by creating a navigable graph to quickly find the closest match to a given vector.
-
DiskANN efficiently uses SSDs and minimal memory to handle significantly more data than in-memory indices, while maintaining high queries per second (QPS) and low latency, ensuring a balance between memory, CPU and I/O usage and search performance.
An approximate nearest neighbors algorithm search can be done first creating a vector index using the CREATE VECTOR INDEX T-SQL command and then using VECTOR_SEARCH T-SQL function to run the approximate search.
DECLARE @qv VECTOR(1536) = AI_GENERATE_EMBEDDINGS(N'Pink Floyd music style' USE MODEL Ada2Embeddings);
SELECT
t.id, s.distance, t.title
FROM
VECTOR_SEARCH(
TABLE = [dbo].[wikipedia_articles_embeddings] AS t,
COLUMN = [content_vector],
SIMILAR_TO = @qv,
METRIC = 'cosine',
TOP_N = 10
) AS s
ORDER BY s.distanceAppendix A: Data Types
A data type is an attribute that specifies the type of data that the object can hold: integer data, character data, monetary data, date and time data, binary strings, and so on. [3]
Data types can be converted either implicitly or explicitly.
-
Implicit conversions are not visible to the user. SQL Server automatically converts the data from one data type to another.
-
Explicit conversions use the
CASTorCONVERTfunctions.-
Use
CASTinstead ofCONVERTto write Transact-SQL program code to comply with ISO. -
Use
CONVERTinstead ofCASTto take advantage of the style functionality in CONVERT.CAST ( expression AS data_type [ ( length ) ] )CONVERT ( data_type [ ( length ) ] , expression [ , style ] )SELECT CAST(123 AS VARCHAR(10)), CONVERT(VARCHAR(10), 123) -- same result: integer to stringSELECT CONVERT(VARCHAR(10), GETDATE(), 101) -- date to string in MM/dd/yyyy format
-
A.1. Character
SQL Server supports two kinds of character data type pairs: regular kind (CHAR and VARCHAR) and N-kind (NCHAR and NVARCHAR).
Each of the type pairs can support different character encoding systems, and can result in different encoded byte lengths and on-disk storage sizes, based on the effective collation of the data and the character code range in use.
-
The regular types, with UTF-8 collation, use the UTF-8 encoding system and support full range of Unicode characters.
-
The N-kind types, with supplementary character collation (SC), use the UTF-16 encoding system and support the full range of Unicode characters. Otherwise, they support only the subset of characters from the UCS-2 character encoding system.
-
The
VARCHAR(size)defines the maximum size in bytes, while theNVARCHAR(size)defines the size in byte pairs. -
The literals of regular type character are enclosed in single quotes, while N-kind type require a preceding
'N'. -
Any data type without the
VARelement (CHAR,NCHAR) in its name has a fixed length, that is, SQL Server preserves the maximum space in the row based on the column’s defined size and not on the actual user data that is stored. -
A data type with the
VARelement (VARCHAR,NVARCHAR) in its name has a variable length, that is, SQL Server uses as much storage space in the row as required to store the actual character string, plus two extra bytes for offset data.-
Updates of variable-length data types can be less efficient than those of fixed-length types due to potential row expansion and data movement.
-
Variable-length data types can use the
MAXspecifier, allowing for up to 2GB per value. -
Any value with a size up to a certain threshold (8,000 bytes by default) can be stored inline in the row. Any value with a size above the threshold is stored external to the row as a large object (LOB).
-
-
The collation is a property of character data that encapsulates several aspects: language support, sort order, case sensitivity, accent sensitivity, and more.
-- get the set of supported collations and their descriptions SELECT name, description FROM sys.fn_helpcollations();-
In an on-premises SQL Server implementation and Azure SQL Managed Instance, collation can be defined at four different levels: instance, database, column, and expression. The lowest level is the effective one that is used.
SELECT DATABASEPROPERTYEX(DB_NAME(), 'Collation'); -- SQL_Latin1_General_CP1_CI_AS -
In Azure SQL Database, collation can be defined at the database, column, and expression levels.
-
-
T-SQL provides the plus-sign (
+) operator and theCONCATandCONCAT_WSfunctions to concatenate strings.SELECT empid, firstname + N' ' + lastname AS fullname FROM HR.Employees;-
Standard SQL dictates that a concatenation with a
NULLshould yield aNULL.SELECT custid, country, region, city, country + N',' + region + N',' + city AS location FROM Sales.Customers;custid country region city location 9 France NULL Marseille NULL 10 Canada BC Tsawassen Canada,BC,Tsawassen -
To treat a
NULLas an empty string—or more accurately, to substitute aNULLwith an empty string—use theCOALESCEfunction that accepts a list of input values and returns the first that is notNULL.SELECT custid, country, region, city, country + COALESCE(N',' + region, N'') + N',' + city AS location FROM Sales.Customers;custid country region city location 8 Spain NULL Madrid Spain,Madrid 9 France NULL Marseille France,Marseille -
T-SQL supports a function called
CONCAT, which accepts a list of inputs for concatenation and automatically substitutes NULLs with empty strings.SELECT custid, country, region, city, CONCAT(country, N',' + region, N',' + city) AS location FROM Sales.Customers; -
T-SQL also supports a function called
CONCAT_WS, which accepts the separator as the first parameter, specifying it only once, and then the list of inputs for concatenation.SELECT custid, country, region, city, CONCAT_WS(N',', country, region, city) AS location FROM Sales.Customers;
-
-
The
PATINDEXfunction returns the position of the first occurrence of a pattern, similar to the patterns used by theLIKEpredicate in T-SQL, within a string.PATINDEX(pattern, string)SELECT PATINDEX('%[0-9]%', 'abcd123efgh'); -- 5 -
T-SQL provides a predicate called
LIKEto check whether a character string matches a specified pattern.-
The
%(percent sign) wildcard represents a string of any size, including an empty string.SELECT empid, lastname FROM HR.Employees WHERE lastname LIKE N'D%';empid lastname 1 Davis 9 Doyle -
The
_(underscore) wildcard represents a single character.SELECT empid, lastname FROM HR.Employees WHERE lastname LIKE N'_e%';empid lastname 3 Lew 4 Peled -
The square bracket wildcard
[<list of characters>], with a list of characters (such as[ABC]), represents a single character that must be one of the characters specified in the list.SELECT empid, lastname FROM HR.Employees WHERE lastname LIKE N'[ABC]%';empid lastname 8 Cameron -
The square bracket wildcard
[<character>-<character>], with a character range (such as[A–E]), represents a single character that must be within the specified range.SELECT empid, lastname FROM HR.Employees WHERE lastname LIKE N'[A-E]%';empid lastname 8 Cameron 1 Davis 9 Doyle
-
-
The square bracket wildcard
[^<character list or range>], with a caret sign (^) followed by a character list or range (such as[^A–E]), represents a single character that is not in the specified character list or range.SELECT empid, lastname FROM HR.Employees WHERE lastname LIKE N'[^A-E]%';empid lastname 2 Funk 7 King -
To search for a character that is also a wildcard, use an escape character before it in the
LIKEpattern, and specify the escape character using theESCAPEkeyword.-
A character put in front of a wildcard character to indicate that the wildcard is interpreted as a regular character and not as a wildcard.
-
escape_characteris a character expression that has no default and must evaluate to only one character.-- specify character (!, @, $, or #) as the escape character col1 LIKE '%!_%' ESCAPE '!' col1 LIKE '%@_%' ESCAPE '@' col1 LIKE '%$%_' ESCAPE '$' col1 LIKE '%#%_' ESCAPE '#'
-
A.2. Date and Time
T-SQL supports six date and time data types:
-
The legacy types
DATETIMEandSMALLDATETIMEinclude date and time components that are inseparable.DATETIME 'YYYYMMDD hh:mm:ss.nnn' '20220212 12:30:15.123' DATETIME 'YYYYMMDD' '20220212' SMALLDATETIME 'YYYYMMDD hh:mm' '20220212 12:30' SMALLDATETIME 'YYYYMMDD' '20220212' -
The
DATEandTIMEdata types provide a separation between the date and time components.DATE 'YYYYMMDD' '20220212' TIME 'hh:mm:ss.nnnnnnn' '12:30:15.1234567' -
The
DATETIME2data type has a bigger date range and better precision than the legacy types.DATETIME2 'YYYYMMDD hh:mm:ss.nnnnnnn' '20220212 12:30:15.1234567' -
The
DATETIMEOFFSETdata type is similar toDATETIME2, but it also includes the offset from UTC.DATETIMEOFFSET 'YYYYMMDD hh:mm:ss.nnnnnnn [+|-]hh:mm' '20220212 12:30:15.1234567 +02:00'SELECT GETDATE() UNION ALL -- DATETIME current date and time SELECT CURRENT_TIMESTAMP UNION ALL -- DATETIME same as GETDATE but SQL-compliant SELECT GETUTCDATE() UNION ALL -- DATETIME current date and time in UTC SELECT SYSDATETIME() UNION ALL -- DATETIME2 current date and time SELECT SYSUTCDATETIME() UNION ALL -- DATETIME2 current date and time in UTC SELECT SYSDATETIMEOFFSET() -- DATETIME2 current date and time in UTC with Time Zone2025-01-18 15:07:52.9766667 +00:00 2025-01-18 15:07:52.9766667 +00:00 2025-01-18 07:07:52.9766667 +00:00 2025-01-18 15:07:52.9755919 +00:00 2025-01-18 07:07:52.9755919 +00:00 2025-01-18 15:07:52.9755919 +08:00
T-SQL doesn’t provide the means to express a date and time literal; instead, a convertible literal of a different type can be specified—explicitly or implicitly—to a date and time data type.
-
It is a best practice to use character strings with language-neutral formats to express date and time values.
SELECT orderid, custid, empid, orderdate FROM Sales.Orders WHERE orderdate = '20220212'; -- equivalent to: WHERE orderdate = CAST('20220212' AS DATE);-
Each login has a default language, which affects how date and time literals are interpreted.
SET LANGUAGE British; SELECT CAST('02/12/2022' AS DATE); -- 2022-12-02 SET LANGUAGE us_english; SELECT CAST('02/12/2022' AS DATE); -- 2022-02-12 -
The
DATEFORMATsetting, expressed as a combination of the charactersd,m, andy, determines how SQL Server interprets date and time literals from character strings (e.g.,'mdy'for US English,'dmy'for British English).SET DATEFORMAT dmy; SELECT CAST('02/12/2022' AS DATE); -- 2022-12-02 SET DATEFORMAT mdy; SELECT CAST('02/12/2022' AS DATE); -- 2022-02-12 -
The
LANGUAGE/DATEFORMATsetting affects only the way the values inputed are interpreted, and have no impact on the format used in the output for presentation purposes.
-
-
SQL Server may not efficiently utilize indexes when functions like
YEARare applied to the column within theWHEREclause.SELECT orderid, custid, empid, orderdate FROM Sales.Orders WHERE YEAR(orderdate) = 2021;-- better SELECT orderid, custid, empid, orderdate FROM Sales.Orders WHERE orderdate >= '20210101' AND orderdate < '20220101';
References
-
[1] Itzik Ben-Gan T-SQL Fundamentals. 3rd edition, Microsoft Press; August 3, 2016
-
[2] Itzik Ben-Gan, Adam Machanic, Dejan Sarka, Kevin Farlee T-SQL Querying. 1st Edition Microsoft Press; March 6, 2015
-
[3] https://learn.microsoft.com/en-us/sql/t-sql/language-reference