TCP/IP: TCP Data Flow and Window Management
We now examine the dynamics of TCP data transfers, focusing initially on interactive connections and then introducing flow control and associated window management procedures that are used in conjunction with congestion control for bulk data transfers (i.e., noninteractive communications).
An interactive TCP connection is one in which user input such as keystrokes, short messages, or joystick/mouse movements need to be delivered between a client and a server.
-
If small segments are used to carry such user input, the protocol imposes more overhead because there are fewer useful payload bytes per packet exchanged.
-
On the other hand, filling packets with more data usually requires them to be delayed, which can have a negative impact on delay-sensitive applications such as online games and collaboration tools.
1. Interactive Communication
Studies of TCP traffic usually find that 90% or more of all TCP segments contain bulk data (e.g., Web, file sharing, electronic mail, backups) and the remaining portion contains interactive data (e.g., remote login, network games).
-
Bulk data segments tend to be relatively large (1500 bytes or larger), while interactive data segments tend to be much smaller (tens of bytes of user data).
-
TCP handles both types of data using the same protocol and packet format, but different algorithms come into play for each.
Let us look at the flow of data when we type an interactive command on an ssh connection.
Secure shell (ssh) is a remote login protocol that provides strong security (privacy and authentication based on cryptography). It has mostly replaced the earlier UNIX rlogin and Telnet programs that provide remote login service but without strong security.
|
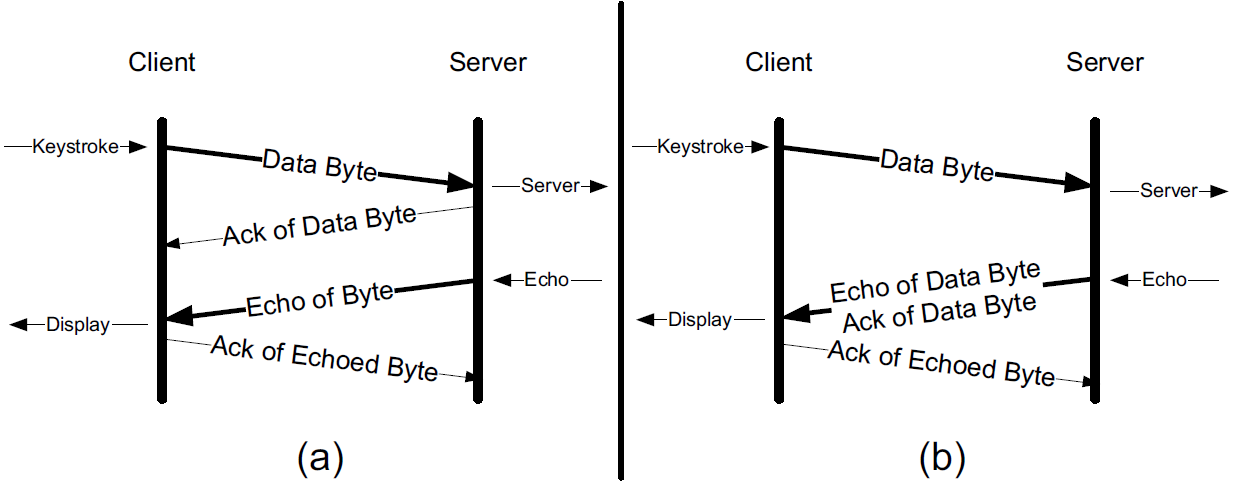
2. Delayed Acknowledgments
In many cases, TCP does not provide an ACK for every incoming packet because of TCP’s cumulative ACK field.
Using a cumulative ACK allows TCP to intentionally delay sending an ACK for some amount of time, in the hope that it can combine the ACK it needs to send with some data the local application wishes to send in the other direction, that is a form of piggybacking which is used most often in conjunction with bulk data transfers.
|
The Host Requirements RFC [RFC1122] states that TCP should implement a delayed ACK but the delay must be less than 500ms. Many implementations use a maximum of 200ms. |
Delaying ACKs causes less traffic to be carried over the network than when ACKs are not delayed because fewer ACKs are used.
Linux uses a dynamic adjustment algorithm whereby it can change between ACKing every segment (called quickack mode) and conventional delayed ACK mode.
|
On Red Hat Enterprise Linux, there are two modes used by TCP to acknowledge data reception: [RHELDELACK]
TCP switches between the two modes depending on the current congestion. |
|
* The TCP Delayed Acknowledgment (also called Delayed ACK) is another technique used to mitigate network congestion, this time by reducing the number of acknowledgement (ACK) packets sent. Instead of sending an ACK for each received packet, the receiver may wait for a short time (typically around 200 ms) to see if it can piggyback the ACK on a data packet going in the opposite direction. While this helps improve overall network efficiency, it can also introduce latency in certain interactive, real-time connections, such as Secure Shell (SSH). This is because if the sender is waiting for an ACK before sending more data, and the receiver is holding back the ACK in the hopes of being able to piggyback it, this can introduce an unnecessary delay. Disabling Delayed ACK, similar to disabling Nagle’s Algorithm, could help mitigate this latency and improve the responsiveness of the connection. However, as with Nagle’s Algorithm, the effects of disabling Delayed ACK can vary depending on the specific use case and the network conditions. It could also potentially lead to over-saturation of the network with ACK packets if there’s a lot of traffic. So, it’s advisable to test any changes to these settings carefully and monitor the impact on performance. In some systems, Delayed ACK is disabled on a per-socket basis using the TCP_QUICKACK socket option. |
3. Nagle Algorithm
When using IPv4, sending one single key press across an ssh connection generates TCP/IPv4 packets of about 88 bytes in size (using the encryption and authentication from the example): 20 bytes for the IP header, 20 bytes for the TCP header (assuming no options), and 48 bytes of data.
These small packets (called tinygrams) have a relatively high overhead for the network beacuse they contain relatively little useful application data compared to the rest of the packet contents.
-
Such high-overhead packets are normally not a problem on LANs, because most LANs are not congested and such packets would not need to be carried very far.
-
However, these tinygrams can add to congestion and lead to inefficient use of capacity on wide area networks.
-
A simple and elegant solution was proposed by John Nagle in [RFC0896], now called the Nagle algorithm.
The Nagle algorithm says that when a TCP connection has outstanding data that has not yet been acknowledged, small segments (those smaller than the SMSS) cannot be sent until all outstanding data is acknowledged.
-
Instead, small amounts of data are collected by TCP and sent in a single segment when an acknowledgment arrives.
This procedure effectively forces TCP into stop-and-wait behavior—it stops sending until an ACK is received for any outstanding data.
-
The beauty of this algorithm is that it is self-clocking: the faster the ACKs come back, the faster the data is sent.
On a comparatively high-delay WAN, where reducing the number of tinygrams is desirable, fewer segments are sent per unit time.
Said another way, the RTT controls the packet sending rate.
To illustrate the effect of the Nagle algorithm, we can compare the behaviors of an application using TCP with the Nagle algorithm enabled and disabled.
Using a connection with a relatively large RTT of about 190ms, we can see the differences.
|
Using the |
First, we examine the case with typing a date command when Nagle is disabled (the default for ssh):
00:00:00.000000 IP 192.168.91.1.17203 > 192.168.91.141.22: Flags [P.], seq 3968491625:3968491661, ack 2989677446, win 513, length 36
00:00:00.172405 IP 192.168.91.1.17203 > 192.168.91.141.22: Flags [P.], seq 36:72, ack 1, win 513, length 36
00:00:00.191476 IP 192.168.91.141.22 > 192.168.91.1.17203: Flags [P.], seq 1:37, ack 36, win 501, length 36
00:00:00.234297 IP 192.168.91.1.17203 > 192.168.91.141.22: Flags [.], ack 37, win 513, length 0
00:00:00.364007 IP 192.168.91.141.22 > 192.168.91.1.17203: Flags [P.], seq 37:73, ack 72, win 501, length 36
00:00:00.371952 IP 192.168.91.1.17203 > 192.168.91.141.22: Flags [P.], seq 72:108, ack 73, win 513, length 36
00:00:00.523976 IP 192.168.91.1.17203 > 192.168.91.141.22: Flags [P.], seq 108:144, ack 73, win 513, length 36
00:00:00.562856 IP 192.168.91.141.22 > 192.168.91.1.17203: Flags [P.], seq 73:109, ack 108, win 501, length 36
00:00:00.609221 IP 192.168.91.1.17203 > 192.168.91.141.22: Flags [.], ack 109, win 512, length 0
00:00:00.714586 IP 192.168.91.141.22 > 192.168.91.1.17203: Flags [P.], seq 109:145, ack 144, win 501, length 36
00:00:00.764111 IP 192.168.91.1.17203 > 192.168.91.141.22: Flags [.], ack 145, win 512, length 0
00:00:01.382426 IP 192.168.91.1.17203 > 192.168.91.141.22: Flags [P.], seq 144:180, ack 145, win 512, length 36
00:00:01.576594 IP 192.168.91.141.22 > 192.168.91.1.17203: Flags [P.], seq 145:181, ack 180, win 501, length 36
00:00:01.584727 IP 192.168.91.141.22 > 192.168.91.1.17203: Flags [P.], seq 181:249, ack 180, win 501, length 68
00:00:01.584731 IP 192.168.91.141.22 > 192.168.91.1.17203: Flags [P.], seq 249:285, ack 180, win 501, length 36
00:00:01.584731 IP 192.168.91.141.22 > 192.168.91.1.17203: Flags [P.], seq 285:353, ack 180, win 501, length 68
00:00:01.584995 IP 192.168.91.1.17203 > 192.168.91.141.22: Flags [.], ack 353, win 511, length 0-
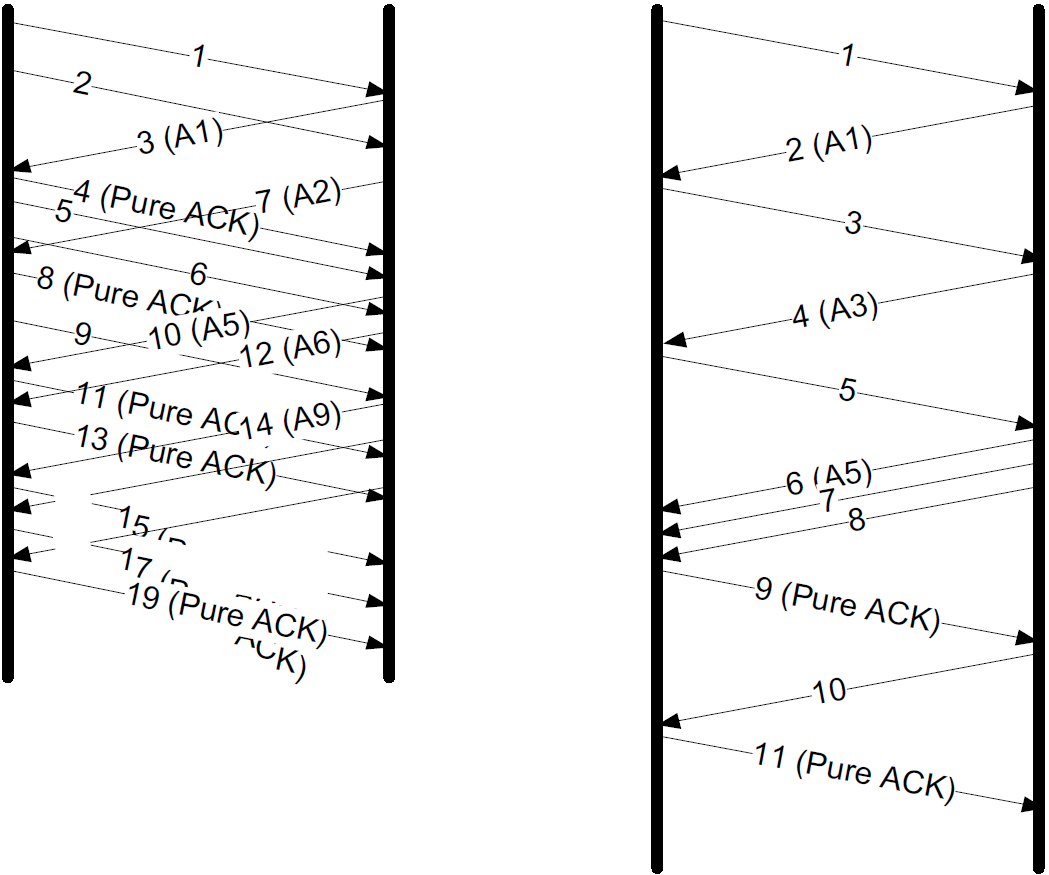
An ssh trace showing a TCP connection with approximately a 190ms RTT.
-
The Nagle algorithm is disabled.
-
Transmissions and ACKs are intermingled, and the exchange takes 1.58s.
-
Pure ACKs (segments with no data) indicate that command output at the server has been processed by the client.
If we repeat this measurement soon after (i.e., in similar network conditions) when Nagle is enabled:
00:00:00.000000 IP 192.168.91.1.17263 > 192.168.91.141.22: Flags [P.], seq 3369922274:3369922310, ack 3162733327, win 513, length 36
00:00:00.191032 IP 192.168.91.141.22 > 192.168.91.1.17263: Flags [P.], seq 1:37, ack 36, win 501, length 36
00:00:00.191425 IP 192.168.91.1.17263 > 192.168.91.141.22: Flags [P.], seq 36:72, ack 37, win 513, length 36
00:00:00.381981 IP 192.168.91.141.22 > 192.168.91.1.17263: Flags [P.], seq 37:73, ack 72, win 501, length 36
00:00:00.382316 IP 192.168.91.1.17263 > 192.168.91.141.22: Flags [P.], seq 72:108, ack 73, win 513, length 36
00:00:00.573124 IP 192.168.91.141.22 > 192.168.91.1.17263: Flags [P.], seq 73:109, ack 108, win 501, length 36
00:00:00.573501 IP 192.168.91.1.17263 > 192.168.91.141.22: Flags [P.], seq 108:144, ack 109, win 512, length 36
00:00:00.763985 IP 192.168.91.141.22 > 192.168.91.1.17263: Flags [P.], seq 109:145, ack 144, win 501, length 36
00:00:00.816253 IP 192.168.91.1.17263 > 192.168.91.141.22: Flags [.], ack 145, win 512, length 0
00:00:01.191218 IP 192.168.91.1.17263 > 192.168.91.141.22: Flags [P.], seq 144:180, ack 145, win 512, length 36
00:00:01.382047 IP 192.168.91.141.22 > 192.168.91.1.17263: Flags [P.], seq 145:181, ack 180, win 501, length 36
00:00:01.383712 IP 192.168.91.141.22 > 192.168.91.1.17263: Flags [P.], seq 181:249, ack 180, win 501, length 68
00:00:01.383716 IP 192.168.91.141.22 > 192.168.91.1.17263: Flags [P.], seq 249:285, ack 180, win 501, length 36
00:00:01.383717 IP 192.168.91.141.22 > 192.168.91.1.17263: Flags [P.], seq 285:353, ack 180, win 501, length 68
00:00:01.384295 IP 192.168.91.1.17263 > 192.168.91.141.22: Flags [.], ack 353, win 511, length 0An ssh trace showing a TCP connection with a 190ms RTT and the Nagle algorithm in operation. Requests are followed in lockstep with responses, and the exchange takes 0.80s using 11 packets.
-
Nagle algorithm forces TCP to operate in a stop-and-wait fashion, so that the TCP sender cannot proceed until ACKs are received.
-
If we look at the times for each request/response pair—0.0, 0.19, 0.19, and 0.38—we see that they follow a pattern; each is separated by almost exactly 190ms, which is very close to the RTT of the connection.
This is the trade-off the Nagle algorithm makes: fewer and larger packets are used, but the required delay is higher.
|
* Nagle’s Algorithm, used in TCP/IP networks, was designed to help prevent network congestion by combining small data packets into larger ones before transmitting them. While this is generally beneficial, it can cause issues in interactive, real-time connections such as Secure Shell (SSH) on Linux systems. This is due to the delay caused by buffering these small packets. Disabling Nagle’s Algorithm can potentially improve responsiveness for such real-time, back-and-forth communications, at the expense of possibly introducing more small packets into the network and increasing network usage. This could be significant in a busy network but may not pose much problem in less-congested ones. On Linux, it’s usually done with the TCP_NODELAY option which can be set on network sockets. It disables the Nagle’s algorithm. In the specific case with Secure Shell (SSH), it should already disable Nagle’s algorithm by default. However, do note that the effects may vary depending upon the specific use case and network conditions, so it’s important to test and monitor performance when making changes to these settings. |
3.1. Delayed ACK and Nagle Algorithm Interaction
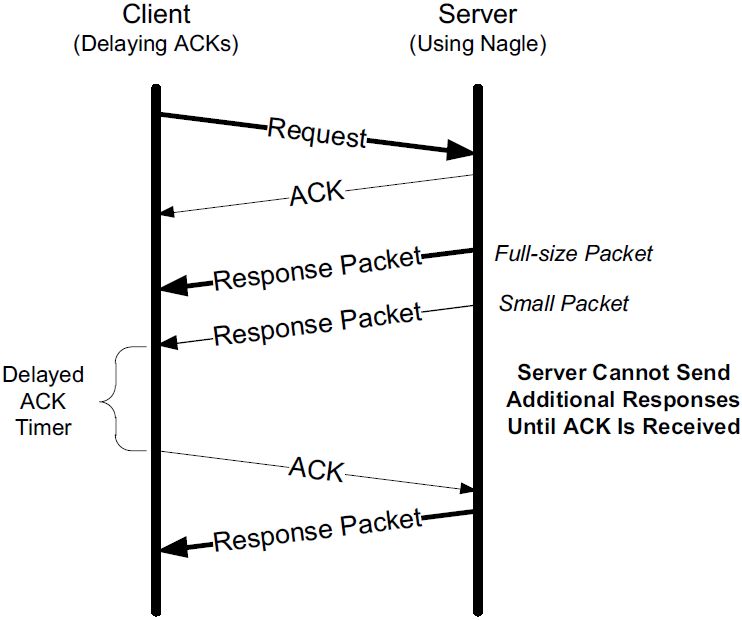
Here we see that the client, after receiving two packets from the server, withholds an ACK, hoping that additional data headed toward the server can be piggybacked.
| Generally, TCP is required to provide an ACK for two received packets only if they are full-size, and they are not here. |
At the server side, because the Nagle algorithm is operating, no additional packets are permitted to be sent to the client until an ACK is returned because at most one small packet is allowed to be outstanding.
The combination of delayed ACKs and the Nagle algorithm leads to a form of deadlock (each side waiting for the other).
Fortunately, this deadlock is not permanent and is broken when the delayed ACK timer fires, which forces the client to provide an ACK even if the client has no additional data to send.
3.2. Disabling the Nagle Algorithm
The Nagle algorithm can be disabled in a number of ways. The ability to disable it is required by the Host Requirements RFC [RFC1122].
An application can specify the TCP_NODELAY option when using the Berkeley sockets API.
TCP(7) Linux Programmer's Manual TCP(7)
NAME
tcp - TCP protocol
.....
TCP_NODELAY
If set, disable the Nagle algorithm. This means that segments
are always sent as soon as possible, even if there is only a
small amount of data. When not set, data is buffered until
there is a sufficient amount to send out, thereby avoiding the
frequent sending of small packets, which results in poor uti‐
lization of the network. This option is overridden by TCP_CORK;
however, setting this option forces an explicit flush of pending
output, even if TCP_CORK is currently set.In addition, it is possible to disable the Nagle algorithm on a system-wide basis.
4. Flow Control and Window Management
Every TCP segment (except those exchanged during connection establishment) includes a valid Sequence Number field, an ACK Number or Acknowledgment field, and a Window Size field (containing the window advertisement).
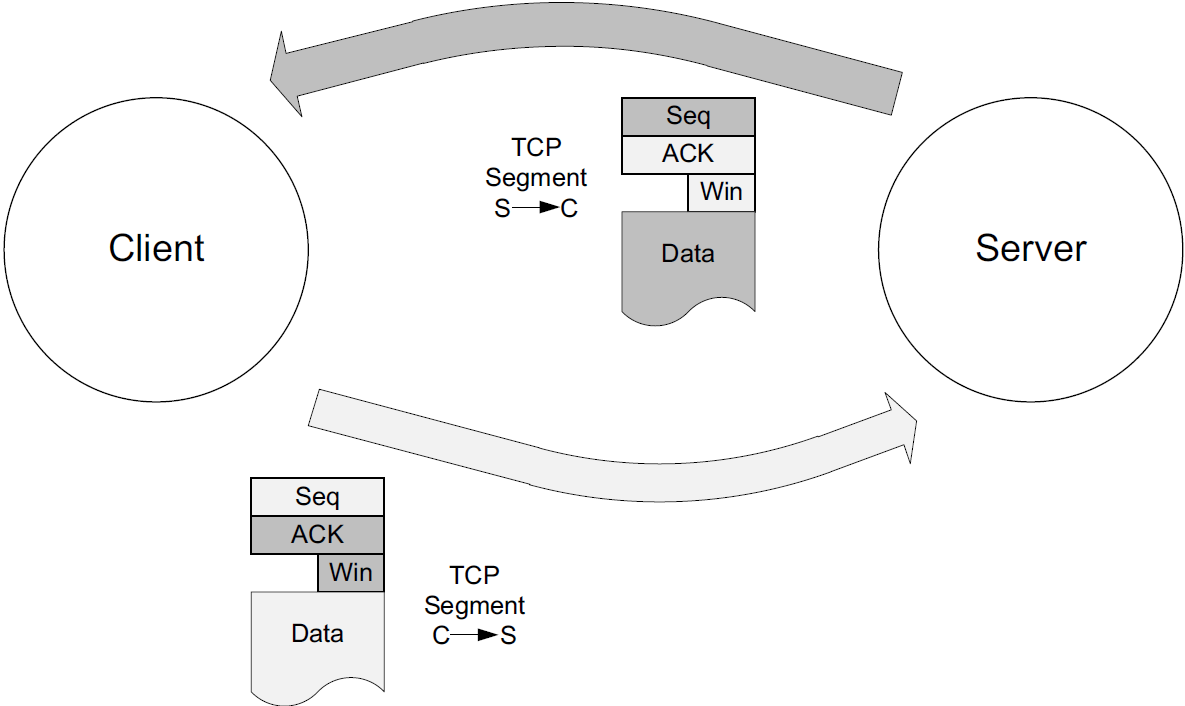
When TCP-based applications are not busy doing other things, they are typically able to consume any and all data TCP has received and queued for them, leading to no change of the Window Size field as the connection progresses.
On slow systems, or when the application has other things to accomplish, data may have arrived for the application, been acknowledged by TCP, and be sitting in a queue waiting for the application to read or consume it.
-
When TCP starts to queue data in this way, the amount of space available to hold new incoming data decreases, and this change is reflected by a decreasing value of the Window Size field.
-
Eventually, if the application does not read or otherwise consume the data at all, TCP must take some action to cause the sender to cease sending new data entirely, because there would be no place to put it on arrival (zero window).
The Window Size field in each TCP header indicates the amount of empty space, in bytes, remaining in the receive buffer.
-
The field is 16 bits in TCP, but with the Window Scale option, values larger than 65,535 can be used.
-
The largest sequence number the sender of a segment is willing to accept in the reverse direction is equal to the sum of the Acknowledgment Number and Window Size fields in the TCP header (scaled appropriately).
Show slow_client.c
/* slow_client.c */
#include <unistd.h>
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#define RCVBUFSIZE 4096
int main(void) {
/* Create a TCP socket */
/* Create a reliable, stream socket using TCP */
int client_sock;
if ((client_sock = socket(PF_INET, SOCK_STREAM, IPPROTO_TCP)) < 0) {
perror("socket() failed");
exit(EXIT_FAILURE);
}
/* Establish connection */
char *serv_ip = "127.0.0.1";
int serv_port = 6666;
struct sockaddr_in serv_addr;
serv_addr.sin_family = AF_INET; /* Internet address family */
serv_addr.sin_addr.s_addr = inet_addr(serv_ip); /* Server IP address*/
serv_addr.sin_port = htons(serv_port); /* Server port */
if (connect(client_sock, (struct sockaddr *) &serv_addr, sizeof(serv_addr)) < 0) {
perror("connect() failed");
exit(EXIT_FAILURE);
}
/* Communicate */
char *read_buf = (char*)malloc(RCVBUFSIZE * sizeof(char));
int recv_msg_size;
for(;;) {
/* Sleep 1s */
sleep(1);
/* Receive mesage from server */
if ((recv_msg_size = recv(client_sock, read_buf, RCVBUFSIZE, 0)) < 0) {
perror("recv() failed");
break;
}
/* EOF */
if (recv_msg_size == 0) {
break;
}
fputs(read_buf, stdout);
memset(read_buf, '\0', RCVBUFSIZE);
}
/* Close the connection */
close(client_sock);
}$ zcat /usr/share/doc/linux-doc/Documentation/networking/ip-sysctl.rst.gz | nc -l --send-only 6666$ cc slow_client.c -o slow_client
$ ./slow_client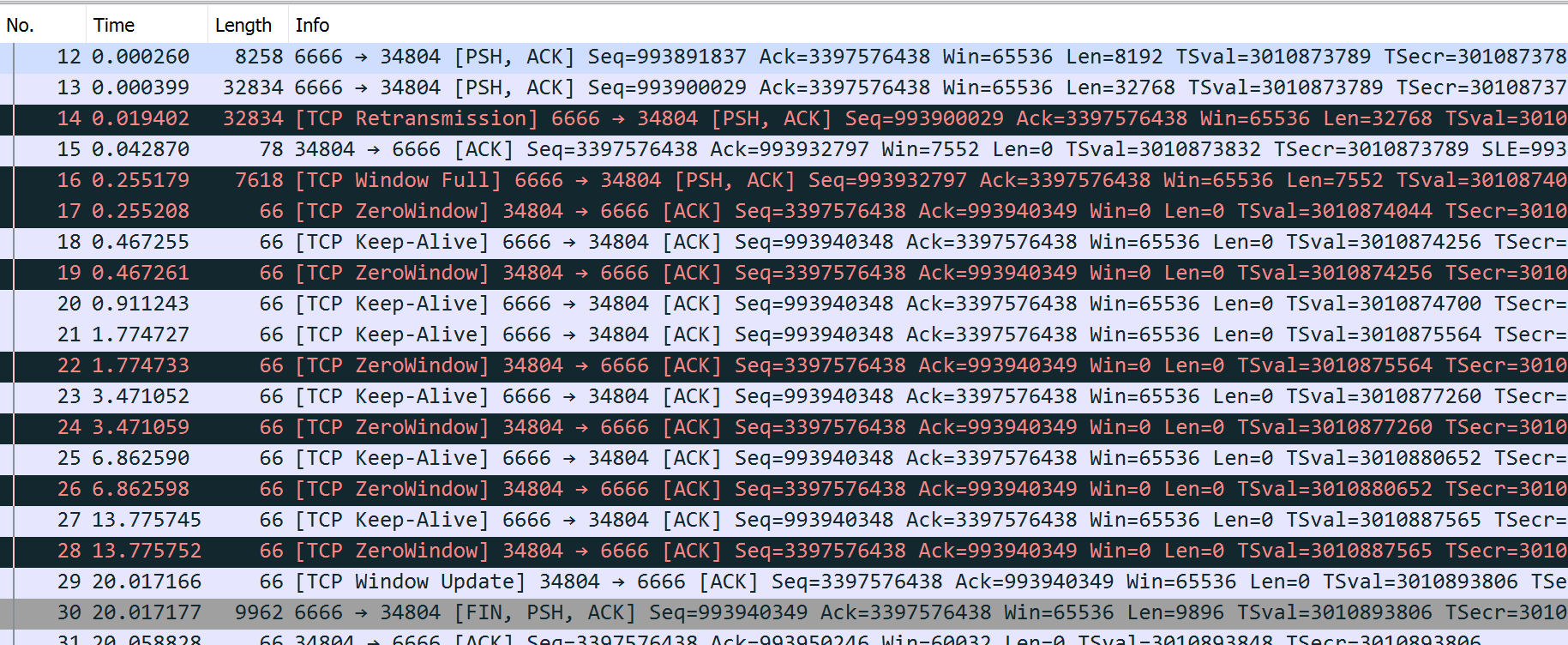
Show tcpdump trace
$ sudo tcpdump -tttttn -i lo port 6666 -n --number -r /tmp/win.pcap
reading from file /tmp/win.pcap, link-type EN10MB (Ethernet), snapshot length 262144
1 00:00:00.000000 IP 127.0.0.1.34804 > 127.0.0.1.6666: Flags [S], seq 3397576437, win 65495, options [mss 65495,sackOK,TS val 3010873789 ecr 0,nop,wscale 7], length 0
2 00:00:00.000010 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [S.], seq 993859068, ack 3397576438, win 65483, options [mss 65495,sackOK,TS val 3010873789 ecr 3010873789,nop,wscale 7], length 0
3 00:00:00.000018 IP 127.0.0.1.34804 > 127.0.0.1.6666: Flags [.], ack 1, win 512, options [nop,nop,TS val 3010873789 ecr 3010873789], length 0
4 00:00:00.000214 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [P.], seq 1:8193, ack 1, win 512, options [nop,nop,TS val 3010873789 ecr 3010873789], length 8192
5 00:00:00.000219 IP 127.0.0.1.34804 > 127.0.0.1.6666: Flags [.], ack 8193, win 475, options [nop,nop,TS val 3010873789 ecr 3010873789], length 0
6 00:00:00.000230 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [P.], seq 8193:16385, ack 1, win 512, options [nop,nop,TS val 3010873789 ecr 3010873789], length 8192
7 00:00:00.000232 IP 127.0.0.1.34804 > 127.0.0.1.6666: Flags [.], ack 16385, win 443, options [nop,nop,TS val 3010873789 ecr 3010873789], length 0
8 00:00:00.000241 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [P.], seq 16385:24577, ack 1, win 512, options [nop,nop,TS val 3010873789 ecr 3010873789], length 8192
9 00:00:00.000242 IP 127.0.0.1.34804 > 127.0.0.1.6666: Flags [.], ack 24577, win 411, options [nop,nop,TS val 3010873789 ecr 3010873789], length 0
10 00:00:00.000249 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [P.], seq 24577:32769, ack 1, win 512, options [nop,nop,TS val 3010873789 ecr 3010873789], length 8192
11 00:00:00.000250 IP 127.0.0.1.34804 > 127.0.0.1.6666: Flags [.], ack 32769, win 379, options [nop,nop,TS val 3010873789 ecr 3010873789], length 0
12 00:00:00.000260 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [P.], seq 32769:40961, ack 1, win 512, options [nop,nop,TS val 3010873789 ecr 3010873789], length 8192
13 00:00:00.000399 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [P.], seq 40961:73729, ack 1, win 512, options [nop,nop,TS val 3010873789 ecr 3010873789], length 32768
14 00:00:00.019402 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [P.], seq 40961:73729, ack 1, win 512, options [nop,nop,TS val 3010873808 ecr 3010873789], length 32768
15 00:00:00.042870 IP 127.0.0.1.34804 > 127.0.0.1.6666: Flags [.], ack 73729, win 59, options [nop,nop,TS val 3010873832 ecr 3010873789,nop,nop,sack 1 {40961:73729}], length 0
16 00:00:00.255179 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [P.], seq 73729:81281, ack 1, win 512, options [nop,nop,TS val 3010874044 ecr 3010873832], length 7552
17 00:00:00.255208 IP 127.0.0.1.34804 > 127.0.0.1.6666: Flags [.], ack 81281, win 0, options [nop,nop,TS val 3010874044 ecr 3010874044], length 0
18 00:00:00.467255 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [.], ack 1, win 512, options [nop,nop,TS val 3010874256 ecr 3010874044], length 0
19 00:00:00.467261 IP 127.0.0.1.34804 > 127.0.0.1.6666: Flags [.], ack 81281, win 0, options [nop,nop,TS val 3010874256 ecr 3010874044], length 0
20 00:00:00.911243 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [.], ack 1, win 512, options [nop,nop,TS val 3010874700 ecr 3010874256], length 0
21 00:00:01.774727 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [.], ack 1, win 512, options [nop,nop,TS val 3010875564 ecr 3010874256], length 0
22 00:00:01.774733 IP 127.0.0.1.34804 > 127.0.0.1.6666: Flags [.], ack 81281, win 0, options [nop,nop,TS val 3010875564 ecr 3010874044], length 0
23 00:00:03.471052 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [.], ack 1, win 512, options [nop,nop,TS val 3010877260 ecr 3010875564], length 0
24 00:00:03.471059 IP 127.0.0.1.34804 > 127.0.0.1.6666: Flags [.], ack 81281, win 0, options [nop,nop,TS val 3010877260 ecr 3010874044], length 0
25 00:00:06.862590 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [.], ack 1, win 512, options [nop,nop,TS val 3010880652 ecr 3010877260], length 0
26 00:00:06.862598 IP 127.0.0.1.34804 > 127.0.0.1.6666: Flags [.], ack 81281, win 0, options [nop,nop,TS val 3010880652 ecr 3010874044], length 0
27 00:00:13.775745 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [.], ack 1, win 512, options [nop,nop,TS val 3010887565 ecr 3010880652], length 0
28 00:00:13.775752 IP 127.0.0.1.34804 > 127.0.0.1.6666: Flags [.], ack 81281, win 0, options [nop,nop,TS val 3010887565 ecr 3010874044], length 0
29 00:00:20.017166 IP 127.0.0.1.34804 > 127.0.0.1.6666: Flags [.], ack 81281, win 512, options [nop,nop,TS val 3010893806 ecr 3010874044], length 0
30 00:00:20.017177 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [FP.], seq 81281:91177, ack 1, win 512, options [nop,nop,TS val 3010893806 ecr 3010893806], length 9896
31 00:00:20.058828 IP 127.0.0.1.34804 > 127.0.0.1.6666: Flags [.], ack 91178, win 469, options [nop,nop,TS val 3010893848 ecr 3010893806], length 0
32 00:00:24.020231 IP 127.0.0.1.34804 > 127.0.0.1.6666: Flags [F.], seq 1, ack 91178, win 512, options [nop,nop,TS val 3010897809 ecr 3010893806], length 0
33 00:00:24.020242 IP 127.0.0.1.6666 > 127.0.0.1.34804: Flags [.], ack 2, win 512, options [nop,nop,TS val 3010897809 ecr 3010897809], length 04.1. Sliding Windows
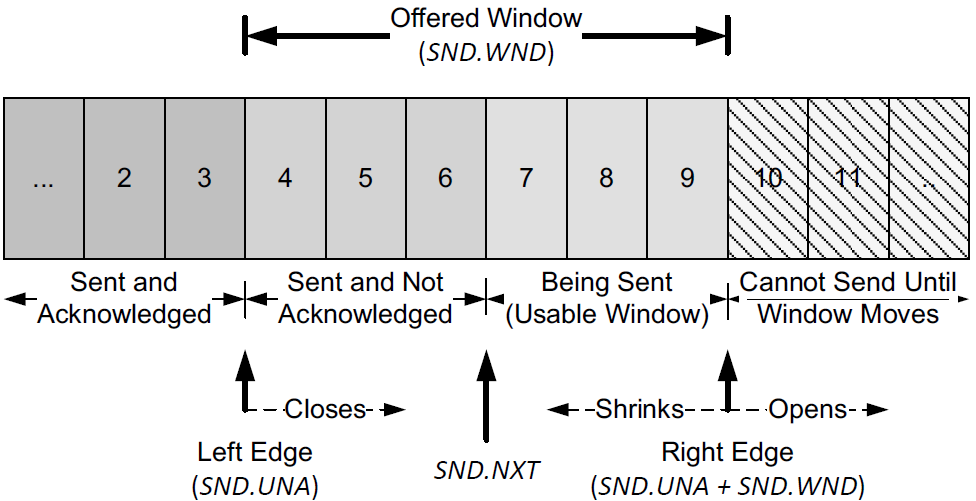
Each endpoint of a TCP connection is capable of sending and receiving data.
The amount of data sent or received on a connection is maintained by a set of window structures.
For each active connection, each TCP endpoint maintains a send window structure and a receive window structure.
-
TCP maintains its window structures in terms of bytes (not packets).
-
The window advertised by the receiver is called the offered window and covers bytes 4 through 9, meaning that the receiver has acknowledged all bytes up through and including number 3 and has advertised a window size of 6.
-
The Window Size field contains a byte offset relative to the ACK number.
-
The sender computes its usable window, which is how much data it can send immediately.
The usable window is the offered window minus the amount of data already sent but not yet acknowledged.
-
The variables SND.UNA and SND.WND are used to hold the values of the left window edge and offered window.
-
The variable SND.NXT holds the next sequence number to be sent, so the usable window is equal to (SND.UNA + SND.WND – SND.NXT).
Over time this sliding window moves to the right, as the receiver acknowledges data. The relative motion of the two ends of the window increases or decreases the size of the window. Three terms are used to describe the movement of the right and left edges of the window:
-
The window closes as the left edge advances to the right. This happens when data that has been sent is acknowledged and the window size gets smaller.
-
The window opens when the right edge moves to the right, allowing more data to be sent. This happens when the receiving process on the other end reads acknowledged data, freeing up space in its TCP receive buffer.
-
The window shrinks when the right edge moves to the left. The Host Requirements RFC [RFC1122] strongly discourages this, but TCP must be able to cope with it.
Because every TCP segment contains both an ACK number and a window advertisement, a TCP sender adjusts the window structure based on both values whenever an incoming segment arrives.
-
The left edge of the window cannot move to the left, because this edge is controlled by the ACK number received from the other end that is cumulative and never goes backward.
-
When the ACK number advances the window but the window size does not change (a common case), the window is said to advance or slide forward.
-
If the ACK number advances but the window advertisement grows smaller with other arriving ACKs, the left edge of the window moves closer to the right edge.
-
If the left edge reaches the right edge, it is called a zero window.
This stops the sender from transmitting any data.
If this happens, the sending TCP begins to probe the peer’s window to look for an increase in the offered window.
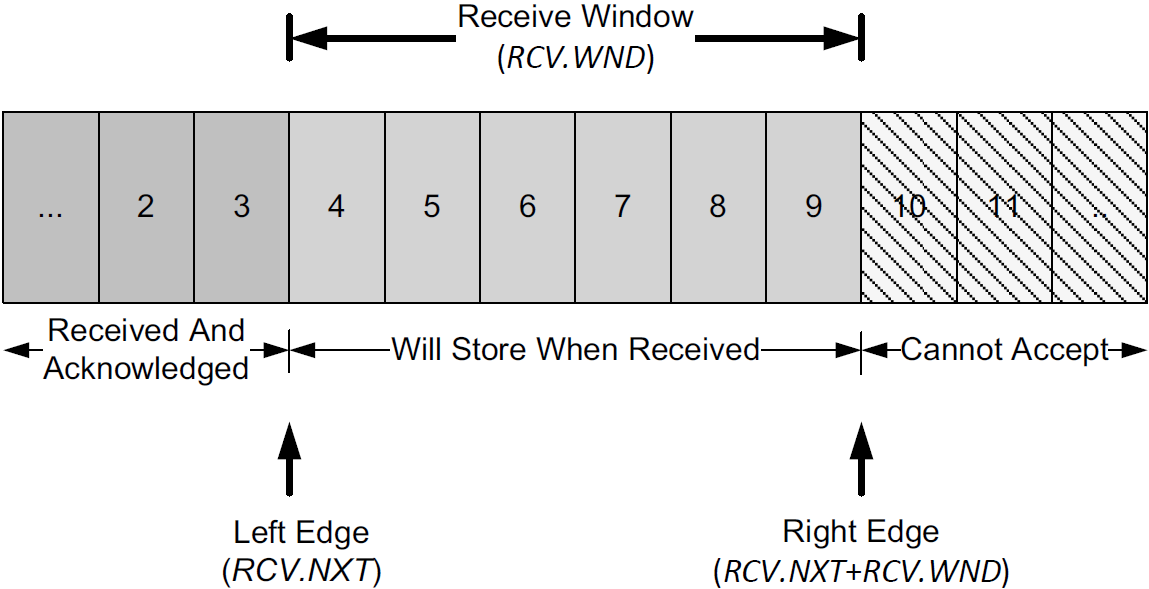
The receiver also keeps a window structure, which is somewhat simpler than the sender’s.
-
The receiver window structure keeps track of what data has already been received and ACKed, as well as the maximum sequence number it is willing to receive.
-
The TCP receiver depends on this structure to ensure the correctness of the data it receives.
In particular, it wishes to avoid storing duplicate bytes it has already received and ACKed, and it also wishes to avoid storing bytes that it should not have received (any bytes beyond the sender’s right window edge).
-
This structure also contains a left and right window edge like the sender’s window, but the in-window bytes (4–9 in this picture) need not be differentiated as they are in the sender’s window structure.
-
For the receiver,
-
any bytes received with sequence numbers less than the left window edge (called RCV.NXT) are discarded as duplicates, and
-
any bytes received with sequence numbers beyond the right window edge (RCV.WND bytes beyond RCV.NXT) are discarded as out of scope.
-
-
Bytes arriving with any sequence number in the receive window range are accepted.
-
Note that the ACK number generated at the receiver may be advanced only when segments fill in directly at the left window edge because of TCP’s cumulative ACK structure.
-
With selective ACKs, other in-window segments can be acknowledged using the TCP SACK option, but ultimately the ACK number itself is advanced only when data contiguous to the left window edge is received.
4.2. Zero Windows and the TCP Persist Timer
When the receiver’s advertised window goes to zero, the sender is effectively stopped from transmitting data until the window becomes nonzero.
When the receiver once again has space available, it provides a window update to the sender to indicate that data is permitted to flow once again.
-
Because such updates do not generally contain data (they are a form of pure ACK), they are not reliably delivered by TCP.
-
TCP must therefore handle the case where such window updates that would open the window are lost.
-
If an acknowledgment (containing a window update) is lost, we could end up with both sides waiting for the other:
-
the receiver waiting to receive data (because it provided the sender with a nonzero window and expects to see incoming data) and
-
the sender waiting to receive the window update allowing it to send.
-
-
To prevent this form of deadlock from occurring, the sender uses a persist timer to query the receiver periodically, to find out if the window size has increased. The persist timer triggers the transmission of window probes.
Window probes are segments that force the receiver to provide an ACK, which also necessarily contains a Window Size field.
-
The Host Requirements RFC [RFC1122] suggests that the first probe should happen after one RTO and subsequent problems should occur at exponentially spaced intervals.
-
Window probes contain a single byte of data and are therefore reliably delivered (retransmitted) by TCP if lost, thereby eliminating the potential deadlock condition caused by lost window updates.
-
The probes are sent whenever the TCP persist timer expires, and the byte included may or may not be accepted by the receiver, depending on how much buffer space it has available.
-
As with the TCP retransmission timer, the normal exponential backoff can be used when calculating the timeout for the persist timer. An important difference, however, is that a normal TCP never gives up sending window probes, whereas it may eventually give up trying to perform retransmissions.
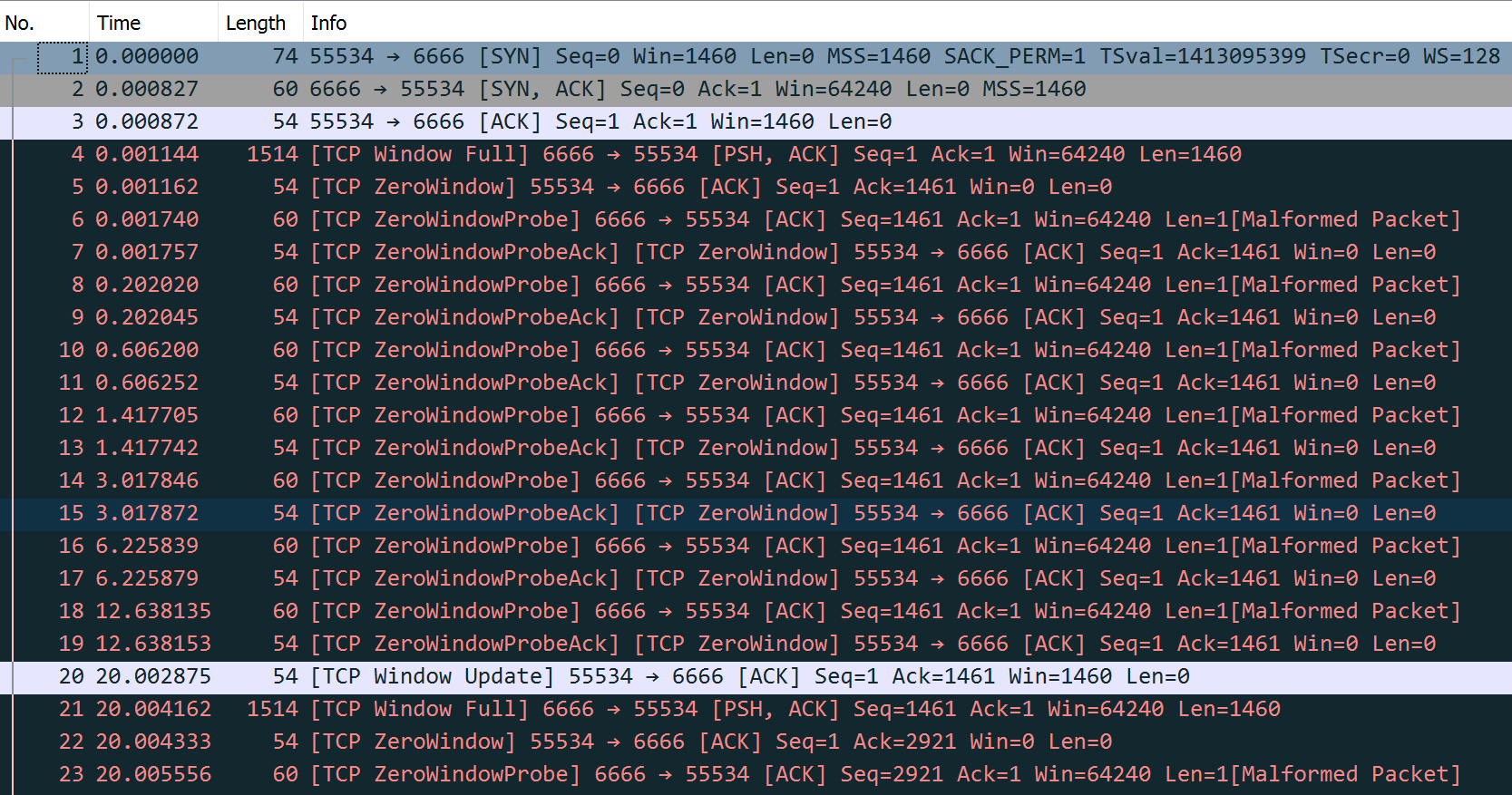
Show tcpdump trace
00:00:00.000000 IP 192.168.91.128.55534 > 10.170.109.10.6666: Flags [S], seq 1303159618, win 1460, options [mss 1460,sackOK,TS val 1413095399 ecr 0,nop,wscale 7], length 0
00:00:00.000827 IP 10.170.109.10.6666 > 192.168.91.128.55534: Flags [S.], seq 102306775, ack 1303159619, win 64240, options [mss 1460], length 0
00:00:00.000872 IP 192.168.91.128.55534 > 10.170.109.10.6666: Flags [.], ack 1, win 1460, length 0
00:00:00.001144 IP 10.170.109.10.6666 > 192.168.91.128.55534: Flags [P.], seq 1:1461, ack 1, win 64240, length 1460
00:00:00.001162 IP 192.168.91.128.55534 > 10.170.109.10.6666: Flags [.], ack 1461, win 0, length 0
00:00:00.001740 IP 10.170.109.10.6666 > 192.168.91.128.55534: Flags [.], seq 1461:1462, ack 1, win 64240, length 1
00:00:00.001757 IP 192.168.91.128.55534 > 10.170.109.10.6666: Flags [.], ack 1461, win 0, length 0
00:00:00.202020 IP 10.170.109.10.6666 > 192.168.91.128.55534: Flags [.], seq 1461:1462, ack 1, win 64240, length 1
00:00:00.202045 IP 192.168.91.128.55534 > 10.170.109.10.6666: Flags [.], ack 1461, win 0, length 0
00:00:00.606200 IP 10.170.109.10.6666 > 192.168.91.128.55534: Flags [.], seq 1461:1462, ack 1, win 64240, length 1
00:00:00.606252 IP 192.168.91.128.55534 > 10.170.109.10.6666: Flags [.], ack 1461, win 0, length 0
00:00:01.417705 IP 10.170.109.10.6666 > 192.168.91.128.55534: Flags [.], seq 1461:1462, ack 1, win 64240, length 1
00:00:01.417742 IP 192.168.91.128.55534 > 10.170.109.10.6666: Flags [.], ack 1461, win 0, length 0
00:00:03.017846 IP 10.170.109.10.6666 > 192.168.91.128.55534: Flags [.], seq 1461:1462, ack 1, win 64240, length 1
00:00:03.017872 IP 192.168.91.128.55534 > 10.170.109.10.6666: Flags [.], ack 1461, win 0, length 0
00:00:06.225839 IP 10.170.109.10.6666 > 192.168.91.128.55534: Flags [.], seq 1461:1462, ack 1, win 64240, length 1
00:00:06.225879 IP 192.168.91.128.55534 > 10.170.109.10.6666: Flags [.], ack 1461, win 0, length 0
00:00:12.638135 IP 10.170.109.10.6666 > 192.168.91.128.55534: Flags [.], seq 1461:1462, ack 1, win 64240, length 1
00:00:12.638153 IP 192.168.91.128.55534 > 10.170.109.10.6666: Flags [.], ack 1461, win 0, length 0
00:00:20.002875 IP 192.168.91.128.55534 > 10.170.109.10.6666: Flags [.], ack 1461, win 1460, length 0
.....4.3. Silly Window Syndrome (SWS)
Window-based flow control schemes, especially those that do not use fixed-size segments (such as TCP), can fall victim to a condition known as the silly window syndrome (SWS).
-
When it occurs, small data segments are exchanged across the connection instead of full-size segments [RFC0813].
-
This leads to undesirable inefficiency because each segment has relatively high overhead—a small number of data bytes relative to the number of bytes in the headers.
SWS can be caused by either end of a TCP connection:
-
the receiver can advertise small windows (instead of waiting until a larger window can be advertised), and
-
the sender can transmit small data segments (instead of waiting for additional data to send a larger segment).
Correct avoidance of silly window syndrome requires a TCP to implement rules specifically for this purpose, whether operating as a sender or a receiver. TCP never knows ahead of time how a peer TCP will behave. The following rules are applied:
-
When operating as a receiver, small windows are not advertised.
The receive algorithm specified by [RFC1122] is to not send a segment advertising a larger window than is currently being advertised (which can be 0) until the window can be increased by either one full-size segment (i.e., the receive MSS) or by one-half of the receiver’s buffer space, whichever is smaller.
Note that there are two cases where this rule can come into play: when buffer space has become available because of an application consuming data from the network, and when TCP must respond to a window probe.
-
When sending, small segments are not sent and the Nagle algorithm governs when to send.
Senders avoid SWS by not transmitting a segment unless at least one of the following conditions is true:
-
A full-size (send MSS bytes) segment can be sent.
Condition (a) is the most straightforward and directly avoids the high-overhead segment problem.
-
TCP can send at least one-half of the maximum-size window that the other end has ever advertised on this connection.
Condition (b) deals with hosts that always advertise tiny windows, perhaps smaller than the segment size.
-
TCP can send everything it has to send and either (i) an ACK is not currently expected (i.e., we have no outstanding unacknowledged data) or (ii) the Nagle algorithm is disabled for this connection.
Condition (c) prevents TCP from sending small segments when there is unacknowledged data waiting to be ACKed and the Nagle algorithm is enabled. If the sending application is doing small writes (e.g., smaller than the segment size), condition (c) avoids silly window syndrome.
-
4.4. Large Buffers and Auto-Tuning
Many TCP stacks now decouple the allocation of the receive buffer from the size specified by the application.
In most cases, the size specified by the application is effectively ignored, and the operating system instead uses either a large fixed value or a dynamically calculated value.
With auto-tuning, the amount of data that can be outstanding in the connection (its bandwidth-delay product) is continuously estimated, and the advertised window is arranged to always be at least this large (provided enough buffer space remains to do so).
This has the advantage of allowing TCP to achieve its maximum available throughput rate (subject to the available network capacity) without having to allocate excessively large buffers at the sender or receiver ahead of time.
In Windows (Vista/7) , the receiver’s buffer size is auto-sized by the operating system by default.
With Linux 2.4 and later, sender-side auto-tuning is supported. With version 2.6.7 and later, both receiver- and sender-side auto-tuning is supported. However, auto-tuning is subject to limits placed on the buffer sizes.
The following Linux sysctl variables control the sender and receiver maximum buffer sizes.
-
The values after the equal sign are the default values (which may vary depending on the particular Linux distribution), which should be increased if the system is to be used in high bandwidth-delay-product environments:
net.core.rmem_default = 212992 net.core.wmem_default = 212992 net.core.rmem_max = 212992 net.core.wmem_max = 212992 -
In addition, the auto-tuning parameters are given by the following variables:
net.ipv4.tcp_rmem = 4096 131072 6291456 net.ipv4.tcp_wmem = 4096 16384 4194304Each of these variables contains three values: the minimum, default, and maximum buffer size used by auto-tuning.
$ sudo tcpdump -n "dst port 6666 and tcp[14:2] > 0" 19:00:52.774633 IP 192.168.91.128.56256 > 10.170.109.10.6666: Flags [S], seq 4259244136, win 2920, options [mss 1460,sackOK,TS val 1089797899 ecr 0,nop,wscale 7], length 0 19:00:52.775403 IP 192.168.91.128.56256 > 10.170.109.10.6666: Flags [.], ack 1713968064, win 2920, length 0 19:00:52.911851 IP 192.168.91.128.56256 > 10.170.109.10.6666: Flags [.], ack 2921, win 1460, length 0 19:00:54.776998 IP 192.168.91.128.56256 > 10.170.109.10.6666: Flags [.], ack 4381, win 2920, length 0 19:00:54.777424 IP 192.168.91.128.56256 > 10.170.109.10.6666: Flags [.], ack 7301, win 1460, length 0 19:00:56.777414 IP 192.168.91.128.56256 > 10.170.109.10.6666: Flags [.], ack 8761, win 2920, length 0 19:00:56.777741 IP 192.168.91.128.56256 > 10.170.109.10.6666: Flags [.], ack 11681, win 8760, length 0 19:00:56.778085 IP 192.168.91.128.56256 > 10.170.109.10.6666: Flags [.], ack 20441, win 26280, length 0 19:00:56.778334 IP 192.168.91.128.56256 > 10.170.109.10.6666: Flags [.], ack 46721, win 65535, length 0 .....
5. Urgent Mechanism
An application is able to mark data as urgent by specifying a special option to the Berkeley sockets API (MSG_OOB) when it performs a write operation, although the use of urgent data is no longer recommended [RFC6093].
References
-
[TCPIPV1] Kevin Fall, W. Stevens TCP/IP Illustrated: The Protocols, Volume 1. 2nd edition, Addison-Wesley Professional, 2011
-
[RFC0813] D. Clark, Window and Acknowledgment Strategy in TCP, Internet RFC 0813, July 1982.
-
[RFC0896] J. Nagle, Congestion Control in IP/TCP Internetworks, Internet RFC 0896, Jan. 1984. See https://www.rfc-editor.org/rfc/rfc896
-
[RFC1112] S. E. Deering, Host Extensions for IP Multicasting, Internet RFC 1112/STD 0005, Aug. 1989.
-
[RHELDELACK] Reducing the TCP Delayed ACK Timeout [online]. https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux_for_real_time/7/html/tuning_guide/reducing_the_tcp_delayed_ack_timeout
-
[WTCP] https://en.wikipedia.org/wiki/Transmission_Control_Protocol
-
[WSCALE] https://en.wikipedia.org/wiki/TCP_window_scale_option